 Skip to main content
Skip to main content
Action detection is one of the most challenging tasks in video processing. It can be useful in security systems and closed-circuit television (CCTV), facial emotion recognition software, sport event analytics, behavior observation, statistics gathering, etc.
In one of our recent projects, we were challenged with the task of detecting a particular human action in a high-resolution video. In this article, we talk about the importance of finding a balance between accuracy and performance, challenges we faced with dataset preparation and network configuration, and how these problems can be solved.
Contents:
Using DNNs for action detection
Deep learning is an area of machine learning that uses feature learning techniques instead of task-specific algorithms. It uses multi-layered artificial neural networks that work similarly to neural networks in the human brain. But unlike the brain, a neural network is divided into separate layers each with a defined direction of data processing. A network with more than two layers is called a deep neural network (DNN).
A DNN can achieve human-like accuracy in such tasks as image classification, object detection and classification, speech recognition, handwriting recognition, and computer vision. With proper training, a neural network can perform some tasks even more accurately than a human. For example, Google’s LYNA algorithm is 99% accurate in detecting cancer — a level of accuracy hard to achieve for a doctor.
A convolutional neural network (CNN) is a subtype of DNN, a multilayered algorithm that resembles the work of the visual cortex. CNNs are mostly used for image, video, and language processing. The region-based convolutional neural network (R-CNN) is a new category of CNN created specifically for object detection. There are several types of R-CNN neural networks (Fast R-CNN, Faster R-CNN, Mask R-CNN, etc.) created for different image processing tasks.
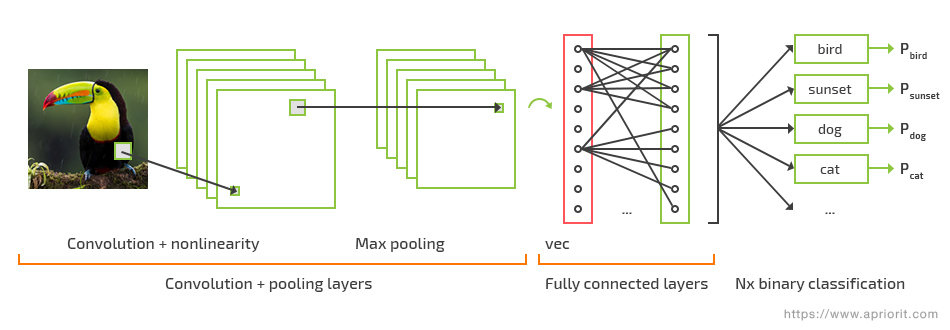
A convolutional neural network algorithm
The development of video processing solutions has become one of the most popular use cases for convolutional neural networks. A CNN can recognize emotions, gestures, speech, and handwriting, detect and classify objects, and detect and recognize actions in video.
During our project, we defined action detection as classifying motions based on a series of regions of interest (ROIs) for an unbroken sequence of images.
However, there are many challenges in using CNNs for recognizing and detecting actions in video. Recently, we worked on a project where the major goal was to detect a specific human action in a video stream. While working on this project, we faced a few major challenges:
- Finding a balance between accuracy and performance
- Preparing a dataset with similar parameters to the one the network was supposed to be working with
- Choosing a relevant CNN for the task and configuring it
Let’s find out how to solve these issues by means of deep neural networks.
Unlock the power of action detection!
Enhance your software with advanced video processing functionality by entrusting development tasks to Apriorit’s experts in AI & ML.
Balancing accuracy and performance
Nowadays, detecting actions remains one of the most challenging tasks in terms of both accuracy and performance.
For detecting actions, it’s crucial to deal with spatial features of images (what object recognition methods do) as well as temporal ones.
In terms of image processing, identifying temporal features means determining changes in other features over some period of time. For videos, this could be a timespan or a certain sequence of frames. Identifying spatial features means determining image properties (grayscale, pixel locations, etc.).
