 Skip to main content
Skip to main content


Software products are like puzzles: full of dependencies. Every detail is connected to others, and if you change one component, others may no longer fit together.
These interdependencies play a crucial role when making changes to a software product and testing it afterwards. To ensure that your product remains stable, secure, and well-performing after every update, you need to test not only the changed feature itself but all components influenced by the changes.
In this article, we discuss different approaches to impact analysis in the software development process with examples, determine who’s responsible for what in this process, and outline the main risks of not performing such an analysis. We also provide easy-to-use templates for analyzing the impact of dependencies in projects of different sizes.
This article will be useful for developers and QA specialists who need to understand how changes in one component of a product influence other components.
Contents:
Basics of impact analysis in software testing
Software development is a continuous process wherein we constantly improve existing functionality or add new features. However, every change introduced to a product might have an impact on a particular part of the product or even on the entire product. And the more changes we make to a product, the more difficult it becomes to track their consequences.
As a result, simply testing your updated product in accordance with industry best practices might not be enough to ensure its proper security and flawless performance. Some parts of code might require double-checking, deeper analysis, or a different testing approach. And the best way to distinguish these parts of your product is by running a thorough impact analysis.
Impact analysis is a software testing approach that helps you define all risks associated with any kind of changes made to the product under test.
It’s best to perform an impact analysis whenever:
- there’s a request for a change to the product
- there are changes in product requirements
- there are changes to current modules or features
- you plan to implement new modules or features
While this process may increase the total cost of product development, the added expenses are easily justified. Based on the results of an impact analysis, you’ll be able to answer the following questions:
- What software modules and functionalities will be affected by a particular change (and how exactly)?
- Will this implementation affect the performance of the application or individual application modules?
- Will the implementation of this module or function affect product versions for different platforms?
- Will the implementation of this module or function affect the application’s performance on different operating systems and browsers?
- What new test cases should you create to cover a new module or feature and its relationship with existing elements?
- How will this change influence the testing process in general and what extra tools and skills might you need?
- How will changes affect the product’s terms and budget?
Before you start any analysis activities, let’s determine what to focus on.
What is impact analysis in testing? There are three types of impact analysis that focus on different aspects of this process and aim for different goals:

- Dependency impact analysis focuses on detecting dependencies: potential consequences of changes or parts of the product that must be reworked when implementing these changes.
- Experiential impact analysis aims to estimate the risks associated with product changes in terms of the whole development process, including the need for extra time and resources for development.
- Traceability impact analysis, according to the definition by ISTQB Glossary, assesses what must be changed at different documentation levels in order to implement a particular change to the product.
In this article, we share our experience applying the first of these three approaches — dependency impact analysis. Next, we discuss practical examples of using dependency impact analysis in software engineering and testing.
Need help ensuring quality for complex software?
No matter how many dependencies your solution has, Apriorit expert developers and QA engineers will make sure it performs as intended.
Analyzing dependency impact in practice
Project size matters
There are a couple ways you can work with dependency impact analysis: using dedicated tools and services or simply by gathering analysis results in a table. At Apriorit, we maintain a separate impact analysis document for each project.
As a rule, such documents contain full lists of all product features, modules, and functionalities. They are maintained by developers, QA experts, and other project participants.
Here’s how it works: If a change is made to the product, developers mark in the project’s table the corresponding features, modules, and functionality that either were or could possibly be influenced by this change. Only after doing this do they send the modified product for testing.
We also use templates for analyzing products of different complexities. The simpler the project, the simpler its dependency impact analysis documentation.
Below, we describe in detail practical examples of impact analysis for testing software in small and large-scale projects. We also provide templates you can use for analyzing your product and explain how we work with them.
