 Skip to main content
Skip to main content

In this article, we share our experience using WinAFL for dynamic fuzzing of popular image viewers: ACDSee, FastStone Image Viewer, IrfanView, and XnView Classic. We explain why it’s important to add fuzzing to your quality assurance processes and how reverse engineering techniques can help you get more out of testing closed source software.
Contents:
- Static fuzzing vs dynamic fuzzing
- Static fuzzing: pros and cons
- Dynamic fuzzing: pros and cons
- Before we start fuzzing
- Finding a good function to fuzz
- Preparing for fuzzing
- WinAFL essential metrics
- Fuzzing Windows image viewers
- IrfanView fuzzing
- XnView fuzzing
- FastStone fuzzing
- ACDSee fuzzing
- What we found
- Conclusion
In recent years, fuzzing has been widely applied for identifying vulnerabilities in software. Furthermore, this method is actively used not only by legitimate testers and researchers but also by cybercriminals.
Fuzzing is a security testing approach that involves inputting invalid or random data to the system in order to discover vulnerabilities that can’t be detected by other testing methods. Originally developed by Barton Miller in 1989, this type of security testing has proved to be effective at finding vulnerabilities other testing methods miss.
Fuzzing can be applied to any software with an interface that accepts some form of input from potentially malicious sources. The best scenario is when fuzzing complements regular automated testing, increasing code coverage by triggering execution flaws that otherwise would remain untouched.
While the main goal of fuzzing is feeding the target with a large number of test cases, it’s often conducted semi-automatically or fully automatically with special software called fuzzers.
American fuzzy lop (AFL) is the most popular code coverage-guided tool that uses a wide range of highly effective fuzzing strategies and provides good results for finding vulnerabilities in real software. However, for testing closed source software, we use WinAFL, a DynamoRIO-based AFL fork for Windows. This tool has instrumentation that allows you to find software security vulnerabilities even in closed source binaries of compressed formats such as videos, images, and archives.
WinAFL provides instrumentation for three modes of testing:
- syzygy is a static instrumentation mode for decomposing binaries with private symbols.
- DynamoRIO is a dynamic mode for testing software in runtime and transforming its code anywhere.
- Intel PT (Processor Tracing) mode is used for tracing code executed by the CPU when software is running.
Looking to enhance your product’s security?
Get unparalleled insights into your applications and systems. Leverage Apriorit’s development and cybersecurity skills to improve your product’s functionality and protection.
Static fuzzing vs dynamic fuzzing
Fuzzing can be performed either statically or dynamically. Let’s compare these two approaches.
Static fuzzing: pros and cons
A typical scenario for static fuzzing looks like this:
- Choose the API you want to fuzz.
- Write the harness code (the code that will interface with the API during the AFL loop).
- Instrument the binary statically.
- Run AFL and check the stability of the program under test.
- Fix harness or source code, if needed, and return to step 3.
- Wait.
Below, we highlight some advantages and drawbacks of static fuzzing.
Advantages of static fuzzing:
- You own the code, so making changes to the harness is easy, and the code of the harness is easy to debug.
- You almost always know how changes in the harness affect the execution of the fuzzing loop.
Drawbacks of static fuzz testing:
- Having the full source code doesn’t always guarantee you’ll manage to write the harness. Due to the complexity of the code architecture, it can be impossible to run some parsers separately from all other code entities being initialized. You may also discover that separating the code affects the parser’s flow.
- When you have partial source code, it may turn out that the API that can be used for the harness is of a very high level. For instance, in the case of image viewers, we can only access the API that creates the whole viewer, not only images. This means that you can’t fuzz just at the level of the code that parses image bytes; you have to fuzz at the level of the code that both parses images and draws the UI. In this case, there’s a lot of code that will be executed before the actual parsing starts. The more code we have to execute on each fuzzing iteration, the more time the fuzzing process will take.
- If you don’t have the source code at all, it may be impossible to use static fuzzing, as the code you need is somewhere deep within the binary.
- WinAFL demands the input file be closed at the end of the iteration. Depending on the logic of the software we want to fuzz, it may require a lot of changes to the code to have all the file handles closed.
- The harness may not take into account the specific sequence of API usage in the real code.