As for performance, it needs to be taken into account that video processing solutions are often implemented for trimmed, untrimmed, and real-time videos. The problem is that today’s video codecs can produce videos with very high frame rates and resolutions (FullHD, UHD, etc.). Basically, the higher the quality of a video, the longer it takes to process the data. Therefore, high-quality videos become a real challenge for projects (such as action detection) where real-time or near real-time data processing is required.
The trade-off between accuracy and processing speed is especially noticeable in action detection because while a higher quality of video often means better accuracy, such videos usually take more time to process.
Our research showed that this problem can be solved by a low-level language implementation of a neural network such as Faster R-CNN. This region-based convolutional neural network is designed to provide fast data processing by moving region proposal calculations to another pretrained feature extractractor called a region proposal network (RPN). This way, Faster R-CNN performs only detection calculations.
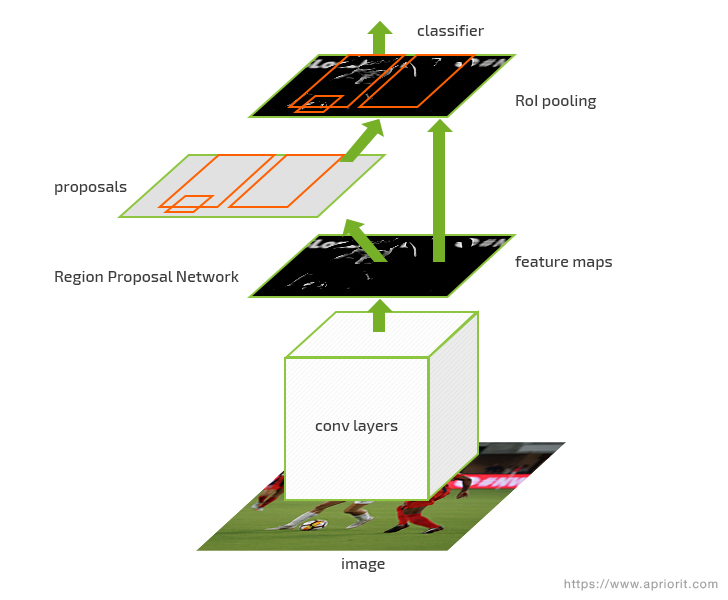
Faster R-CNN architecture
Faster R-CNN can be implemented with frameworks like Caffe2 or OpenCV, along with the TensorRT Inference Server and the best GPU setup possible. We used Caffe2 for our calculations.
Related project
Building an AI-based Healthcare Solution
Discover how Apriorit helped a client create a cutting-edge AI-based system for healthcare, saving doctors’ time and achieving 90% precision and a 97% recall rate detecting and measuring follicles.

Preparing the dataset
Training a neural network model requires massive amounts of data. There are quite a few good datasets for image classification and detection, such as MS-COCO and ImageNet.
There are also a few ready-to-use datasets for detecting actions, such as UCF101 and THUMOS.
The problem is, these datasets are designed for action classification and mostly consist of low-resolution trimmed videos of certain actions. Since we were challenged to accurately detect a particular human action in high-resolution high frame rate videos, there was a need for additional training on high-resolution videos of this action.
With no ready-to-use training data for our task, we had to prepare our own dataset. Training data is prepared by making annotations. These annotations are often made with tools such as GEDI or VGG Image Online Annotator. Initial research showed that we needed to consider both spatial and temporal features of training data.
First, we focused on spatial features, since there are a lot of well-trained feature extractors at our service. Fortunately, they’re also good at detecting people, and that was what we needed. We used the popular state-of-the-art MS-COCO dataset on the pretrained Mask R-CNN framework to generate ROIs on every frame of the video.
Then, we investigated ways to annotate actions and found that UCF101 annotations consist of ROIs and action annotations in the form of a frame span using XML format:
<object framespan="1:64" name="human">
<attribute name="Location">
<data:bbox framespan="1:1" height="47" width="27"
x="131" y="68"/>
...
