 Skip to main content
Skip to main content

Reverse engineering can help you accomplish some of the most challenging tasks: researching malware, analyzing intellectual property rights violations, maintaining undocumented code, and enhancing the security of embedded systems. Yet this process often requires a lot of manual analysis. So is there a way to fully automate reverse engineering?
At Apriorit, we have years of experience applying reverse engineering tools and techniques in all kinds of projects. In this article, we take you on a brief journey of the key stages of reverse engineering. We explain what techniques, tools, and methods this process relies on and what tasks you can accomplish using them.
This article will be useful to developers and cybersecurity researchers who are curious about the evolution of automated reverse engineering.
Contents:
First steps towards automating software reversing
Software reverse engineering, or backwards engineering, is the process of exploring the way a piece of software works by analyzing its code. Reverse engineering has come a long way from disassembling code with a pen and notepad in the beginning of the 90s to using automated analysis tools and decompilers to improve security and speed up software development.
Even about ten years ago, the possibility to reverse engineer software depended strongly on the reverser’s knowledge of a processor’s architecture, compiler specifics, and the operating system. Back then, we had no tools or techniques for reverse engineering automation and had to recognize high-level entities in binary code on our own. Most reverse engineers focused their efforts on studying a very limited circle of architectures, since most applications used one of the following three:
Other architectures like Tricore, RH850, and MIPS were usually ignored. Software engineers had neither the tools nor the need to perform reverse engineering for these architectures.
But with time, more and more devices started relying on uncommon microcontrollers. New microcontroller unit (MCU) architectures like NXP ColdFire offered a larger variety of features at a more affordable price than common architectures, making them extremely popular, especially among manufacturers of embedded devices. But it soon became apparent that nobody could tell for sure if these MCUs were secure enough.
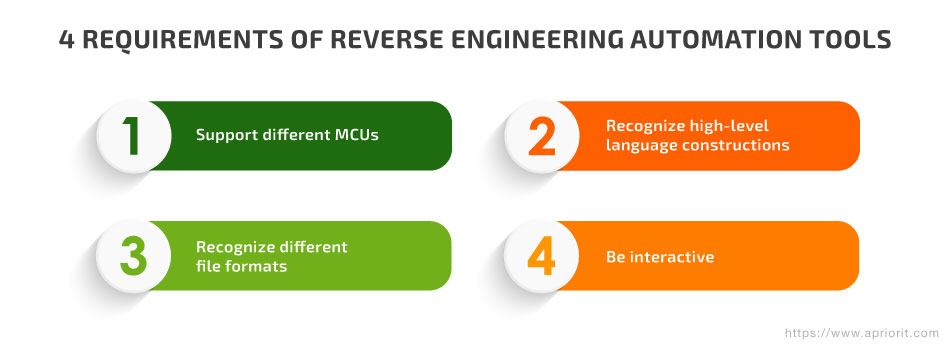
The need to assess the security of embedded devices and other products relying on uncommon microcontrollers created demand for a new kind of tool for automating reverse engineering. However, such a tool had to be able to accomplish at least four major tasks:
- Disassemble the code of up to several dozen CPU architectures
- Recognize high-level language constructions: functions, variables, calling conventions, cycles, switches, etc.
- Recognize file formats to accurately map code and data to virtual address spaces
- Allow for the needed level of interactivity so the reverse engineer could rename functions, variables, arguments, etc. and actually perform reverse engineering
Modern reverse engineering tools often leverage both static analysis (with no need for live code execution) and dynamic analysis (with necessary live code execution). By comparison, the first reverse engineering tools relied mostly on static analysis-based tools and techniques.
Uncover hidden vulnerabilities in your software
Optimize your product’s efficiency and protection by leveraging Apriorit’s professional reverse engineering services.
Using static analysis for reverse engineering automation
Static analysis investigates code with no regard to its execution or input. This type of program analysis helps reverse engineers investigate the overall control flow of the code and allows them to understand the sequences in which particular pieces of code get executed. Also, static analysis can be used to explore the data flows within analyzed software.
Let’s look closer at some of the first reverse engineering tools that relied on static analysis.
First static analysis tools for reversing
For a long time, the only tool that could somewhat accomplish the four previously mentioned tasks was the Interactive Disassembler, or IDA. However, this tool still had its downsides in its early days. While IDA supported multiple CPU architectures, not all of them were supported equally. This meant that features available for popular CPU architectures like ARM might not be available for a more exotic architecture like NXP ColdFire.
Plus, even though it supported scripts, you couldn’t run IDA in batch mode to disassemble a small chunk of memory without creating a disassembly database. This was overkill if you wanted to integrate the disassembler into your product.
Nevertheless, one major project was based on the IDA disassembler engine — BinNavi by Google. BinNavi is an integrated development environment (IDE) that allows you to find the differences between two versions of the same program. BinNavi can visually display differences in assembler code and take into account not only changes in instructions but also changes in code flow graphs.