Dependency impact analysis template for small projects
Imagine you have a small project with a limited number of features. In this case, your dependency impact analysis table will look something like this:
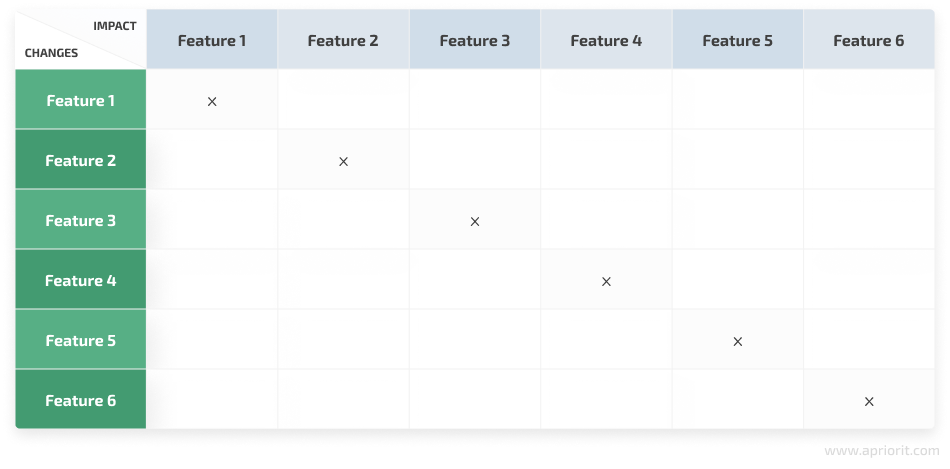
Figure 1. Dependency impact analysis for a small project
As you can see, our template is a matrix. All features, modules, and functionalities that can be singled out in this product (installation, uninstallation, updating, hot keys, menu, toolbar, hints, options, etc.) are enumerated horizontally and vertically.
In the left-hand column, we define the features that have been changed. In the top row, we define the features that can be influenced by the introduced changes. As any change to a feature inevitably influences the feature itself, we mark these dependencies in the table right away.
This table can also be used as a checklist for developers to make sure they don’t forget any features and have analyzed all dependencies for each.
Here’s how it works: Say a developer makes some changes to Feature 1. They take a look at the template above and perform a dependency impact analysis. As we already know from the matrix, any changes in Feature 1 directly influence Feature 1 itself.
But during analysis, the developer concludes that the changes introduced to Feature 1 also influence the state of Feature 3 and can possibly have an impact on the state of Feature 2. In this case, the developer needs to mark these dependencies in the corresponding cell of the matrix.
Then, the developer repeats the same analysis for each feature that was changed and enters the results of the impact analysis in the table.
| Note: To simplify the processing of analysis results, it’s best to color code levels of influence. At Apriorit, we define three influence levels and use the following colors to mark them:
Red — High influence Yellow — Medium influence Green — Low influence
You can also define influence levels with numbers:
3 — High influence 2 — Medium influence 1 — Low influence |
When using this approach, the table with dependency impact analysis results for our small project would look something like this:
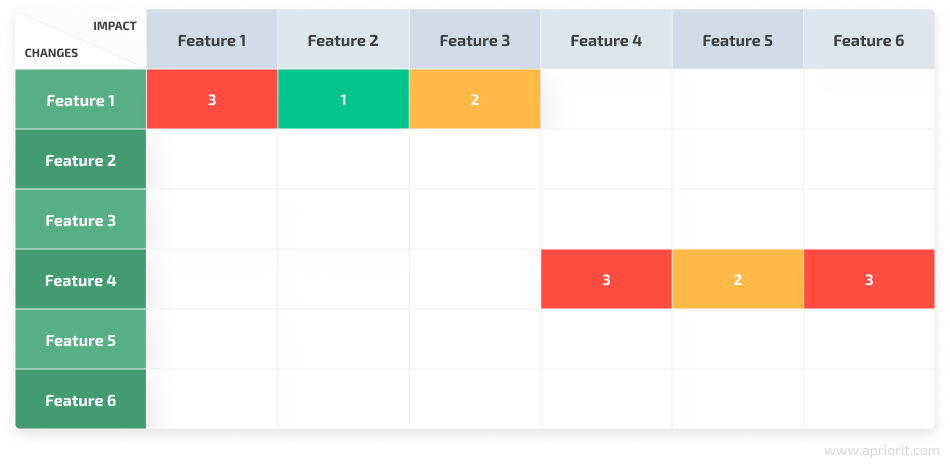
Figure 2. Dependency impact analysis results with defined change influence levels
A QA specialist can plan their work more thoroughly after receiving such a table. Using data from it, they can prioritize testing tasks and pay more attention to the most critical changes with the biggest impact on the product. This is especially important if there are strict time limits for product testing.
