 Skip to main content
Skip to main content
Artificial intelligence (AI) opens new possibilities in the field of image processing. Leveraging the capabilities of machine learning (ML) and AI models, businesses can automate repetitive tasks, increase the speed and accuracy of image analysis, and efficiently tackle complex computer vision tasks.
To get the most out of this evolving technology, your development team needs to have a clear understanding of what they can use AI for and how.
In this article, we cover the essentials of AI image processing, from core stages of the process to the top use cases and most helpful tools. We also explore some of the challenges to be expected when crafting an AI-based image processing solution and suggest possible ways to address them.
This article will be useful for technical leaders and development teams exploring the capabilities of modern AI technologies for computer vision and image processing.
Contents:
- What is AI image processing?
- How does AI image processing work?
- Common use cases for AI in image processing
- Open-source libraries for AI-based image processing
- Machine learning frameworks and image processing platforms
- Image processing datasets for AI solutions
- Neural networks for image processing
- Challenges of processing images with AI
- Conclusion
What is AI image processing?
Generally speaking, image processing is manipulating an image in order to enhance it or extract information from it. Today, image processing is widely used in medical visualization, biometrics, self-driving vehicles, gaming, surveillance, law enforcement, and other spheres.
AI-powered image processing refers to applying the latest AI advancements to analyze and extract information from digital images or to create new images. The most common tasks it can be applied to include:
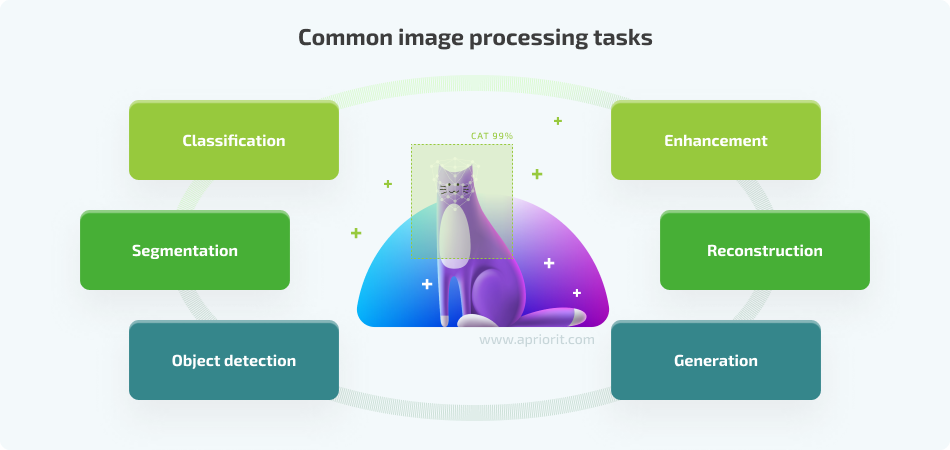
- Classification — Classifying images or labels assigned to images based on one or several criteria
- Segmentation — Dividing an image into separate groups of pixels (segments) based on predefined criteria
- Object detection — Finding and identifying objects within an image based on specified features
- Enhancement — Improving the quality of a processed image, usually using techniques like noise reduction, color correction, contrast adjustment, and so on
- Reconstruction — Repairing a damaged image, usually by removing artifacts and noise
- Generation — Creating new synthetic images based on other images or a text prompt
Ready to revolutionize your business with AI-driven solutions?
Partner with us to harness the power of artificial intelligence development services for your organization.
How does AI image processing work?
Machine learning and artificial intelligence can help with a wide variety of image processing tasks. AI-based image processing typically includes six major stages:
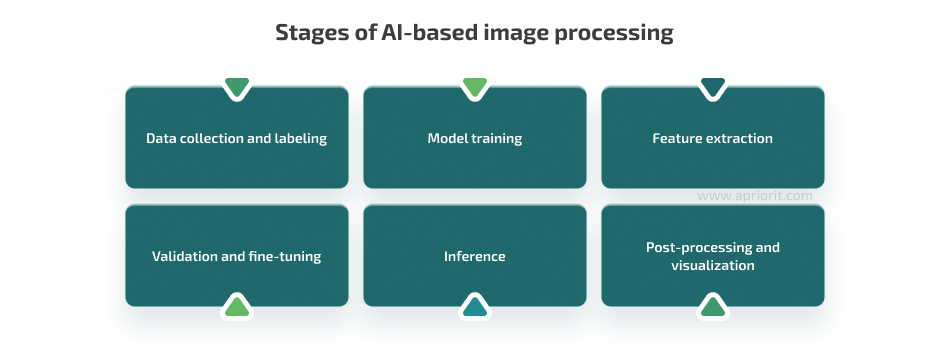
- Data collection — To train an AI model, lots of relevant, high-quality, and (usually) properly labeled data is necessary. Your development teams can work with the data you have or use ready image datasets.