Dynamic fuzzing: pros and cons
Runtime fuzzing involves the following steps:
- Reverse the code to find the parser entry point function.
- Implement the harness to set up the parser input from memory.
- Patch or disable all unnecessary code within the harness.
- Run AFL and check the stability of the program under test and map density.
- Analyze the code coverage to find code that affects the stability, then return to step 3.
- Wait.
Advantages of dynamic analysis:
- You can use dynamic fuzzing when you have no source code.
- You can apply dynamic fuzzing to any part of the code under test.
- The crash cases discovered using dynamic fuzzing are more accurate than those discovered using static fuzzing because you test (fuzz) the real code and don’t spend your time testing synthetic code.
- Dynamic fuzzing is more efficient, as the fuzzer executes the parser code only. No high-level code is involved, so the fuzzer traverses the execution paths faster.
Drawbacks of fuzzing at runtime:
- This approach requires a lot of reversing, as you work only with the binary file and don’t have the source code.
- It’s hard to debug the harness code when fuzzing at runtime.
- It’s harder to find the parts of the code that affect the target software’s stability.
- Sometimes, there’s no good entry point for the parser code, and in an attempt to find it, your harness code may become too complex.
- Sometimes there’s a global object used within the parser, and you can’t work around it as it has dependencies.
- You can’t fuzz with pure WinAFL, as an in-memory fuzzer is required.
But we’re not afraid of the difficulties. Now we’re going to show you how to apply dynamic fuzzing to four popular image viewers for Windows.
Read also
Finding Vulnerabilities in Closed Source Windows Software by Applying Fuzzing
Improve your testing strategy and software security with the help of fuzzing. Apriorit experts share their valuable insights in uncovering bugs that traditional QA methods might miss.

Before we start fuzzing
First, we need to choose what image viewers we’re going to fuzz.
As our target software, we selected the most popular Windows image viewers: IrfanView, XnView, FastStone, and ACDSee. For dynamic fuzzing, we used the following versions of these programs:
- IrfanView 4.52
- XnView Classic 2.48
- FastStone Image Viewer 7.0
- ACDSee Free 1.1.21
The main issue was that all of these image viewers are closed source, so in order to start fuzzing, we had to reverse the code to find the parser entry point function. This is our next step.
Finding a good function to fuzz
Detecting the best function to fuzz was challenging, and we tried different methods of doing so:
- Static analysis
- Code coverage analysis
- Grab coverage with DynamoRIO, for instance (with ACDSee):
drrun.exe -t drcov -- "…ACDSee Free.exe" …a.bmp- Use the lighthouse IDA plugin to speed up static analysis and find the most appropriate function to fuzz
- Process Monitor that shows the real-time file system as well as file filters and stack trace
- Debugging and scripting for saving/restoring the function execution context
- Reversing patterns
Reversing patterns turned out to be the most effective method for detecting which function is best to fuzz. For the image viewers written in C (IrfanView, XnView, and FastStone Image Viewer), we used reversing patterns by analyzing each function one by one in the stack trace of ReadFile() to determine which function does the parsing.
We also looked for the sequence: CreateFile() –> ReadFile() –> CloseHandle(). If a selected function actually processes a file’s data, then it’s the ideal candidate!
For ACDSee, which is written in C++, we needed to use another approach. If a function that reads data from the file is a class method, then we can try to find the method that does the parsing. If we’re lucky, we can find the function that creates the instance of the class. Ideally, we need to find the function that creates the class, calls the parsing methods, and frees the class.
