 Skip to main content
Skip to main content

On your way to delivering a competitive iOS app, you may face challenges that require creative solutions. For example, your team may need to identify and resolve issues with the compatibility of third-party libraries or frameworks for which documentation is incomplete or outdated. Reverse engineering allows you to uncover the behavior of such libraries and frameworks and ensure seamless integration.
Reverse engineering is the direct opposite of building or engineering an application: it involves breaking down an existing application bit by bit to see how it actually works. Developers incorporate reverse engineering techniques to assist them with various tasks, from investigating bugs in code to ensuring smooth and easy legacy code maintenance.
When reverse engineering software, the operating system it was created for should be one of the first things you pay attention to. In this article, we describe how to decompile macOS software and iOS apps. This tutorial will be useful for developers who want to know more about macOS software and iOS apps reverse engineering.
Contents:
Why reverse engineer your iOS app?
When you build a piece of software, you usually have all of the source code available and can review it at any time. So figuring out how a particular process or feature works shouldn’t be too much of a challenge.
But what if you have an executable and you need to figure out how it works without access to any source code? The solution is to reverse engineer it.
Note: While reverse engineering an iOS app can bring you immense value, your team should use this practice with caution and respect for legal and ethical considerations.
There are several reasons why you might need to use reverse engineering:
- Investigate complex software issues. Reverse engineering helps to identify the root causes of crashes, performance bottlenecks, or bugs in third-party iOS applications, especially when source code isn’t available.
- Enhance compatibility with third-party solutions. By reversing, you can analyze an app’s binary to understand how it interacts with APIs, frameworks, or other services. This can help you seamlessly integrate custom tools or third-party software solutions.
- Improve interactions with the iOS ecosystem. You can customize and optimize your app’s functionality by revealing how the app communicates with the iOS platform, including with system daemons, shared caches, and proprietary APIs.
- Maintain and update legacy applications. If your iOS app’s source code is lost or outdated, reverse engineering can help you recover code logic, making it possible to maintain or upgrade the application to meet modern standards.
- Identify and mitigate security vulnerabilities. Reverse engineering is essential for uncovering vulnerabilities within iOS apps and correctly implementing security measures like encryption, authentication, and data handling.
- Recover lost documentation. If your app lacks documentation, you can use reversing to generate technical documentation. This will allow your team to understand the behavior of and effectively maintain the application.
- Evaluate app behavior for compliance. Reverse engineering can determine whether your iOS app complies with regulations or exhibits malicious behavior, especially in security-critical contexts like finance or healthcare.
Below, we take a closer look at the basic structure of an executable, briefly cover reversing Objective-C and Swift code, list several of the most popular tools for reverse engineering iOS apps, and share a methodology for reverse engineering an iOS app for several use cases.
Let’s start with some basics that you need to know before we discuss how to reverse engineer an iOS app.
Looking for skilled reverse engineering teams?
Unlock the full potential of your software by delegating non-trivial tasks to Apriorit’s experienced reversing engineers.
Basics of iOS reverse engineering
If your team has decided to reverse engineer binary, they should understand that some parts of it probably contain executable code. Therefore, before your team even starts reversing a piece of software, they need to learn the executable binary structure.
Note: All examples we show are for research purposes only.
Executable binary format
In the world of Mach kernel-based operating systems, it’s common to use the Mach-O executable format. These executables can be inside thin or fat binary files. Here’s how these two types of binaries differ:
- A thin binary contains a single Mach-O executable
- A fat binary may contain many Mach-O executables
We use fat binaries to merge executable code in a single file for different CPU instruction sets.
Here’s the basic structure of a Mach-O executable:
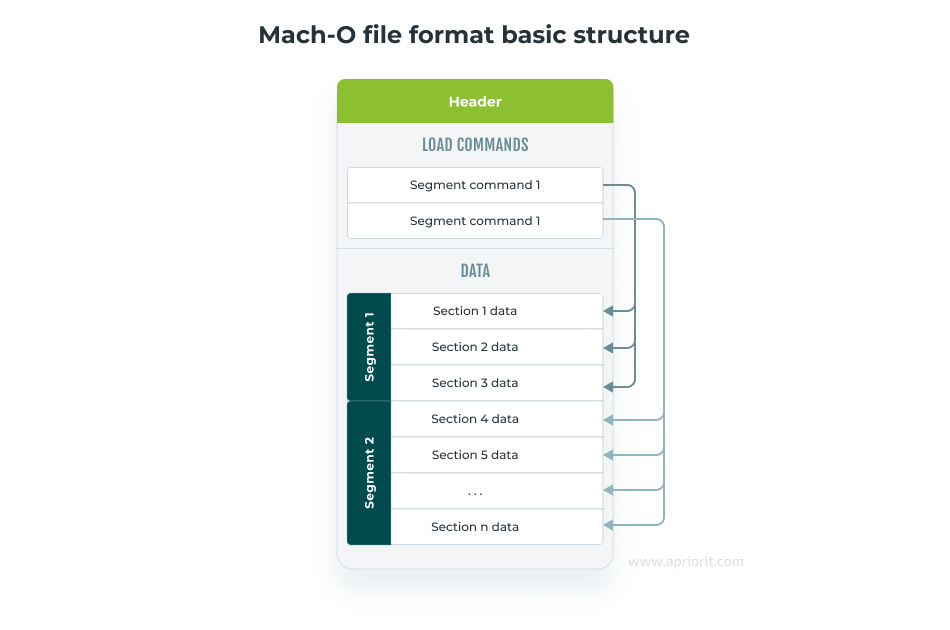
Let’s take a closer look at each component.