<data:bbox framespan="64:64" height="85" width="34"
x="153" y="83"/>
</attribute>
<attribute name="action">
<data:bvalue framespan="1:32" value="false"/>
<data:bvalue framespan="33:64" value="true"/>
</attribute>
</object>This XML code describes an object that performs an action. The object’s attributes represent its locations and actions in every frame where the object occurs.
Location data for annotations were obtained from Mask R-CNN; we used a custom script that skipped masks and dumped ROIs in a file with frame annotations. In order to support action detection for multiple humans in a single frame, we used this format as our starting point and modified it with unique identificators.
Read also
Navigating AI Image Processing: Use Cases and Tools
Looking to streamline your image processing? Find out how to efficiently use AI for this task. Apriorit’s specialists share common use cases, helpful tools and technologies, challenges to look for, and ways to overcome them.

Configuring the network
For our project, we implemented Faster R-CNN, even though Mask R-CNN is considered superior to Faster R-CNN in terms of accuracy. We had two major reasons for choosing Faster R-CNN over Mask R-CNN:
- Faster R-CNN has better performance
- We had no need for masks in our project
Adapting the Faster R-CNN architecture from object recognition to action detection required a significant amount of customization, however.
Inspired by research on multi-region two-stream R-CNN for action detection, we implemented a custom logic to combine spatial and temporal features from our dataset annotation into so-called tubes.
Tubes are three-dimensional structures that consist of ROIs. Xiaojiang Peng and Cordelia Schmid, the researchers who published the paper that inspired us, used the Viterbi algorithm to generate these tubes for frames. However, because of the nature of the action we needed to detect, we decided to use a simpler approach. We used approximated coordinates for all ROIs in a sequence, which led to fewer calculations. In the current project, we didn’t compare these two methods.
Also, we implemented scripts for training on frame sequences of different lengths.
In contrast to the original Faster R-CNN, we redesigned our network to process sequences of frames and detect only two classes (background + action). This was achieved by modifying the prototxt files of the Faster R-CNN solution. These files are used in Caffe2 to describe each layer of the neural network. A typical layer description in these files looks like this:
layers {
bottom: "data"
top: "conv1_1"
name: "conv1_1"
type: CONVOLUTION
convolution_param {
num_output: 64
pad: 1
kernel_size: 3
}
}The bottom and top attributes of the layer represent its connections with other layers. The type attribute represents actions performed by the current layer, which is a convolution layer connected with the first input layer (the bottom attribute). It has 64 output neurons that each serve as an input for the next connected layer (the top attribute).
Additional testing showed that pretraining the network on trimmed low-resolution images had no significant impact on detection accuracy. This may be due to the significant difference between the features acquired by the DNN during the training process on low-resolution and high-resolution videos.
Conclusion
The ability to detect and recognize specific human actions in video streams or recordings shows huge potential in many areas, from sports analytics to cybersecurity and surveillance systems. However, in order to implement action detection functionality, you need to consider that:
- to improve accuracy, you need to take advantage of spatial and temporal features;
- an ROI-based neural network architecture needs to be merged into tubes to represent an action (separate ROIs don’t mean that any action occurs);
- training requires the use of data with a resolution similar to that which your network is supposed to work with;
- if high performance is the priority for your project, you shouldn’t use features you don’t need, as any extra calculations significantly influence performance with high-quality video.
With the approach we’ve described in this article, we achieved 63 percent action detection accuracy at the first testing stages. Adding new training data to the dataset and further network fine-tuning may lead to even better results.
At Apriorit, we have professional AI & ML development teams ready to assist you with projects of any complexity.
Bring the future to your project!
Leverage Apriorit’s expertise in AI & ML development to ensure a balance between the accuracy and performance of your video processing solution.
Have a question?
Ask our expert!
R&D Delivery Manager