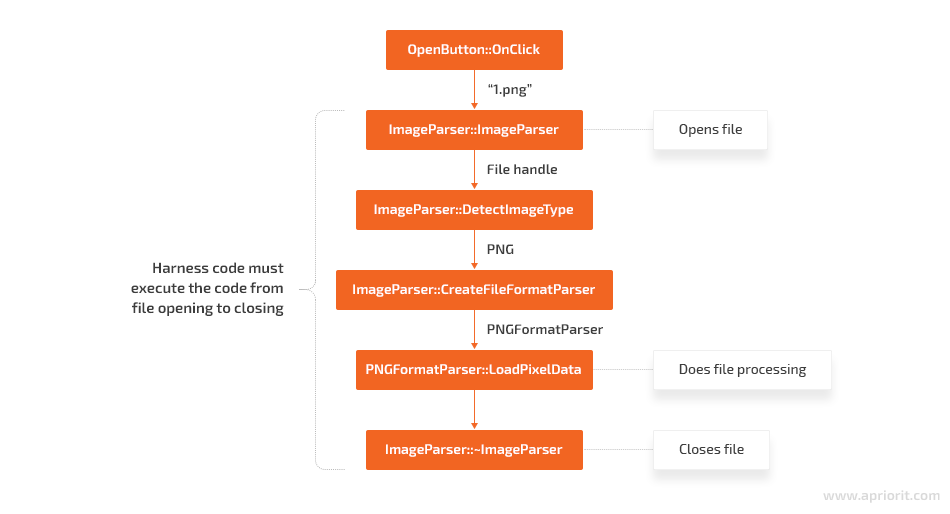
This is an example of a hypothetical code flow for a UI button handler that starts the image file processing logic. Even though the real parsing is happening in PNGFormatParser::LoadPixelData(), the harness can’t call this function directly because the harness doesn’t control file access. Thus, the harness must be created at the level where the file can be both opened and closed.
Read also
How to Reverse Engineer an iOS App: Tips and Tools
Discover practical reverse engineering techniques to uncover iOS app vulnerabilities so you can prioritize fixes and strengthen your mobile security posture.

Preparing for fuzzing
In order to start fuzzing, we need to understand some crucial internals of WinAFL. As we said above, WinAFL has several instrumentation modes: DynamoRIO, Syzygy, and IntelPT. The most suitable mode for our needs is DynamoRIO. So everything below is about WinAFL and DynamoRIO.
When you start fuzzing a particular function in the binary — your target function — WinAFL does the following:
- Calls DynamoRIO to set up the process. This step includes the instrumentation of every basic block in the module specified by the
-target_moduleparameter. - Starts executing the instrumented binary and hooks the target function pointed to by
-target_offset. - Saves the function’s arguments when execution reaches the target function.
- Runs fuzzing on the target function and waits for it to end.
- When the target function returns, WinAFL collects the coverage and produces and writes a new input file. Then it restores the saved target function’s arguments and runs the target function again.
We can’t leverage the -target_offset function out of the box in a lot of cases. Actually, it’s pure luck if we can do this.
It would be nice to make WinAFL read the test case into memory and pass it as a pointer to the -target_offset function. In this way, we could increase the attack surface. In fact, there are several ways in which the target function, which parses the input, can access the file’s buffer: raw pointer access, C++ streams, memory-mapped files, etc. If we can craft that object, we can fuzz the target function.
But there might be some problems with this approach:
- The target function might modify global variables/objects.
- The target function might use nested C++ classes, which are usually stored on the heap. Besides, these classes may contain fields that affect the code flow.
If we don’t handle this, the target code might behave inconsistently. So we should think not only about arguments of the particular function but also about the context of the function’s execution. This is a hard task, but sometimes it can be achieved without too much effort.
WinAFL essential metrics
WinAFL provides a lot of information. For now, let’s look at the most important information for us.