In our example, a QA expert can immediately notice that Features 1, 4, and 6 need to be checked first and require more attention. Features 3 and 5 also require some attention, as changes made to the product may have a moderate impact on them. Finally, Feature 2 can be tested last and might require less testing efforts than other features.
Read also
Internal Security Audit Checklist for Increasing Product Quality
Find out how a secure software development lifecycle can benefit your product. Explore the comparison of three ways of implementing security testing into your SDLC, along with an example of an internal security audit checklist.

Dependency impact analysis template for a large-scale project
First, let’s see how you can analyze dependency impact in a product that has lots of different modules, features, and functionalities. To make things even more interesting, let’s assume that each module of the product under test has a certain number of sub-modules, sub-features, and sub-functionalities.
The matrix from Figure 1 won’t be useful in this case. If we have 40 main features and each of them has 15 sub-features, for instance, we would have to work with a 600×600 table that looks something like this:
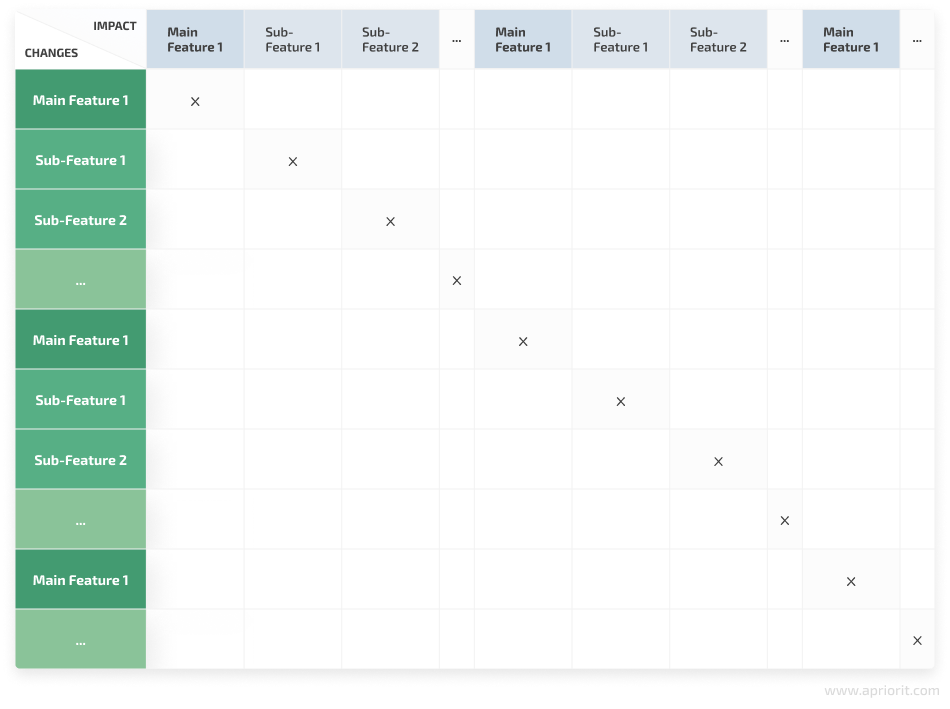
Figure 3. Example of using a small project’s matrix for a large-scale project
As you can see, this makes an enormous, bulky document that is absolutely unreadable and impossible to use.
So for large-scale projects, we’ve created a special dependency impact analysis table. In the rows of this table, we list all the main features, modules, and functionalities that can be singled out in the project. And in the columns, we define all sub-modules and sub-features related to the main features listed in the rows.
| Note: In some large-scale projects, defining three levels of change influence may not be enough. For such projects, you can use a five-point scale:
5 — Very high influence 4 — High influence 3 — Medium influence 2 — Low influence 1 — Very low influence |
We also use a different approach to maintaining impact analysis tables for large-scale projects. When a project has lots of different features and functionalities, developers don’t specify which features were changed. They only mark the features and functionality that are influenced or can be influenced by these changes.
