 Skip to main content
Skip to main content

Contrary to popular opinion, software testing exists not only to detect bugs. Its major goal is to provide information on the performance of the tested solution. This information helps the development team better understand the behavior of their product and improve its quality.
The result of testing strongly depends on the methods and tools used and on the skills of the testers. That’s why it’s important to look for new ways to improve testing while keeping in mind time-proven approaches.
At Apriorit, we’ve tried out lots of approaches to get the most out of testing activities while keeping them fast and flexible. In this article, we share six ideas to improve the testing process. This post will be useful for test managers and quality assurance engineers who are looking for proven methods to improve the software testing process.
Contents:
- 6 reasons to reconsider your testing strategy
- Method 1. Automate regression testing
- Method 2. Employ cloud-based services
- Method 3. Establish clear team communication
- Method 4. Apply standard approaches and methodologies
- Method 5. Use test management tools
- Method 6. Conduct exploratory and ad hoc testing
- Conclusion
6 reasons to reconsider your testing strategy
Each tester has a favorite type of testing, a favorite set of tools, or methodology they would like to use for every project. If it were possible to always go with these preferences, the life of a tester would be so much easier! But in the real world, each project requires a unique approach, and that calls for continuously improving the testing strategy.
Here are the key benefits of such improvement:
- Increased test efficiency and release of a bug-free product
- Reduced time to market
- More accurate test plans
- Cost-saving procedures
- Decreased cost of failure during all stages of development
- Increased knowledge on the part of the testing team

Over the years, we’ve worked out six proven methods to deliver high-quality testing services. We asked our testing experts to share their thoughts on using these methods in practice.
Method 1. Automate regression testing
Automating regression tests is one of the seven key factors for successful Agile testing described in Agile Testing: A Practical Guide for Testers and Agile Teams by Lisa Crispin. The benefits of test automation are obvious: instead of running test cases manually, a tester can automate this process with dedicated software and devote their time to active testing of features planned for release.
There’s a trick to improving the test automation process: draw up a test implementation plan when planning the testing strategy because automation has an impact on project estimates and the budget.
That’s why in our projects, we include as many automated tests as possible at the planning stage and allocate resources for running them. Particularly, we try to cover basic and critical functionalities with autotests. If we work on a long-term project that includes a lot of regression tests, we automate both regression and acceptance tests.

Artyom Grygorenko, QA Lead, Network Testing Team:
— During one of our projects, we decided to automate as many manual tests as possible. We implemented a continuous integration and continuous delivery (CI/CD) system and automated acceptance tests. Our goal was to ensure that the product could be delivered right after the build. At the same time, we weren’t particularly interested in low-priority test cases that weren’t included in the acceptance checklist.
With help from developers, our team created an automated pipeline using top QA automation tools and ran all the test cases through automated acceptance tests.
The difference in automated verification between regression and acceptance tests lies in their checklists: the acceptance checklist is much smaller and takes less time to automate and support. At the same time, with this approach, we are sure that the key functionalities of the solution work properly and there’s little to no chance of discovering a bug.
Method 2. Employ cloud-based services
The key benefits of cloud testing are the possibilities to lower the project cost and speed up the testing. At Apriorit, we use Amazon Web Services (AWS) to improve load testing.
We often develop distributed systems that support tens of thousands of endpoints in large organizations. Therefore, we need lots of endpoints to conduct load tests of these solutions. We’ve encountered two major issues during this type of testing:
- Endpoints have to be available at a certain point in time.
- Purchasing a required number of endpoints just for testing is quite costly.
We’ve mitigated both these issues by implementing AWS solutions. Now we can create a virtual environment and rent the required resources only for the time we need to run tests. We also prefer to use cloud-based tools for other activities. For example, we often use BrowserStack for mobile testing.