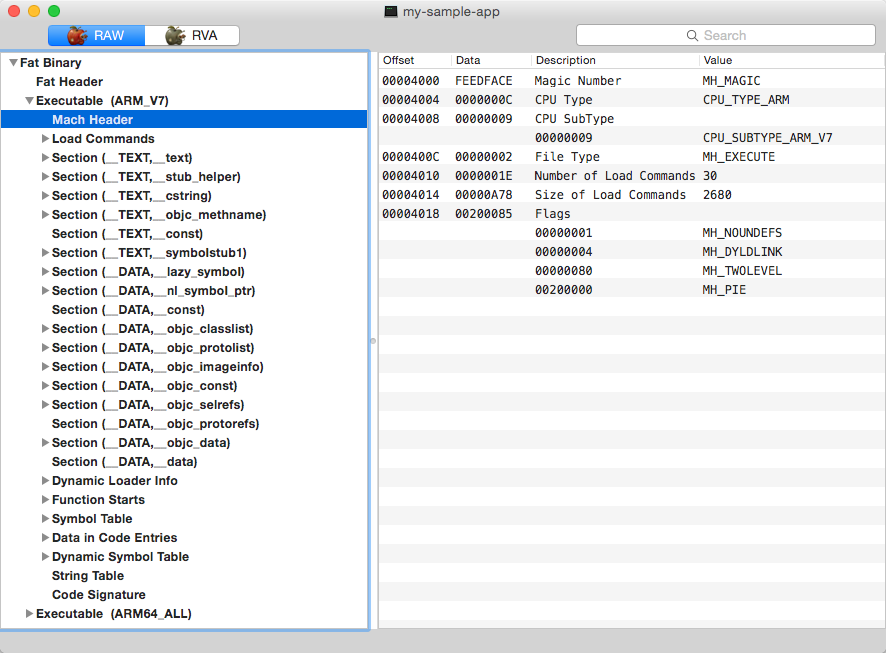
Every binary begins with a header. This is a key part of every executable for iOS, and it’s the first part of the executable read during image loading.
A fat binary begins with a fat header, while a thin binary begins with a mach header. Every header starts with a magicnumber used to identify it.
A fat header describes the locations of mach headers for executables in a binary. A mach header describes general information about the current executable file.
A mach header contains load commands that represent several things crucial for image loading:
- Segments and sections of the executable and its mapping to virtual memory
- Paths to the linked dynamic libraries
- Location of tables of symbols
- Code signature
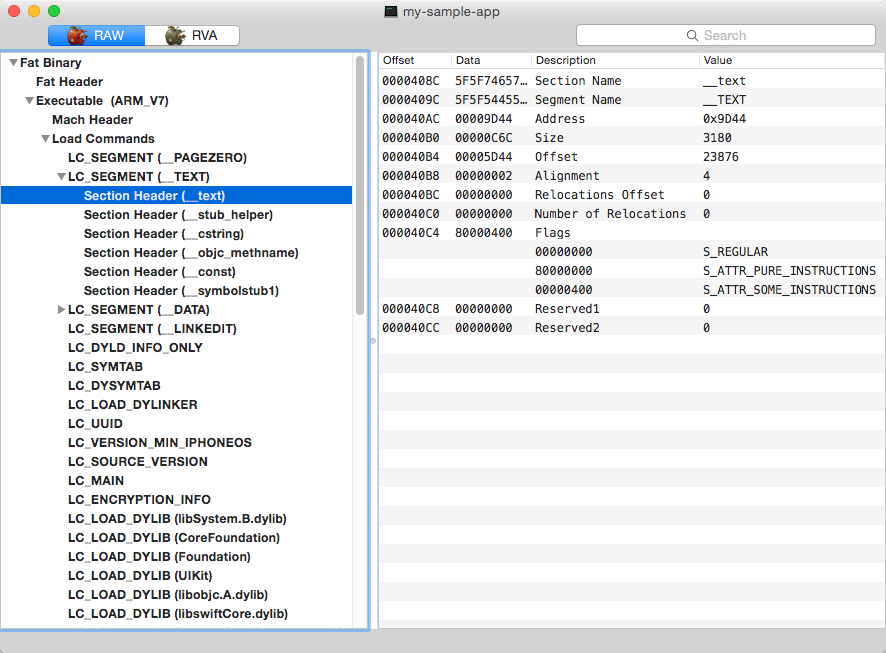
Segments are typically large pieces of an executable file mapped by a loader to some location in the virtual address space.