- Model training — Using the prepared dataset, an AI model (typically a convolutional neural network) is trained to recognize features and patterns in the images associated with provided labels.
- Feature extraction — Once trained, the model can extract relevant features from previously unprocessed images.
- Validation and fine-tuning — Using a separate dataset and user feedback, developers can validate and fine-tune the model’s accuracy. At this stage, it’s important to prevent overfitting the model, as it may reduce its accuracy.
- Inference — The trained and fine-tuned model processes new images and tries to make predictions based on previously learned patterns.
- Post-processing and visualization — The model refines image processing results and visualizes the output.
Depending on the type of AI model and the tasks you have for it, there can be other stages like image compression and decompression or object detection.
Common use cases for AI in image processing
When it comes to working with digital images, AI can serve various purposes, including:
- Visualization — Represent processed data in an understandable way (for instance, giving visual form to objects that aren’t visible)
- Image sharpening and restoration — Improve the quality of processed images
- Image retrieval — Help with searching for images that are identical or similar to a given image
- Object measurement — Measure specific objects in an image
- Pattern recognition — Distinguish and classify objects in an image, identify their positions, and understand the scene
- Anomaly detection — Identify any deviations from the established norm in processed images
Depending on the industry, these purposes can transform into various use cases:
- Сybersecurity — AI-powered facial recognition is widely used for identity verification and access management. For example, surveillance solutions rely on anomaly detection algorithms to automate the monitoring and analysis of camera footage.
- Healthcare — AI models analyze medical scans and images, detecting anomalies that can be hard to spot with the human eye and assisting doctors with diagnosis.
- Entertainment — AI-powered solutions are widely applied for tasks ranging from editing to generating graphics, helping artists create realistic visual effects and animations.
- Manufacturing — AI allows for quick identification of quality issues and otherwise undetectable product defects.
- Retail — AI-powered models are helpful with image-based product searches and analysis of customer movement patterns.
- Automotive — AI plays a crucial role in advanced driver assistance systems and the operation of autonomous vehicles. AI algorithms recognize objects on the road and help to determine a vehicle’s position in space, among other things.
The range of tasks you want your AI solution to perform may also affect your choice of suitable technologies and tools. In the following sections, we overview four main categories of tools your team will need when working on AI-powered image processing solutions:
- Open-source libraries
- Machine learning frameworks
- Image datasets
- Neural networks
Read also
Artificial Intelligence in the Automotive Industry: 6 Key Applications for a Competitive Advantage
Explore key uses of AI and machine learning for the automotive industry, from the core tools you can use for building AI-powered automotive solutions to the main challenges you should expect along the way.

Open-source libraries for AI-based image processing
Computer vision libraries contain common image processing functions and algorithms. There are several open-source libraries your development team can use when building AI image processing and computer vision features:
- Open Source Computer Vision Library (OpenCV) is a popular computer vision library that includes various modules for tasks like machine learning, image processing, and object detection. AI engineers use OpenCV to acquire, compress, enhance, restore, and extract data from images. The library comes with C++, Java, MATLAB, and Python interfaces and supports all popular desktop and mobile operating systems.
- Visualization Library is C++ middleware for 2D and 3D applications based on the Open Graphics Library (OpenGL). This toolkit allows for building portable and high-performance applications for Windows, Linux, and macOS systems.
- VGG Image Annotator (VIA) is a web application for manual object annotation. It can be installed directly in a web browser and used for annotating detected objects in images, audio, and video records. VIA is easy to work with, doesn’t require additional setup or installation, and can be used with any modern browser.
- Pillow/PIL is a fork of the Python Imaging Library (PIL), an open-source library for performing basic image processing tasks. Using this library, AI developers can process, rescale, and save images in different formats.
- Scikit-learn is an open-source Python library built on NumPy, SciPy, and matplotlib. Your development team can use this machine learning library to preprocess images, classify them, extract features, and reduce dimensionality.
- Detectron2 is a next-generation library that can help AI developers build advanced computer vision models, specifically for object detection and instance segmentation.
Along with fitting libraries, it’s important to choose the right machine learning framework for your AI product’s development.
Read also
Enhancing the Security and Performance of a Virtual Application Delivery Platform
AI revolutionizes emotion recognition technology, making it more accurate and fast. Learn how you can use AI for your benefit!
Machine learning frameworks and image processing platforms
If using simple AI algorithms isn’t enough for the project at hand, your development team can build custom models. Special platforms and frameworks can make this development process a bit faster and easier. Below, we take a look at some of the most popular:

- TensorFlow by Google is a popular open-source framework that supports machine learning and deep learning. AI developers can use TensorFlow to create and train custom deep learning models. The framework also includes a set of libraries suitable for AI image processing projects and computer vision applications.