Egor Menkov, Senior Tester, Network Testing Team:
— We needed to test the performance of a high-load enterprise solution that collects and analyzes agent data. Before AWS, we used to spend up to 10 developer-hours manually preparing the environment. And since it consisted of our employees’ endpoints, we could run load tests only over the weekends.
The use of cloud-based resources allows us to:
- set up the same environment in 10 minutes
- increase the load during testing
- automate most manual and routine tasks
- run tests any time we need to
- speed up the cycle of finding, fixing, and validating bugs.
Method 3. Establish clear team communication
Improving team communication is one of the most discussed ways to improve the software testing process. At Apriorit, we pay attention to
- establishing high-quality communication in each project
- detecting and getting rid of information gaps inside the team
- making roles and goals clear to each team member.
These steps might seem obvious, but from our experience, establishing a clear dialog among all members of the team helps to speed up product delivery.
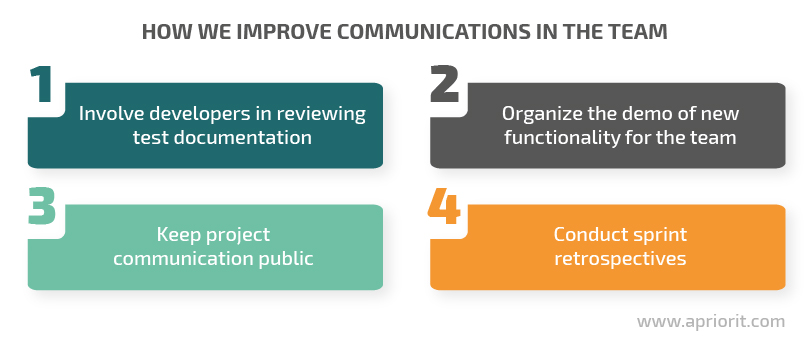
For example, as developers have a better understanding of feature implementation, we involve them in reviewing test documentation. Moreover, developers approach the documentation review from a different angle than testers. As a result, our testers create more test cases, which helps us catch and fix more unobvious bugs.
We also conduct a product demo for the team before showing the demo to the client. It doesn’t take much time but allows us to bring new team members up to speed and create a shared understanding of a new feature.
In addition to keeping project communications available for all team members, we conduct project retrospectives. This is an essential part of Agile development and involves the whole team. A retrospective meeting sums up the results of the last sprint and allows the team to define and discuss testing and QA issues and come up with new ways to solve them.

Igor Zhurko, Test Engineer, Network Testing Team:
— Once new functionality is ready, developers set up a conference call with the entire project team. During this call, they show the demo, explain several use cases for the new feature, and answer the team’s questions. Developers also upload the demo to the Confluence space that already contains specifications, the technical solution, and the development checklist for the new feature.
This demo helps testers write test cases for complex features that are hard to fully understand solely from the documentation. In addition, any team member can always rewatch the demo to refresh their memory when needed.
We also use Confluence to discuss feature specifications. This way, everyone has access to specifications, can add a remark, and can go through old comments.
Method 4. Apply standard approaches and methodologies
Lots of testing teams try to organize their work in a unique way. For example, we have our own web application penetration testing methodology. But we believe it’s best to research industry-recognized testing approaches before creating your own. There are lots of test process models and formal improvement methods, the most popular being:
- Capability Maturity Model Integration
- Testing Maturity Model
- Critical Testing Processes
- Systematic Test and Evaluation Process
- IDEAL Model
- Test Process Improvement
You can find out more about standard testing models in the ISTQB Advanced Level Test Manager Syllabus (see Chapter 5, “Improving the testing process”).
At Apriorit, we use the Systematic Test and Evaluation Process, or STEP, to avoid formalizing test cases and change the scope of testing according to business needs. We also apply the Test Process Improvement (TPI Next) approach.

Dmitrij Karnaukh, Senior Tester and Test Manager, Driver Testing Team:
— After implementing TPI Next, we evaluated the project and faced a lack of metrics and automated tests. When we gathered data for the required metrics, we discovered that regression bugs and client-side bugs were the project’s key issues. By now, we have improved the development testing process, started conducting alpha testing more often, and written more automated tests. Each project roadmap includes additional tasks for developing and improving autotests.
TPI has helped us to:
- regulate development in the trunk branch
- decrease the ratio of customer defects from ~20% to ~5%
- increase unit test coverage to 49%
- reduce the number of bugs discovered in one 8- to 10-week release from ~100 to ~70.
Check out our another article to learn how to define metrics in software testing.
Method 5. Use test management tools
Effective test management is the key to successful QA process improvements. The ultimate goal of test management is to create a controllable, predictable, yet flexible test process that can fit any project. Test managers’ responsibilities usually include:
- planning and estimating tests
- executing and controlling tests
- tracking tests
- reporting on tests
- managing the testing team.
It’s possible to carry out all these activities manually, but using dedicated tools greatly speeds up the process. We believe it’s reasonable to implement a management tool if the testing team consists of three or more QA engineers. However, smaller teams can also benefit from automated test management.
The most popular automated testing tools are TestRail, Jazz, and Zephyr (a Jira plugin). In our projects, we prefer using TestRail.