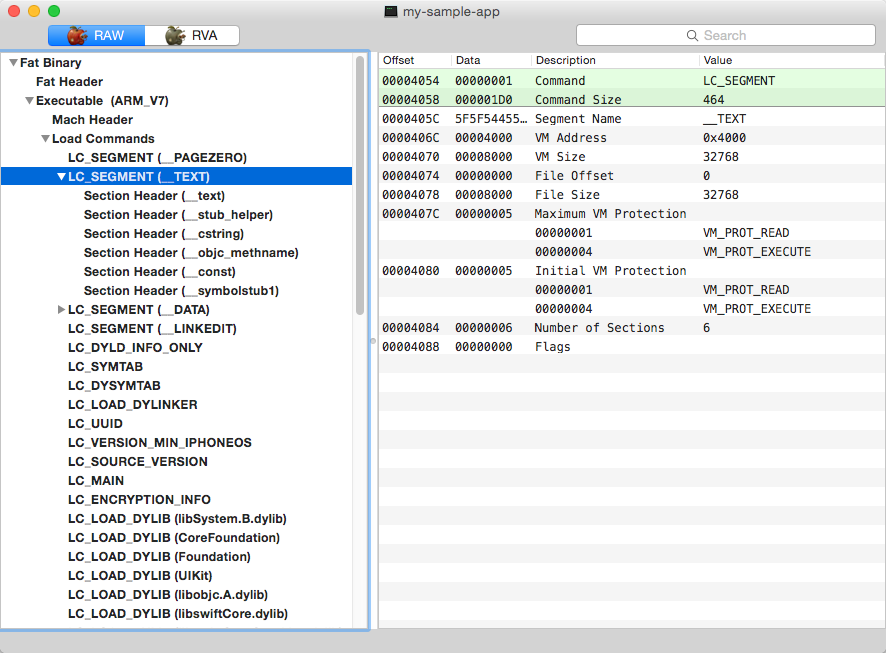
In the image above, you can see a lot of information about the chosen segment:
- Offset in the current executable
- Size
- Address
- Size of the region appointed for segment mapping
- Segment attributes
All segments consist of sections. A section is part of the segment that’s intended to store some specific type of content. For example, the __text section of the __TEXT segment contains executable code, and the __la_symbol_ptr section of the DATA segment contains a table of pointers to so-called lazy external symbols.
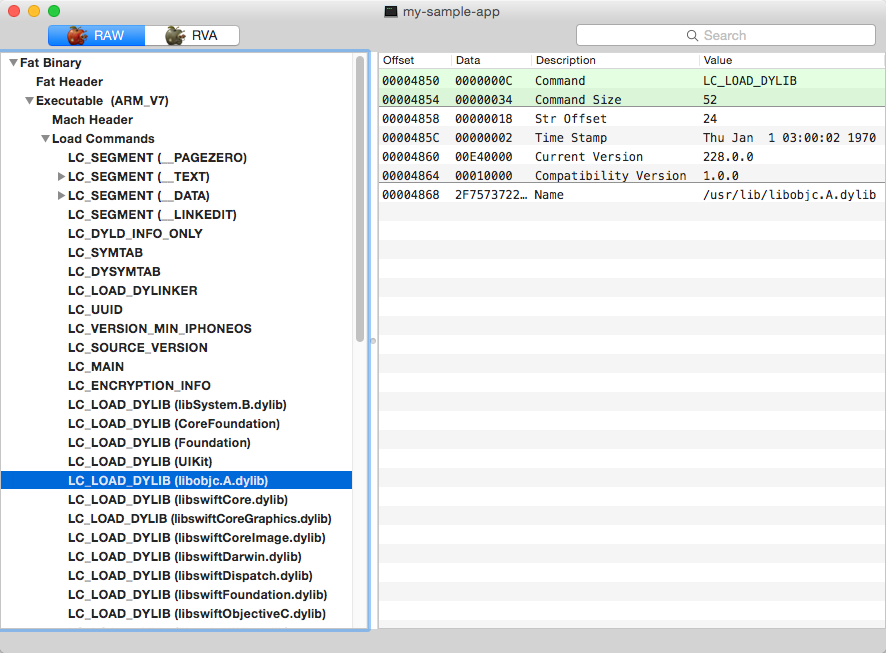
Every dynamic library dependency is described by a load command containing the path to the dynamic library binary file and its version.
In addition, load commands contain the following information critical for the operation of executable code:
- Location of symbol tables
- Location of import and stub tables
- Location of the table with information for the dynamic loader
The main symbol table contains all symbols used in the current executable. Every locally or externally defined symbol or even stub (which can be generated for an external call that executes through an import table) is mentioned here. This table is divided into three parts, showing whether the symbol is debug, local, or external. Every entry in the main symbol table represents a particular part of the executable code by specifying the offset of its name in the string table, type, section ordinal, and other type-specific information.
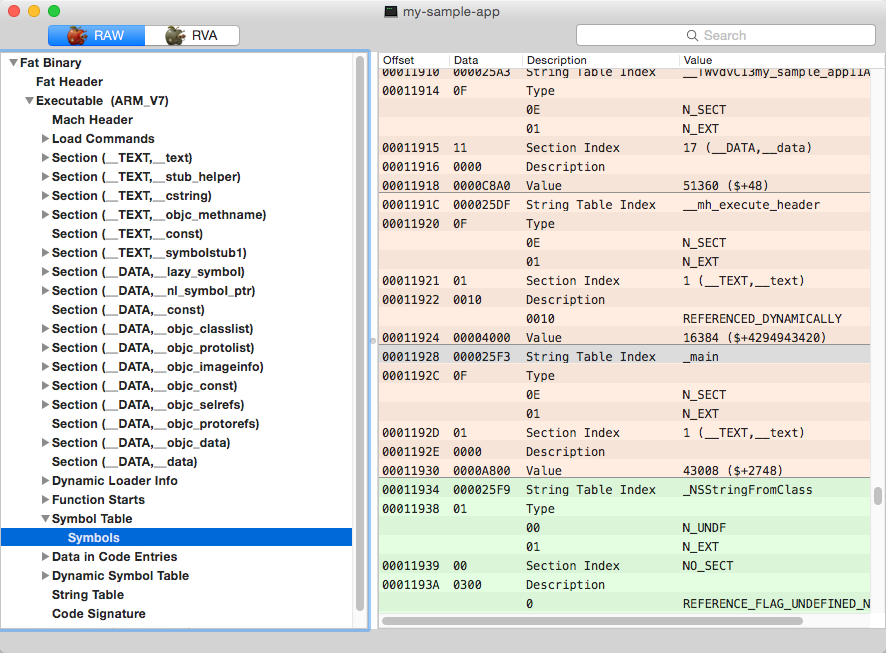
A string table contains the names of symbols defined in the main symbol table. There’s also a dynamic symbol table that links import table entries to the appropriate symbol. In addition, there’s one more table that contains information used by the dynamic loader for every external symbol.