- PyTorch is an open-source deep learning framework initially created by the Facebook AI Research (FAIR) lab. This Torch-based framework has Python, C++, and Java interfaces. Among other things, PyTorch can be used for building computer vision and natural language processing applications.
- Keras 3 (previously known as Keras Core) is a multi-backend deep learning framework that supports JAX, TensorFlow, and PyTorch. This framework helps design, train, and deploy models for computer vision and image processing, natural language processing, audio processing, and time series forecasting.
- MATLAB is an abbreviation for matrix laboratory. It’s the name of both a popular platform for solving scientific and mathematical problems and a programming language. MATLAB provides an Image Processing Toolbox (IPT), including multiple algorithms and workflow applications for AI-based image analysis, processing, visualization, and algorithm development. MATLAB IPT allows for automating common image processing workflows. Tasks this toolbox can help tackle include noise reduction, image enhancement, image segmentation, and 3D image processing. Many IPT functions support C/C++ code generation, so they can be used for deploying embedded vision systems and desktop prototyping.
- Microsoft Computer Vision is a cloud-based service provided by Microsoft that provides access to advanced algorithms for image processing and data extraction. Microsoft Computer Vision allows for analyzing an image’s visual features and characteristics, moderating image content, and extracting text from images.
- Google Cloud Vision, part of the Google Cloud platform, offers a set of image processing features. It provides an API for integrating features such as image labeling and classification, object localization, and object recognition. Cloud Vision allows for using pre-trained machine learning models or creating and training custom AI for image processing.
- Google Colaboratory (Colab) is a free cloud service for developing deep learning applications from scratch. Colab makes it easier to use popular libraries and frameworks such as OpenCV, Keras 3, and TensorFlow when developing an application for image processing using AI. Google Colab is based on Jupyter Notebooks, enabling AI developers to comfortably share their knowledge and expertise. In contrast to similar services, Colab provides free GPU resources.
Read also
How to Use Google Colaboratory for Video Processing
Get to leverage machine learning and AI capabilities for image recognition and video processing tasks with our extensive guide to working with Google Colaboratory.
Image processing datasets for AI solutions
In addition to different libraries, frameworks, and platforms, your development team will also need a large database of images to train and test your model.
There are several open databases containing millions of tagged images for training custom machine learning applications and algorithms. Some popular free databases for AI image processing are:
A custom dataset is often necessary for developing niche, complex image processing solutions such as a model for detecting and measuring ovarian follicles in ultrasound images.
Building a quality custom dataset, however, is a challenging and resource-hungry process. Your team will need to gather or create large volumes of relevant images, properly label and annotate them, and make sure that the resulting dataset is well-balanced and free of biases.
At Apriorit, we often assist our clients with expanding and customizing an existing dataset or creating a new one from scratch. In particular, using various data augmentation techniques, we ensure that your model will have enough data for training and testing.
Read also
Top LLM Use Cases for Business: Real-Life Examples and Adoption Considerations
Maximize the benefits of adopting an LLM. Use our analysis to determine exactly how and why you should leverage this technology, as well as which training approach to apply for your LLM.

Neural networks for image processing
Neural networks or AI models are responsible for handling the most complex image processing tasks. Choosing the right neural network type and architecture is essential for creating an efficient artificial intelligence image processing solution.
Below, we overview several popular types of neural networks and specify the tasks they’re most suitable for within the computer vision and image processing domains:
Convolutional neural networks
Convolutional neural networks (ConvNets or CNNs) are a class of specialized deep learning networks for AI image processing. However, CNNs have been successfully applied to various types of data — not only images.
Neurons in these networks and neurons in the human brain are similarly organized and connected. In contrast to other types of neural networks, CNNs require fewer preprocessing operations. Plus, while CNNs can benefit from hand-engineered filters, they can also learn the necessary filters and characteristics during training.
There are different subtypes of CNNs, including region-based convolutional neural networks (R-CNN), which are commonly used for object detection.
CNNs are multilayered neural networks that include input and output layers as well as a number of hidden layer blocks which consist of:
- Convolutional layers — Filter the input image and extract specific features such as edges, curves, and colors
- Pooling layers — Improve the detection of unusually placed objects
- Normalization (ReLU) layers — Improve network performance by normalizing the inputs of the previous layer
- Fully connected layers — Connect the neurons between two different layers of a CNN in order to analyze and learn the function of features extracted by the network’s convolutional layer
All CNN layers are organized in three dimensions (weight, height, and depth) and have two components:
- Feature extraction — The CNN runs multiple convolutions and pooling operations to detect features it will use for image classification.
- Classification — Using extracted features, the network algorithm attempts to predict what the object in the image could be with a calculated probability.