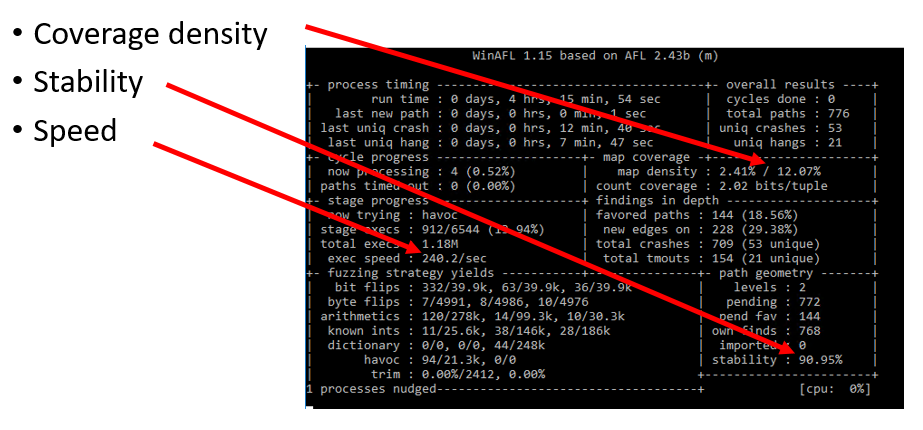
Coverage density
This field is a bit tricky to understand. For performance reasons, coverage data is stored in a 64KB buffer. If you increase its size, it will slow down the whole fuzzing process. In the “basic block” instrumentation type in DynamoRIO (there’s also the “edge” type, which is a bit more complex but can catch more sophisticated coverage changes), WinAFL just adds one instruction to each basic block:
inc cov_data[pc_addr % 65536]Where:
pc_addris your Extended Instruction Pointer (EIP) registercov_datais basically the coverage data buffer
This is how WinAFL tracks the coverage. So map density : 2.41% / 12.07% means that the current fuzzing iteration changes 2.41% of the 64KB buffer, and all iterations in the current session achieve a combined 12.07% coverage. If you get low numbers in these fields, it indicates that the fuzzing doesn’t hit a lot of instructions.
Stability
Sometimes WinAFL passes the same input to the binary several times and checks if that input produces new coverage. In theory, it shouldn’t. But if it does, WinAFL marks this new coverage as unstable and lowers the corresponding coverage percentage. Low stability might indicate that the fuzzing session is unreliable.
By default, coverage and stability are calculated for all threads, but you can specify -thread_coverage for measuring this data only for one particular thread. This might increase stability
Speed
Speed is the number of iterations per second. You can start several fuzzer instances and multiply that value. Low-speed fuzzing may not produce results for a reasonable time.
Related project
Developing a Custom Driver Solution for Blocking USB Devices
Discover how our team helped a client enhance their cybersecurity product by developing a custom driver for blocking unauthorized USB devices. Find out what benefits your enterprise solutions can get from professional custom driver development.
Fuzzing Windows image viewers
Now let’s take a look at our results of fuzzing the four popular image viewers we mentioned above.
IrfanView fuzzing
While fuzzing IrfanView, we discovered that the use of Procmon’s stack call and coverage significantly speeds up reversing. To enhance the reversing process, we can pass the path to a file as a parameter for i_view32.exe and check the stack call on the ReadFile() function in Procmon:

Here is how the lighthouse plugin can highlight basic blocks in IDA:
The control-flow graph of that function was looking promising, because it was huge and sophisticated:
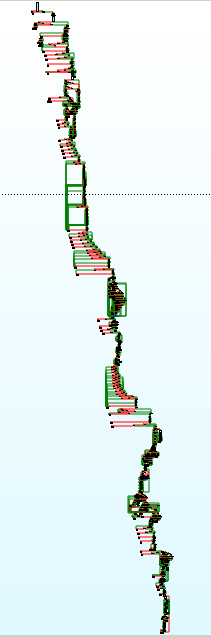
To start fuzzing, we ran the following:

The first trouble we ran into was a directory mismatch. We fixed it with the -f parameter.
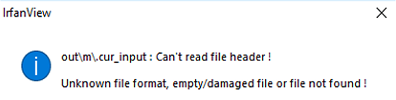
The second issue was with the file’s extension:
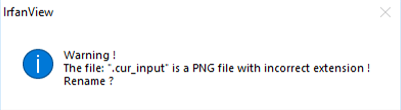
To solve this issue, we modified the WinAFL source code a little bit.