Read also
How to Reverse Engineer Software (Windows) the Right Way
Analyze your product’s security, recover lost documentation, and improve your legacy software with the help of our guide on reverse engineering.

Code signature data
A code signature can also be rather helpful when reverse engineering a binary. While a code signature is one of the poorly documented (but still open-source) parts of an executable, its content can be displayed by means of the codesign tool (see the image below).
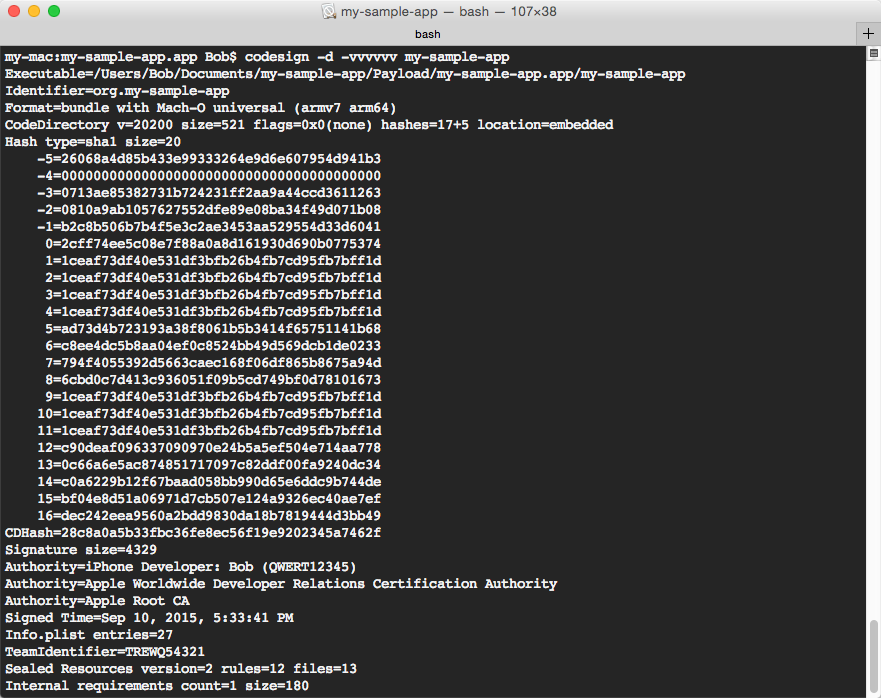
Code signature data contains a number of important elements:
- Code directory
- Сode signing requirements
- Description of sealed resources
- Entitlements
- Code signature
Let’s take a closer look at each element.
The code directory is a structure that contains miscellaneous information (hash algorithm, table size, size of code pages, etc.) and a table of hashes. The table itself consists of two parts: positive and negative.
The positive part of the table of hashes contains hashes of executable code pages.
The negative part optionally contains hashes of such code signature parts as code signing requirements, resources, and entitlements, as well as a hash of the Info.plist file.
Code signing requirements, resources, and entitlements are just bytestreams of the appropriate files located inside a bundle.
The code signature is an encrypted code directory represented in CMS format.
Architectures
One more thing your team should pay special attention to before they reverse engineer an iOS app is the architecture it was designed for. Mobile devices use ARMv7, ARMv7s, ARMv8-A, ARMv8.2-A, ARMv8.3-A, and ARM64 CPUs.
Knowledge of instruction sets is important when reverse engineering algorithms. In addition, it’s good to be familiar with calling conventions and some things specific to an ARM-based system on a chip (SoC), like thumb mode and opcodes format.
Caches
Nowadays, all system frameworks and dynamic libraries are merged into a single file called the shared cache. This file is located at the following address: /System/Library/Caches/com.apple.dyld/.
These are the basic things your team needs to know before doing any reverse engineering. Now, let’s talk about the best reverse engineering software for iOS that can help your team on this journey.
Read also
Restoring Classes – Useful Tips for Software Reverse Engineers
Learn how to restore classes in your source code with the help of reverse engineering.
iOS reverse engineering tools
Below are standard command-line iOS reverse engineering tools. They are available out of the box on macOS:
- lldb is a powerful debugger used in Xcode. Your team can use this tool to reverse engineer and debug code written in C++, Objective-C, and C. lldb allows reverse engineers to debug code on both actual iOS devices and simulators.
- otool is a console tool for browsing and editing in mach-o executables. It displays specified parts of libraries and object files.
- nm is a console tool for browsing names and symbols in mach-o executables.
- codesign is a useful tool for working with code signatures. It provides comprehensive information on code signatures and allows for creating and manipulating them.
In addition, there are several third-party reverse engineering utilities:
- IDA
- MachOView
- Class-dump
- Hopper
- Dsc_extractor
- Ghidra
Let’s look closer at each of these utilities.