Here’s what a dependency impact analysis table for a large-scale project may look like:
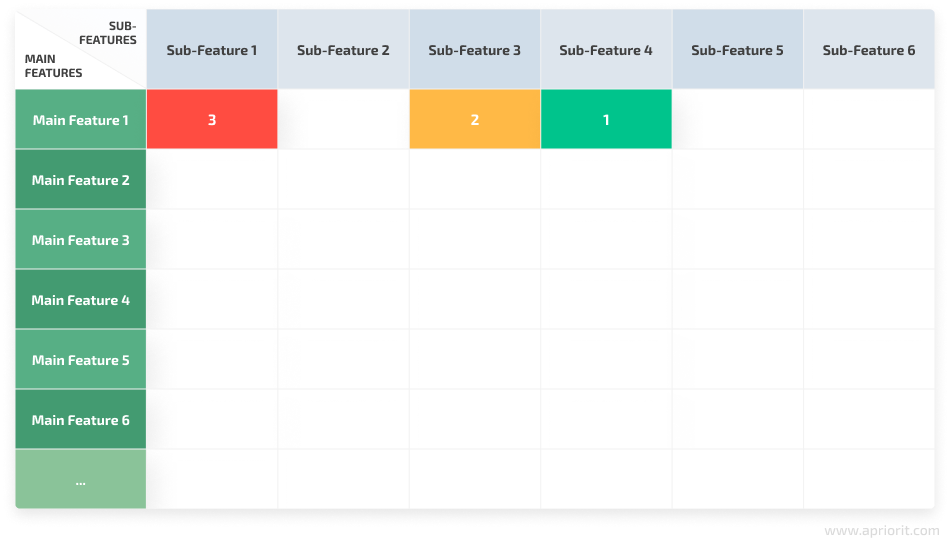
Figure 4. Dependency impact analysis table for a large-scale project
In Figure 4, you can see that the changes made by a developer influence only Sub-Feature 1, Sub-Feature 3, and Sub-Feature 4. All other sub-features aren’t impacted by these changes.
It’s also noteworthy that while a certain change may influence all sub-features related to the main feature, the level of influence of this change can differ for particular sub-features.
A developer can also specify any testing-critical information in the corresponding cell of the project’s dependency impact analysis table:
- Specific configuration for checking the work of a particular product version or feature
- Indication of a related product where the specified change should also be checked
- Indication of a specific problem that existed in previous versions of the product and requires special attention when testing the new version
- Any other useful data
With this approach to impact analysis in large-scale projects, we can avoid duplicating information and thus simplify the perception of valuable information.
Read also
A Brief Guide to Assessing Risks with Penetration Testing
Protect your software by leveraging cybersecurity risk assessment practices. Read the full text to find out how to proactively identify and mitigate security risks for your software.
Dependency impact analysis in a large-scale project: an alternative approach
Now, let’s see how to do impact analysis in software development of an enterprise product with approximately 40 complex features. In projects like this, developers often perform one of the following tasks:
- Fixing bugs
- Adding new sub-features
- Refactoring
Any of these tasks touches upon one or several main functionalities. To make these dependencies easier to work with, Apriorit developers add information on feature changes to the corresponding table columns:
- Affected configuration — Information on whether changes made by a developer depend on the operating system and what operating systems they should be tested on first.
- Developer’s comments — Information on introduced changes, developers’ testing recommendations, assumptions about possible bugs, etc. This information can be presented as a link to bug tracking results or a simple text description. This column is the most valuable for a QA expert.
- Importance — An estimate of the damage that can be inflicted by introduced changes. It can be a numerical value or a color scheme like in our previous examples.
- Developer’s plans for this feature — Notes on the possibility of introducing changes to a particular feature in the future. With this information, QA experts can choose the most suitable scope of testing for the current stage of the project. For example, QA specialists can avoid wasting time on testing a feature that soon will be changed again.