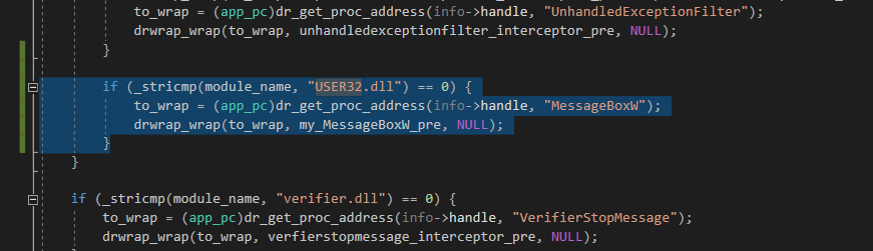
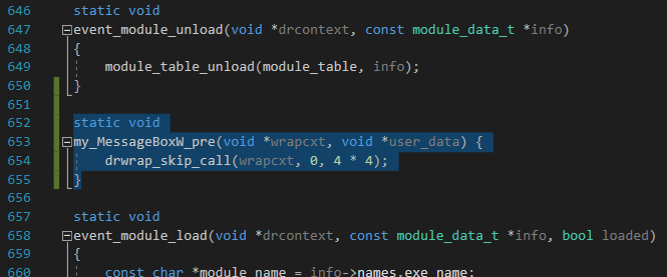
This code just skipped the MessageBoxW function and returned 0. After that, we got the first crash in ~1.5 hours with 4 threads running with the minimal corpus.
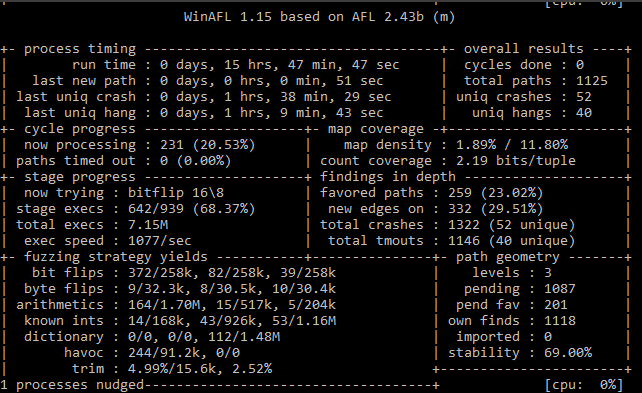
XnView fuzzing
For fuzzing this image viewer, we used the same method.
In this case, the target offset was 0x6384B0 and the first crash was after ~2 minutes of single-threaded fuzzing!
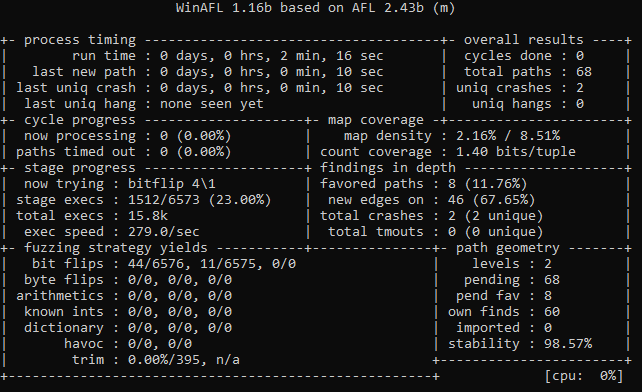
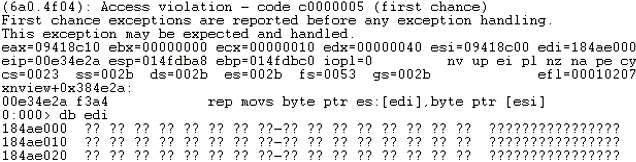
FastStone fuzzing
For fuzzing FastStone, we used the same method once again.
The target offset was 0x5ECBCC, but here we also needed to save registers ecx, edx, and edi in order to run stable fuzzing. For saving registers, we used WinAFL’s pre_fuzz_handler() function. For testing FastStone, we used only single-threaded fuzzing because there was an issue with running multiple instances of the viewer. But apparently this was enough, as in 16 hours there were 52 crashes.
ACDSee fuzzing
Fuzzing ACDSee was the hardest, as the program is written in C++. It took us about two to three days of reversing to create a stable harness.