IDA (Interactive DisAssembler) is one of the most famous and widely used reverse engineering tools. IDA is a disassembler and debugger that’s suitable for performing complex research of executables. It’s a cross-platform tool that runs on macOS, Windows, and Linux.
IDA can be used for disassembling software designed for macOS, Windows, and Linux platforms. The program has a free evaluation version with limited functionality. There’s also a paid version, IDA Pro, which supports a wider range of processors and plugins. If you want to learn more about this tool, check out our article about extending IDA’s capabilities.
MachOView is a utility that works similarly to the otool and nm console tools. The key difference is that MachOView has a GUI, so your team can browse the structure of mach-o files more comfortably. In fact, MachOView was used to make most of the screenshots you see in this article. MachOView is free to use, but unfortunately, it isn’t always stable.
Class-dump is a free command-line utility for analyzing the Objective-C segment of mach-o files. With class-dump, your team can get pretty much the same information as from otool but in the form of standard Objective-C declarations. In particular, class-dump creates declarations for classes, categories, and protocols.
Hopper is an interactive tool for disassembling, decompiling, and reverse engineering iOS mobile apps. Similarly to IDA, Hopper has a free version with a limited set of features in addition to a paid version. Hopper was designed for Linux and macOS and works best for retrieving Objective-C specific information from the analyzed binary.
Dsc_extractor is Apple’s own open-source tool for extracting libraries and frameworks from dyld_shared_cache. When extracting data, the utility saves the locations and original names of all extracted objects.
Ghidra is an open-source reverse engineering framework provided by the NSA. It supports macOS, Windows, and Linux. Ghidra can be used as a decompiler and a tool for performing tasks such as assembling/disassembling, graphing, and scripting code. It can be customized with scripts and plugins written in Java or Python.
Frida is a dynamic instrumentation toolkit widely used as a reverse engineering tool for analyzing and manipulating software at runtime. Unlike traditional static analysis tools such as disassemblers and decompilers, Frida focuses on dynamic analysis by injecting code into the target process, allowing real-time interaction and modification of the running application.
Read also
9 Best Reverse Engineering Tools for 2023 [Updated]
Learn about the main reverse engineering programs we rely on in our work and get insights from our practical examples of their usage.
Specifics of programming languages
Now, let’s look at some of the specifics of reverse engineering code written in particular programming languages. Within this article, we focus on the peculiarities of reverse engineering solutions written in Objective-C and Swift.
How to reverse engineer Objective-C code
Objective-C is commonly used for developing iOS applications. It relies on a specific C runtime, which somewhat simplifies the process of reverse engineering for iOS apps.
Let’s consider simple code from an iOS application:
NSNumber *number = [[NSNumber alloc] initWithInt:1];When this code is compiled and later decompiled, it transforms into a lower-level format, which looks something like this in C:
int v1; int v2;
v1 = objc_msgSend(_OBJC_CLASS_$_NSNUMBER, "alloc");
v2 = objc_msgSend(v1, "initWithInt", 1);This snippet demonstrates the basics of object allocation and messaging in Objective-C — key concepts for reverse engineering Objective-C iOS apps. Every method call in Objective-C is performed via the runtime using the following core function:
id objc_msgSend(id self, SEL op, …);In this function:
- The first argument,
self, is a pointer to an object (typically derived fromNSObject). - The second argument,
op, is a pointer to a selector, which represents the method name as a unique identifier.
These two arguments are mandatory. Specifying other arguments is optional but may be required for a particular method.
The Objective-C runtime operates with two main types for method lookup: SEL (selector) and IMP (implementation). In this example, initWithInt is the selector, while the implementation is a pointer to a C function, which looks like this:
id -[NSNumber initWithInt:](id self, SEL _cmd, int value) { } As we can see, this is essentially a standard C function with a unique Objective-C naming convention. The “+” or “-” in the name indicates a class method or instance method, respectively. The objc_msgSend function searches for the implementation associated with a given selector and calls it with the specified arguments (self and _cmd).
For iOS reverse engineering, this brings about two key nuances:
- Indirect method calls. Because method calls in Objective-C aren’t directly referenced but are instead identified by selectors, your team needs to understand selector lookups to trace method calls.
- Human-readable selectors. All selector names reside in the __objc_methname section of the __TEXT segment. These selectors reveal the method names, helping developers understand app functionality and locate points of interest within the executable when reverse engineering an iOS app.
How to reverse engineer Swift code
Swift and Objective-C share common runtime components for iOS. Moreover, compiled Swift classes have the same structure as Objective-C classes, each inheriting from SwiftObject. But despite this, reverse engineering Swift code differs from reverse engineering Objective-C.
Modern features of the Swift language, such as strict typing, name mangling, and the absence of a message-sending approach, distinguish Swift from the more dynamic Objective-C. As a result, reverse engineering programs written in Swift are more similar to reverse engineering programs written in C++.
In this section, we briefly cover key challenges that a reverse engineer encounters when analyzing iOS applications written in Swift. We will use this code as our starting point:
class Animal {
func sound() -> String {
return "Generic Sound..."
}
}
class Dog: Animal {
override func sound() -> String {
return "Woof woof woof arf"
}
func play(with name: String, times: Int, toy: String, outdoor: Bool, day: String, mood: String) {
print("\(name) very likes to play \(times) times with \(toy) outside: \(outdoor) on \(day) feeling \
(mood).")