A dependency impact analysis table filled with such data would look something like this:
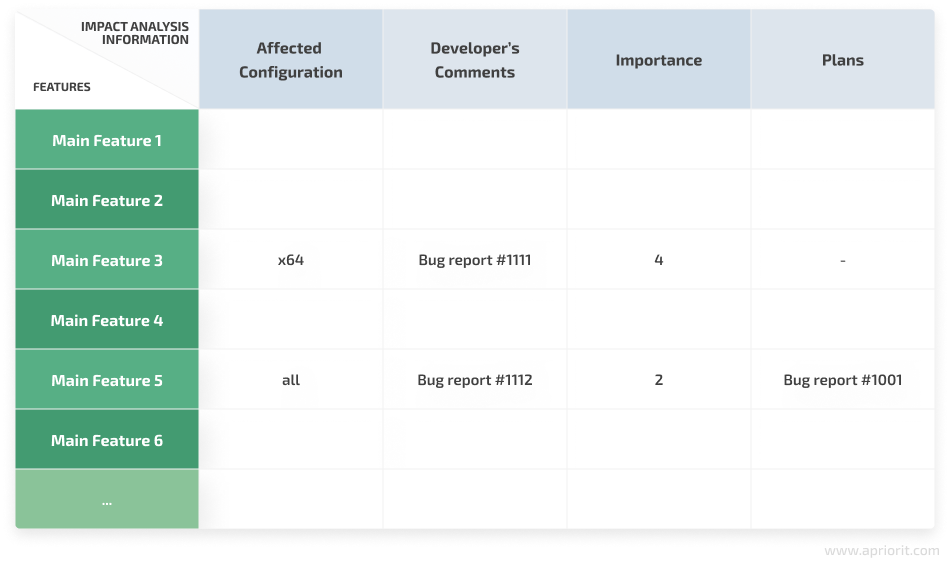
Figure 5. Dependency impact analysis table with additional information from developers
As you can see, the table isn’t too large and is convenient enough to read.
Related project
Developing a Custom ICAP Server for Traffic Filtering and Analysis
Explore a success story of creating and testing an ICAP server for sanitizing files. As we developed the solution that was successfully implemented into the existing product, our client managed to attract new customers and increase revenue.
Who performs impact analysis: software developers or QAs?
It’s all about well-balanced cooperation.
Performing dependency impact analysis is a responsibility shared by both developers and QA professionals.
Developers are the ones working on the product under test and introducing all changes to it. Therefore, it’s up to them to collect all necessary information about dependencies.

When developers follow these requirements, they can ensure that product changes and dependencies related to them are tested shortly after their implementation. And the earlier you detect a code flaw or bug, the easier it is to fix.
Also, remember that keeping dependency impact analysis documentation up to date requires time and that you need to allocate enough resources for this activity. If developers don’t provide QA experts with full and relevant information about introduced changes, the reliability of product testing might be compromised.
For QA specialists, dependency impact analysis is a powerful tool that allows them to considerably increase the efficiency of testing activities. Knowledge about the correlation and mutual influence of some changes can help QAs:
- Focus testing efforts specifically on altered functionality
- Take into consideration project parts that might have been affected by the introduced changes
- Avoid wasting time on testing parts of the project not affected by the introduced changes
Without this knowledge, QA specialists risk using test cases that don’t cover the last changes made in the project or not paying enough attention to parts of the product that were changed.
Now, let’s see how the cooperation between QA specialists and developers works in practice.
Read also
Techniques for Estimating the Time Required for Software Testing
Don’t compromise on software quality or meeting deadlines. With thorough QA time estimation, you can have both! Discover practical tips from Apriorit’s QA experts that can help you get realistic and functional testing time estimates for your project.
Dependency impact analysis workflow
Note: The approach we describe below is most suitable for projects that use a version control system (VCS). If your project doesn’t use a VCS, a developer’s workflow will be slightly different.