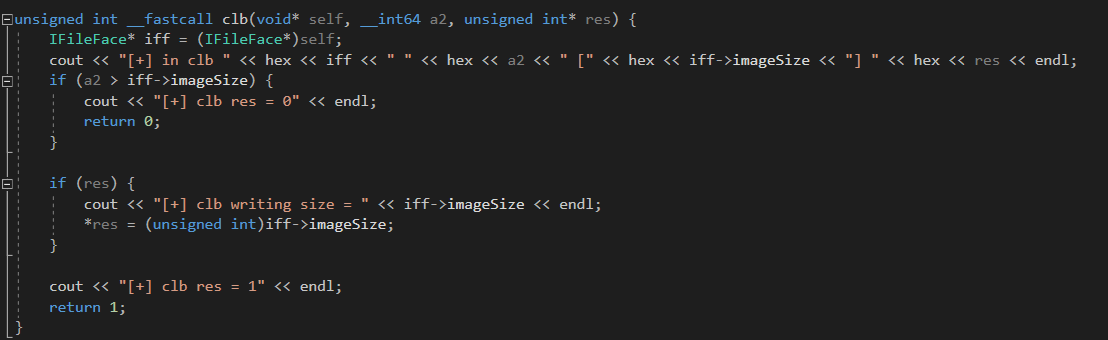
C++ code, fortunately, has run-time type information, which simplifies the reversing process. In order to run stable fuzzing, you need to save at least four related to “this” classes. The viewer also checks the file extension before parsing. The funny side effect of our approach was that we actually fuzzed the function that not only parses an image but also draws it. Let’s look at the live fuzzing process.
In the end, our harness was still not so stable, and sometimes the fuzzer just died. We ran it single-threaded because there was an issue with running multiple instances. But eventually, it was enough, and we met the first crash in 6 minutes.
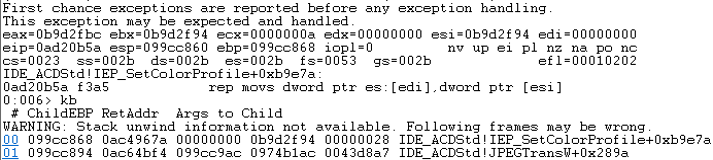
By the way, ACDSee uses a plugin system, PlugInsIDE_ACDStd.apl, which is actually a .dll executable responsible for image parsing. The vendor even provides an SDK for plugins, but you need to request it, which we didn’t. You can read here how to fuzz that .dll.
Read also
Anti Debugging Protection Techniques with Examples
Fortify your software against malicious analysis and intellectual property theft. Read on to discover how anti-debugging techniques can shield your programs.

What we found
Here’s a short summary of the results of our fuzzing.
| Product | Version | WinAFL reported crashes | Unique crashes filtered by !exploitable | CVEs assigned |
| XnView Classic | 2.48 | 825 | 284 | 13 |
| IrfanView | 4.52 | 389 | 130 | 2 |
| FastStone Image Viewer | 7.0 | 65 | 16 | 3 |
| ACDSee Free | 1.1.21 | 1947 | 16 | 6 |
List of CVEs:
- XnView Classic 2.48: CVE-2019-13083, CVE-2019-13084, CVE-2019-13085, CVE-2019-13253, CVE-2019-13254, CVE-2019-13255, CVE-2019-13256, CVE-2019-13257, CVE-2019-13258, CVE-2019-13259, CVE-2019-13260, CVE-2019-13261, CVE-2019-13262
- IrfanView 4.52: CVE-2019-13242, CVE-2019-13243
- FastStone Image Viewer 7.0: CVE-2019-13244, CVE-2019-13245, CVE-2019-13246
- ACDSee Free 1.1.21: CVE-2019-13247, CVE-2019-13248, CVE-2019-13249, CVE-2019-13250, CVE-2019-13251, CVE-2019-13252
Conclusion
Third-party software for Windows is not always as secure as we tend to think. Fuzzing allows you to find vulnerabilities in software that remain undiscovered by traditional testing methods. Though there are many success stories about testing open source software, the Apriorit team has proved that with reverse engineering, you can effectively identify vulnerabilities even in closed source software.
Applying dynamic fuzzing to ACDSee, FastStone Image Viewer, IrfanView, and XnView Classic allowed us to detect 24 critical vulnerabilities that were approved by the MITRE Corporation.
Apriorit has a team of highly qualified reverse engineers who know how to reverse engineer an app and can help you perform security testing on your solution. Feel free to contact us using the form below.
Learn your software from the inside out
Breathe new life into your existing applications by enhancing their cyber defense! Entrust your security and development challenges to Apriorit’s reverse engineering specialists.
Have a question?
Ask our expert!
Program Manager