}
}
let myDog = Dog()
print(myDog.sound())
myDog.play(with: "Buddy", times: 3, toy: "ball", outdoor: true, day: "Saturday", mood: "happy")Impact of compiler optimization
The different optimization techniques applied during compilation can affect how the assembly code looks when a reverse engineer tries to analyze it. Let’s explore how these factors affect reverse engineering.
For instance, this is what the assembly representation of the Dog.sound() function looks like with no optimization applied:
; dog_swift_reversing.Dog.sound() -> Swift.String
EXPORT _$s19dog_swift_reversing3DogC5soundSSyF
_$s19dog_swift_reversing3DogC5soundSSyF ; DATA XREF: __data:0000000100008250↓o
var_8 = -8
var_s0 = 0
SUB SP, SP, #0x20
STP X29, X30, [SP, #0x10+var_s0]
ADD X29, SP, #0x10
STR XZR, [SP, #0x10+var_8]
STR X20, [SP, #0x10+var_8]
ADRL X0, aWoofWoofWoofAr ; "Woof woof woof arf"
MOV W8, #0x12
MOV X1, X8
MOV W8, #1
AND W2, W8, #1
BL _$sSS21_builtinStringLiteral17utf8CodeUnitCount7isASCIISSBp_BwBi1_tcfC
LDP X29, X30, [SP, #0x10+var_s0]
ADD SP, SP, #0x20
RET
; End of function Dog.sound()As a result of standard compilation, the output includes symbols that provide clear function names and metadata to the reverse engineer.
However, if symbols were stripped during compilation (using the strip option), the function name and its intent might remain anonymous, as in this code sample below:
sub_1000036B4: ; CODE XREF: sub_1000033A8+68↑p
; DATA XREF: __data:0000000100008250↓o
var_8 = -8
var_s0 = 0
SUB SP, SP, #0x20
STP X29, X30, [SP, #0x10+var_s0]
ADD X29, SP, #0x10
STR XZR, [SP, #0x10+var_8]
STR X20, [SP, #0x10+var_8]
ADRL X0, #aWoofWoofWoofAr ; "Woof woof woof arf"
MOV W8, #0x12
MOV X1, X8
AND W2, W8, #1
BL __SSS21_builtinStringLiteral17utf8CodeUnitCount7isASCIISSBp_BwBil_tcfC
LDP X29, X30, [SP, #0x10+var_s0]
ADD SP, SP, #0x20
RET
; End of function sub_1000036B4The function can also be inlined, as demonstrated here:
STR X0, [X8,#_$s9mydogsays5myDogAA0C0Cvp@PAGEOFF] ; myDog
ADRL X0, _$sS23_ContiguousArrayStorageCyypGMD ; demangling cache
BL _swift_instantiateConcreteTypeFromMangledName
MOV W1, #0x40 ; '@'
MOV W2, #7
BL _swift_allocObject
MOV X19, X0
ADRP X8, #xmmword_100003DF0@PAGE
LDR Q0, [X8,#xmmword_100003DF0@PAGEOFF]
STR Q0, [X0,#0x10]
ADRP X8, #_$sSSSN_ptr@PAGE
LDR X8, [X8,#_$sSSSN_ptr@PAGEOFF]
STR X8, [X0,#0x38]
MOV X8, #0x0000000000000012
ADRL X0, aWoofWoofWoofAr ; "Woof woof woof arf"
SUB X9, X9, #0x20 ; ' '
ORR X9, X9, #0x8000000000000000
STP X9, [X0,#0x20]
MOV W1, #0x20
MOV X2, #0xE100000000000000
MOV W3, #0xA
MOV X4, #0xE100000000000000Inlining mixes the function with the rest of the code, making it hard for a reverse engineer to identify its boundaries and thus understand what the code does.
When the assembly code isn’t clear due to inlining or symbol stripping, our reverse engineers pay attention to the use of certain constants, string literals, or the invocation of imported functions from other modules.
Inheritance from SwiftObject
As mentioned earlier, Swift classes inherit the structure of Objective-C classes, and as a result, they can still be seen in the __objc_classlist section. However, the __objc_classname and __objc_selrefs sections, which are useful for understanding the program logic, are absent. If optimizations are minimal and symbols are not stripped, the class description may still contain helpful information for reverse engineering:
_OBJC_CLASS_$_TtC19dog_swift_reversing3Dog __objc2_class <_OBJC_METACLASS_$_TtC19dog_swift_reversing3Dog>
; DATA XREF: __objc_classlist:0000000100004100↑o
_OBJC_CLASS_$_TtC19dog_swift_reversing6Animal, \ ; Dog
__objc_empty_cache, 0, \
_TtC19dog_swift_reversing3Dog_$classData.flags+2>
DCQ 2
DCQ 0x700000010
DCQ 0x1800000080
DCQ _$s19dog_swift_reversing3DogCMn ; nominal type descriptor for Dog
ALIGN 0x10
DCQ _$s19dog_swift_reversing3DogC5soundSSyF ; Dog.sound()
DCQ _$s19dog_swift_reversing3DogC4play4with5times3toy7outdoor3day4moodySS_SiSSSbS2StF ;Here, key class and method details like Dog.sound() and Dog_allocating_init() are still visible, making it easier to deduce the structure and functionality of the program.