There were also some less popular disassemblers that tried to compete with IDA, like Hopper and Radare2. Hopper is most suitable for retrieving Objective-C data from binary code. And just like in IDA, Hopper’s full functionality stack is only available in the paid version of the tool.
The main advantage of Radare2 is that it’s an open-source disassembler. You can integrate it into other software or use it via scripts, which is why many reverse engineers use Radare2 in their research to automate static analysis operations.
Eventually, disassembler engines started to be developed as separate disassembly frameworks and became more unified. Among the first disassembler engines were such frameworks and libraries as capstone, distorm, and udis86. Many of the open-source debuggers, dynamic instrumentation frameworks, and disassemblers that were launched later didn’t try to create a new disassembler engine. Instead, they relied on those that already existed.
Read also
How to Control Application Operations: Reverse Engineering an API Call and Creating Custom Hooks on Windows
Boost your software’s cybersecurity and control application operations with the help of custom hooks. Apriorit reverse engineering experts share their experience in intercepting and modifying API calls to improve the solution’s behavior without compromising performance.

Advancement of static analysis tools in reverse engineering
While code decompilers allow for some basic analysis automation, they work rather slowly. Too much time is spent on basic things like learning where variables are defined before a reverser can start recovering the real logic of the code. Reverse engineers faced the need for a more readable presentation of the disassembled code, so the first attempts were made to create a decompiler for native code.
Static analysis-based tools for reverse engineering went through three stages of advancement, helping reverse engineers automate more and more complex tasks:
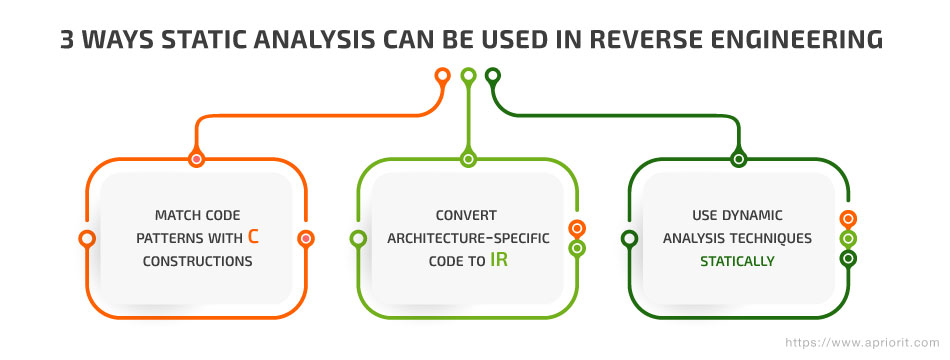
1. Match code patterns with C constructions
The first decompilers tried matching code patterns with C language constructions and then generating a C-like view of the assembler code. This meant that researchers had to introduce new patterns for each CPU architecture in order to decompile it, however, which was too time-consuming to implement.
2. Convert architecture-specific code to an IR
After some time, another approach for decompilation was suggested: converting the architecture-specific code into intermediate representation (IR) and then generating the decompiled code from the IR. This approach eliminates the need to know architecture-specific constructions generated by a compiler in order to generate a C-based representation of the code. Only the backend responsible for converting assembler instructions into the IR should be implemented for each CPU architecture. Then a single disassembler engine can decompile all the code from the IR to C.
This is how Ghidra and IDA currently decompile code for various CPU architectures.
Decompilation shifted the focus of reverse engineering from recovering basic C constructions to recovering data structures and restoring C++ classes. This approach gave birth to multiple variations of IR engines:
- VEX
- Low-level virtual machine (LLVM)
- Reverse engineering intermediate language (REIL)
- miasm
- And more
Intermediate representation engines appeared to be useful not only for decompilation but also for finding bugs via dynamic and static analysis. For example, Valgrind relies on VEX IR for the discovery of memory leaks while the Angr framework uses VEX IR as its base for binary code analysis, code execution simulation, and symbolic execution.
The Carnegie Mellon University Binary Analysis Platform (CMU BAP) uses REIL IR to find common vulnerabilities in the binary code of Linux systems for multiple CPU architectures. The Obfuscator-LLVM project uses LLVM IR to obfuscate binary code and thus protect it from reverse engineering. Miasm, in turn, uses its own IR to deobfuscate code.
3. Use dynamic analysis techniques statically
Leveraging symbolic execution and simulated code execution, reverse engineers started performing static analysis with dynamic analysis techniques. In particular, researchers used techniques like taint analysis, reaching definitions, and code simulation.
Taint analysis helps researchers find execution paths in the code flow while the reaching definitions technique allows for tracking changes to a variable. Code simulation, in turn, makes it possible to statically use the Z3 Theorem Prover (Z3 solver) tool to determine if there are conditions at which some branch of the code is executed. If such conditions exist, they can be used to generate the shellcode or payload needed to trigger a vulnerability.