Currently, most of Apriorit’s projects rely on a VCS. In such projects, the filled out dependency analysis table is stored on the server with the prepared product versions.
Here’s what a developer’s workflow looks like in this case:
- Working with the copy of source code, a developer performs the task at hand but makes no changes to the main repository.
- The developer finishes the task and makes necessary changes to the main repository.
- The developer marks the features affected by product changes in the dependency impact analysis table stored in the main repository.
- The developer defines the level of influence for each change marked in the impact analysis table (using colors or numerical values).
- The developer adds necessary comments and additional information to the corresponding table cells.
- The developer saves the impact analysis table to the main repository and proceeds to the next task.
- The person responsible for the build saves the impact analysis table separately before the beginning of the build and clears the main table. The main table is now ready for new changes that will concern the next version.
After the build, the VCS copies the impact analysis table to the corresponding project folder on the server with prepared product versions. Thus, the system monitors that information in the table corresponds to project versions and allows developers to avoid unnecessary manual work.
Now, let’s move to the workflow of a QA expert. After receiving a request for testing, the QA expert does the following:
- Opens the received testing request and examines the information in it.
- Opens the dependency impact analysis table and estimates and analyzes information stored there.
- Plans the testing activity and prioritizes testing tasks based on information from the request and the table.
- Tests all product parts marked in the impact analysis table.
- Prepares a testing report based on the template approved by the team.
- Writes a testing response that includes information about the state of each product part marked in the impact analysis table.

This approach allows us to ensure the accuracy of received information on product changes and increase both the quality and speed of our work.
Read also
6 Ways to Improve Software Testing
Get the most out of testing activities while keeping them fast and flexible. Read on to find six proven ideas from Apriorit’s experts on improving the testing process.
How can you benefit from dependency impact analysis?
To understand the reasons for implementing dependency impact analysis into your testing routines, let’s compare two cases. Say we have a project with recently introduced changes. Let’s see how things can go when we use or don’t use dependency impact analysis.
Testing products without dependency impact analysis
Let’s say we changed a product feature but didn’t perform any impact analysis. A developer prepares a request for testing, specifying only the feature that was changed, and sends it to the QA team.
After receiving the request, a QA specialist tests the feature mentioned and the feature works perfectly. As the QA expert hasn’t found any bugs, they send a testing response saying that no bugs were detected in the tested feature.
Now, imagine that our target feature is closely related with another feature. Changes we make to the first feature can easily break the second. However, since we didn’t outline any dependencies in our request, the QA specialist has only checked the exact feature that was changed by developers and we ended up receiving inaccurate testing results because the request itself wasn’t fully accurate.
If this wasn’t a theoretical example, we would be lucky to discover this dependency before the actual release of the new product version.
Furthermore, simply adding a comment about possible change influences to the request for testing won’t solve the problem. We still might have to face risks associated with not analyzing the impact of dependencies:

Testing products with dependency impact analysis
Now, let’s see how the same process would go if we used dependency impact analysis.

Let’s say we have the same situation described above of making a change to the product and preparing a request for testing. Only this time, before sending the request, the developer analyzes the influence of the changes they made to the product. During this analysis, the developer never forgets about the features that are or can be influenced by the introduced changes because all these relationships are defined in the impact analysis table.
Most importantly, the developer will never overlook information about testing of product parts that are or can be influenced by the changes.
Conclusion
Dependency impact analysis is one of the key processes in a product’s development lifecycle. It ensures stable product performance and helps developers better trace the relationships between product features, track changes they make to these features, and determine the level of their impact.
For QA experts, dependency impact analysis is a useful tool for improving the efficiency of their work by making data-based decisions on which features to omit during testing and prioritizing testing for all other features.
At Apriorit, we have a highly qualified team of QA specialists who are passionate about the security and performance of the solutions they work on. Apart from expert quality assurance services, we also are ready to help you boost the security of your products with penetration testing and security testing.
Ensure the highest quality of your product!
Leverage Apriorit’s expertise in software testing to make sure your solution ticks all the boxes for top-notch quality.
Have a question?
Ask our expert!
VP of Engineering