However, if symbols are stripped or optimizations obscure the structure, key details are replaced with placeholders, as shown below:
_OBJC_CLASS_$_TtC9mydogsays3Dog __objc2_class <_OBJC_METACLASS_$_TtC9mydogsays3Dog, \
; DATA XREF: sub_100003AF4+8↑o
; __objc_classlist:00000001000040C0↑o
_OBJC_CLASS_$_TtCs12_SwiftObject, __objc_empty_cache, \ ; Dog
0, _TtC9mydogsays3Dog_$classData.flags+2>
DCQ 2
DCQ 0x700000010
DCQ 0x1800000080
DCQ unk_100003F34
DCQ 0
DCQ _swift_deletedMethodError
DCQ _swift_deletedMethodError
DCQ _swift_deletedMethodErrorIn this sample, class names and methods are obscured or replaced with placeholders like swift_deletedMethodError, significantly complicating reverse engineering. Without meaningful metadata, a reverse engineer must rely on indirect clues, such as memory layout or method offsets, to reconstruct the class structure and logic.
If a reverse engineer encounters a case similar to the first example, the class description can be interpreted as a structure. When a method is invoked via an offset, that offset can be treated as a structure field. For example:
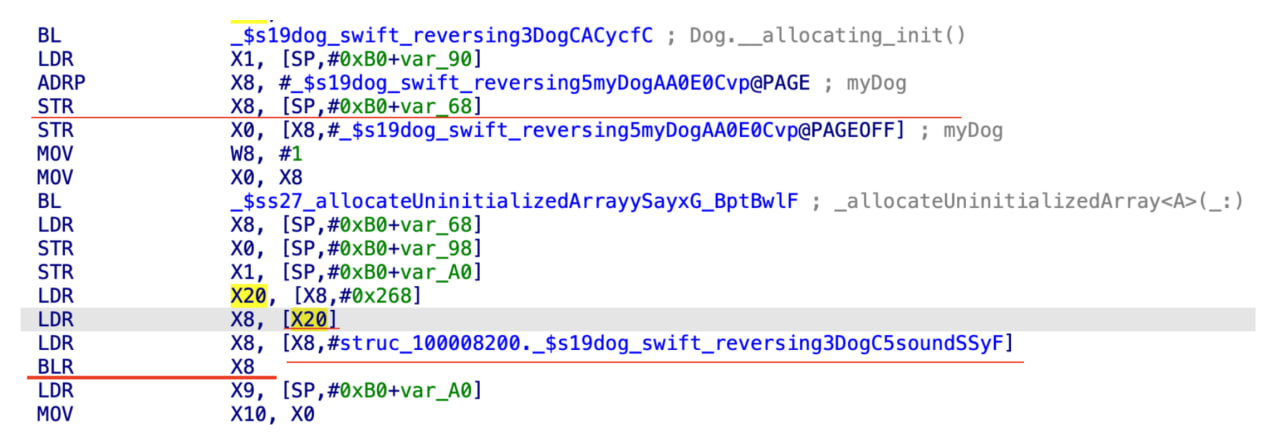
In this code, it is possible to deduce that x20 contains the self reference (on ARM64 architecture), and that offsets such as #0x268 represent method pointers within the class structure. This approach allows the reverse engineer to reconstruct the functionality of the class even when symbolic metadata is missing.
By relying on such patterns, reverse engineers can overcome the challenges imposed by stripped symbols and optimizations, though the process is manual and less reliable.
Name mangling
If symbols are not stripped or if imported names are used, they will appear in the code in a mangled form. To demangle these names, you can use the swift-demangle utility:
$ echo '$s19dog_swift_reversing3DogC5soundSSyF' | xcrun swift-demangle
dog_swift_reversing.Dog.sound() -> Swift.StringCalling convention
Swift uses its own calling convention, known as swiftcall. One of the differences from Objective-C, as noted earlier, is that Swift does not use the x0 register (on ARM64) or the rdi register (on x86-64) to pass the self reference. Instead, x20 (on ARM64) or r13 (on x86-64) is typically used. However, this behavior can vary depending on the level and type of optimization applied. In some cases, the self reference may not be used at all, particularly if the method does not modify the object and the class method being called is known at compile time.
Another interesting property of swiftcall is the direct placement of small objects into registers for passing as arguments or returning as a value.
For example, consider the disassembly for creating a Swift String:
ADRL X0, aBuddy ; "Buddy"
MOV W8, #5
MOV X1, X8
STR X1, [SP,#0xB0+var_58]
MOV W8, #1
STUR W8, [X29,#var_44]
AND W2, W8, #1
BL __$sSS21_builtinStringLiteral17utf8CodeUnitCount7isASCIISSBp_BwBi1_tcfC ;
LDUR W8, [X29,#var_44]
STUR X0, [X29,#var_38]
STUR X1, [X29,#var_18]Here are some things for a reverse engineer to pay attention to in this code:
- The String.init(_builtinStringLiteral:utf8CodeUnitCount:isASCII:) function is a wrapper (thunk) around the call to an Objective-C method. Thunks are commonly used in Swift to bridge differences between Objective-C and Swift calling conventions.
- Parameters for the thunk are passed through memory referenced by the x0, x1, and x2 registers.
- Results are returned using two registers (x0 and x1), which is specific to Swift’s convention.