Ihor Dovbnia, Test Engineer, Software Testing Team:
— Maintaining the documentation for a big project is always a challenge. In our projects, we’ve used various methods of test management, from storing test documentation and plans in Google Docs to using dedicated software. Using TestRail allowed us to make the testing process more controllable. This tool simplified maintaining documentation, working with testing history, and creating test plans. Also, storing test-related materials in TestRail is more secure than in Google Docs. As a result, we improved overall testing performance in our projects.
Method 6. Conduct exploratory and ad hoc testing
Test documentation, however thorough, can’t cover all the nuances of software behavior, interactions with an operating system, network, and cloud services, etc. Therefore, testers can’t detect all bugs if they strictly follow the documentation. Exploratory and ad hoc testing helps to deal with this issue.
Exploratory testing is focused on minimizing test plans and documentation and maximizing test coverage. With this approach, testers create a basic test plan, execute it, and use the information they acquire, their experience, and creativity to conduct additional tests. Exploratory testing is faster than scripted testing, detects unusual and unobvious bugs, and provides testers with the opportunity to expand their expertise. On the other hand, conducting tests with no test cases or documentation makes it hard to recreate conditions of bug discovery.
Common use cases for exploratory testing are:
- studying a product with incomplete, legacy, or lost documentation
- detecting and patching flaws in the original test plan
- researching a defect detected during planned testing activities
- testing software behavior under strict time limitations.
Ad hoc testing is the least formal type of testing based on the error guessing technique. Ad hoc testing is conducted after a team finishes all tests within the project scope. Ad hoc tests are unplanned, undocumented, and somewhat random tests that are conducted based on testers’ creativity, skills, and knowledge of the tested software. This spontaneous approach provides ad hoc testing with its key benefit: speed. Testers don’t spend time writing test cases — they just go ahead with their tests. But the key drawback of ad hoc testing also derives from that speed: test results are unpredictable. Because of that, ad hoc testing has to be paired with formal testing.
Ad hoc testing has three goals:
- Simulate unusual user behavior
- Detect hard-to-find and hard-to-reproduce defects
- Improve or validate the results of formal testing


Sergei Zubkov, QA Lead, Software Testing Team:
— Exploratory and ad hoc testing help to detect hidden bugs which were missed because of the pesticide effect and incomplete test documentation. When testers conduct test sessions with no documentation, they have an opportunity to generate and validate a rare test case or a combination of conditions. Bugs discovered during exploratory and ad hoc testing become the basis for new test cases. Such types of testing also help to investigate if the functionality behaves like it’s supposed to and augment the project documentation. These testing approaches are exceptionally useful in rapidly evolving projects at the feature integration stage.
At Apriorit, we add exploratory and ad hoc sessions to the test plan, estimating the duration of those sessions based on project complexity and desired test coverage. To get the best results possible, we assign the most experienced testers with a deep understanding of the tested solution and business needs to conduct these tests.
Conclusion
There’s no one-size-fits-all approach to software testing — testing methods and toolsets depend heavily on the project’s goal, size, and budget as well as on the test engineer’s skills. A professional test manager not only creates a unique workflow for each project but is constantly looking for ways to improve testing efficiency. We believe the testing process follows the pesticide paradox described by Boris Beizer in his book Software Testing Techniques (1990): the more you test software with the same methods, the more immune it becomes to your tests.
Now you know how to improve the testing process with six practices tried and tested by Apriorit software testing experts. Try to implement them in your project or contact us for more useful advice. Our experienced QA and testing teams are ready to help!