Both Z3 solver and taint analysis rely on dynamic instrumentation. They can be set up to run from a specific point of process execution and then use the execution traces to check if some point of the code was reached or which instructions are involved in accessing a variable.
Read also
How to Reverse Engineer Software (Windows) the Right Way
Unlock the secrets of Windows software with our detailed guide on ethical and efficient reverse engineering. Apriorit specialists share their expertise in analyzing product security, understanding the workings of unfamiliar .exe files, recovering lost documentation, and building new solutions from legacy software.

Using dynamic analysis for reverse engineering automation
Further automation of reverse engineering processes continued with the appearance of the first dynamic analysis-based tools. In contrast to static analysis, dynamic analysis requires live execution of the processed code.
Reverse engineering tools relying on dynamic analysis also went through three stages of development, each stage increasing the complexity of the tasks that could be solved:
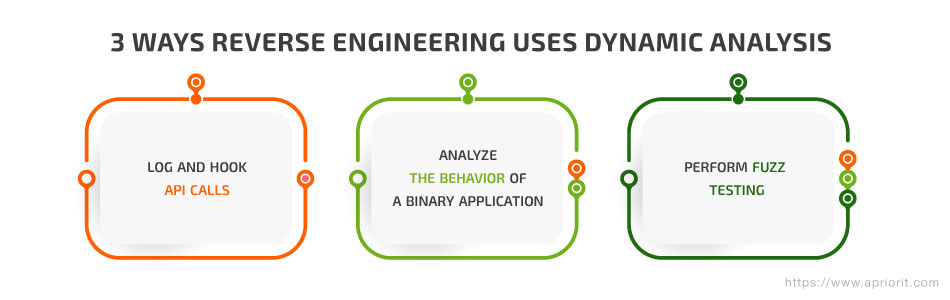
1. Log and hook API calls
The first attempts to use dynamic analysis for reverse engineering automation were made with API call logging tools like API Monitor and hook engine libraries such as mhook and Detours that simplified the injection of code into the target process and further hooking of the specific API call.
2. Analyze the behavior of a binary application
But soon it became clear that reverse engineers needed a sophisticated framework in order to manipulate thousands of hooks and perform complex actions when executing a hooked function. The first dynamic binary instrumentation frameworks included:
Dynamic binary instrumentation (DBI) allows for creating a precise code execution trace without needing to place multiple breakpoints in the code. Dynamic instrumentation actually uses a disassembler to find branch instructions and inserts trampoline code calls that are then analyzed by the instrumentation engine. Today’s DBI-based tools help reverse engineers perform taint analysis, trace instructions, analyze self-modifying code, detect shellcode, and do much more.
3. Perform fuzz testing
The ability to precisely control code execution made it possible to create fuzz testing tools that strongly rely on code coverage techniques. Fuzzers like American fuzzy lop (AFL) and WinAFL generate input data for code and check which code flow branches are hit. Then, they try to generate another set of input data which is supposed to trigger the execution of branches that were not executed previously. In such a way, a fuzzer can find the code flow branches that can lead to severe security issues like system crashes, buffer overruns, and stack overruns.
Currently, fuzzers are mostly used for automating the search for bugs and errors in code that can’t be found manually. There are many specific fuzzers for:
- Network protocols (AFLNet, Fuzzowski)
- Hypervisors (vmmfuzzer, applepie)
- Kernel drivers (difuze, IOCTLbf)
- Unified Extensible Firmware Interface (efi_fuzz)
- Browser engines (BFuzz)
- Common applications (Honggfuzz, OSS-Fuzz)
Some researchers also try to use code simulators to fuzz microcontroller code in Angr and Quick Emulator (QEMU).
However, many researchers use static and dynamic analysis in parallel. For instance, you can use static analysis to determine code sections requiring deeper research and then use dynamic analysis to get more valuable information, like packet data.
Related project
Improving a SaaS Cybersecurity Platform with Competitive Features and Quality Maintenance
Explore our client’s success story of enhancing their software’s capability to detect and manage vulnerabilities. Find out how Apriorit’s development, testing, and support services helped our client make their platform more stable and competitive.

Conclusion
Reverse engineering is no longer tied to x86 and ARM architectures — it is now applied to each and every existing architecture. And the ability to simulate code execution has made it possible to debug microcontroller code without a real device.
With modern decompilers and automation techniques in reverse engineering, there’s much less need to go into disassemblers or dive deep into file formats to learn what binary code does. Today’s reverse engineers can decompile binaries for various architectures, find code vulnerabilities, and obtain comprehensive information about the code flow and data flow via dynamic analysis.
Got a project that requires excellent reverse engineering skills? At Apriorit, we know how to reverse engineer a program and have vast experience using sophisticated reverse engineering tools and techniques for different cybersecurity tasks. Get in touch with us to start discussing your project right away.
Ready to gain a competitive edge?
Enhance your software’s security, compatibility, and performance by partnering with Apriorit.
Have a question?
Ask our expert!
Program Manager