Swift’s use of thunks and specific calling conventions can sometimes mislead decompilers. Consider the following decompiled code:
v9 = myDog;
v24 = String.init(_builtinStringLiteral:utf8CodeUnitCount:isASCII:)("Buddy");
v28 = v10;
v22 = String.init(_builtinStringLiteral:utf8CodeUnitCount:isASCII:)("ball");
v27 = v11;
v23 = String.init(_builtinStringLiteral:utf8CodeUnitCount:isASCII:)("Saturday");
v26 = v12;
v13 = String.init(_builtinStringLiteral:utf8CodeUnitCount:isASCII:)("happy");
v25 = v14;
(*(void (__fastcall **)(__int64, __int64, __int64, __int64, __int64, __int64, __int64, __int64, __int64,
__int64))(*(_QWORD *)v9 + offsetof(struc_100008200,
_$s19dog_swift_reversing3DogC4play4with5times3toy7outdoor3day4moodySS_SiSSSbS2StF)))(
v24,
v28,
3LL,
v22,
v27,
1LL,
v23,
v26,
v13,
v14);
swift_bridgeObjectRelease(v25);
swift_bridgeObjectRelease(v26);
swift_bridgeObjectRelease(v27);
swift_bridgeObjectRelease(v28);In this example, the decompiler represents calls like String.init(...) as high-level function calls, but in reality, these are bridged through a thunk to Objective-C.
However, the offsets and registers (x20 for self) clarify how the function call is structured in the compiled binary, enabling the reverse engineer to accurately interpret the code.
Now, let’s move to practical tips and techniques that can simplify the process of reverse engineering iOS apps.
Reverse engineering examples and tips
Below, we provide a list of short but helpful techniques that can make reverse engineering iOS apps a bit easier for your team.
Case 1. Reversing open-source code
Before reverse engineering anything, check out the Apple Open Source website. A lot of things are available as source code on this platform. For example, the structure of the Code Signature part of mach-o can be understood by inspecting the codesign tool, whose sources are publicly available.
Case 2. Getting an executable to reverse engineer
For iOS software, reverse engineering typically involves extracting an executable from an IPA file. An IPA file is essentially a zip archive with a specific structure, where the executable can be located within the Payload/*.app subdirectory of the archive. This executable can then be analyzed using various iOS-compatible reverse engineering tools.
In some cases, reverse engineering iOS applications may require access to additional system resources. Often, this is achieved on a jailbroken device, which allows more comprehensive access to app files and system frameworks. If jailbreaking isn’t an option, it’s still possible to retrieve certain files from the device filesystem through the Document Interaction functionality, which provides limited file access without jailbreaking.
Case 3. Reversing emulator binaries
If there’s no chance to get binary code from a device, there’s still a possibility to get it from an iOS simulator. The tricky part is that if the simulator is Intel-based, its code will differ from the iOS code on real devices, as the simulator runs on an x86 architecture, while real devices use ARM64.
Nevertheless, the interfaces of daemons and frameworks will be the same as on a true iOS device.
Related project
Device Firmware Reversing to Obtain the Screen Mirroring Protocol
Learn how Apriorit’s researchers reverse-engineered an original platform firmware to make it compatible with other platforms.
Case 4. Finding the cause of application-specific issues
If there’s some kind of application-specific issue we need to investigate, we can get a crash report and a stack trace. In such cases, we need to understand the common logic around the issue. This can look like a complicated task because of the private functions displayed in stack trace, such as ___lldb_unnamed_function. The universal way to locate such a private function using a disassembler or MachOView is to find its offset that correlates with the __text section. We can usually get the function address from trace, while the segment address can be found with the help of the debugger command:
(lldb) image dump sectionsA great hint for understanding the internal structure of an executable is using tracking strings. Function names can be often tracked by strings passed to the system log. The principal application delegate can be found by inspecting arguments of NS- or UIApplicationMain functions.
Case 5. Reverse engineering using private or internal functionality
Usually, we have a public API as a starting point, and thus we know the framework we should explore. In some cases, we can use debug symbols instead of a framework binary. We can find these symbols at ~/Library/Developer/Xcode/iOS DeviceSupport/.
It is expected that internals are not exported. With Objective-C code, even internal code can be executed using the low-level obj-c runtime. If it can’t be, then there’s a possibility to dump class declarations using otool or class-dump and use these internals without confusing the linker.
Case 6. Communicating with a daemon
A framework frequently appears to be a proxy between the application and a daemon. Examples of such client-server tandems are MobileInstallation.framework and installd. When someone makes a call to MobileInstallation.framework, it delegates most of the work to installd using rpc.
The first remote procedure call (rpc) that iOS uses is the mach interprocess communication facility. The second is cross-process communication (xpc), which also uses mach messages behind the scenes, though it’s much higher-level.
Xpc runs in a restricted environment by default. Any capabilities must be whitelisted by a set of entitlements; otherwise, privileged tasks aren’t permitted. This limitation is what often makes xpc hard to use and turns the low-level mach into a much better option.
Read also
Anti Debugging Protection Techniques with Examples
Get a list of simple and advanced techniques to protect your software from illegal reversing in our comprehensive guide!
Conclusion
Reverse engineering is a helpful approach developers can use for investigating and analyzing software code to research malware, fix software issues, ensure compatibility, simplify support for undocumented legacy code, and so on. To perform iOS app reverse engineering, your team needs to know the basic binary executable structure and have a set of tools for browsing and disassembling executables. For iOS solutions, you can use standard command-line tools available on macOS or third-party utilities.
At Apriorit, we have a dedicated team of researchers and mobile developers who can help investigate and improve your product. Get in touch with us to receive a preliminary estimate for your research project.
Need to learn how your app works?
Leverage our 20+ years of experience to understand your application’s inner workings and unlock more opportunities, stronger security, and better performance!
Have a question?
Ask our expert!
Program Manager