Common tasks for CNNs are image classification and image recognition. Popular CNN architectures include AlexNet, ZFNet, Faster R-CNN, GoogLeNet/Inception, and YOLOv3.
How do CNNs work in practice?
Mask R-CNN is a Faster R-CNN-based deep neural network for separating objects in a processed image or video. This neural network works in two stages:
- Segmentation — The neural network processes an image, detects areas that may contain objects, and generates proposals.
- Generation of bounding boxes and masks — The network calculates a binary mask for each class and generates the final results based on these calculations.
This neural network model is flexible, adjustable, and provides better performance compared to similar solutions. However, Mask R-CNN struggles with real-time processing, as this neural network is quite heavy and the mask layers add a bit of performance overhead, especially compared to Faster R-CNN.Mask R-CNN remains one of the best solutions for instance segmentation. At Apriorit, we have applied this neural network architecture and our image processing skills to solve many complex tasks, including processing medical image data and medical microscopic data. We’ve also developed a plugin that improves the performance of this neural network model up to ten times thanks to the use of NVIDIA TensorRT technology.
Read also
Improving the Performance of Mask R-CNN Using TensorRT
Get expert advice on ways to improve Mask R-CNN performance six to ten times and bring your AI image processing routines to the next level.
Fully convolutional networks
In contrast to a CNN, a fully convolutional network (FCN) has a convolutional layer instead of a regular fully connected one. As a result, FCNs are able to manage different input sizes. Also, FCNs use downsampling (striped convolution) and upsampling (transposed convolution) to make convolution operations less computationally expensive.
A fully convolutional neural network is the perfect fit for image segmentation tasks when the neural network divides the processed image into multiple pixel groupings which are then labeled and classified. Some of the most popular FCNs used for semantic segmentation are DeepLab, FCN-8, and U-Net.
How do FCNs work in practice?
U-Net is a fully convolutional neural network that allows for fast and precise image segmentation. In contrast to other neural networks on our list, U-Net was designed specifically for biomedical image segmentation.
It has a U-shaped architecture with two main paths:
- Encoder — a contracting path that captures context and compresses the image into a smaller representation
- Decoder — an expanding path that reconstructs the image back to its original size while accurately delineating the objects.
The key feature of a U-shaped FCN is the skip connections that link the corresponding layers of the encoder and decoder. This feature allows U-Net networks to retain important details and produce precise segmentations.
At Apriorit, we successfully implemented a system with the U-Net backbone to complement the results of a medical image segmentation solution. This approach allowed us to obtain more diverse image processing results and analyze the received results with two independent systems. Additional analysis is especially useful when a domain specialist feels unsure about a particular image segmentation result.
Generative networks
Generative networks are double networks that include two nets — a generator and a discriminator — that are pitted against each other. The generator is responsible for generating new data, and the discriminator is supposed to evaluate that data for authenticity.
In contrast to other neural networks, generative neural networks can create new synthetic images from other images or noise. Other common tasks for this type of AI model include image inpainting (reconstructing missing regions in an original image) and image super-resolution (enhancing the resolution of low-quality images).
Common examples of generative models include generative adversarial networks (GANs) and variational autoencoders.
How do generative networks work in practice?
Generative adversarial networks are supposed to address one of the biggest challenges neural networks face today: adversarial images.
Adversarial images can cause massive failures in neural networks, as algorithms struggle to properly classify such noise-filled images. For instance, what clearly looks like a panda or a cake to the human eye won’t be recognized as such by the neural network.
Thus, if there’s a layer of visual noise called perturbation added to the original image, a non-GAN model will likely give an inaccurate output. In GANs, the discriminator component is specifically trained to distinguish real samples from fake ones.
Common examples of GANs include pix2pix, EdgeConnect, and ESRGAN. At Apriorit, we often use GANs for projects requiring text-to-image synthesis and image-to-image translation.
Read also
Enhancing the Security and Performance of a Virtual Application Delivery Platform
Make more informed technical and product decisions by understanding the full workflow of building imaging AI. See how to improve accuracy, address bias, and prepare your system for real clinical use.

Transformer networks
Transformer neural networks are deep learning models that transform existing data into new instances. They can be used for computer vision and natural language processing tasks.
Transformers used for computer vision tasks are also called vision transformers (ViTs). They can perform image recognition and image restoration and create synthetic images from other images, text inputs, and voice inputs.
How do transformer networks work in practice?
DALL-E 3 is a transformer network that leverages a GAN architecture. Built on the GPT-3 large language model, this neural network creates high-resolution synthetic images from text prompts.
To improve the quality of end results, the creators of DALL-E 3 suggest using ChatGPT to create and improve highly detailed prompts from a simple idea.
In contrast to other types of networks we discussed, DALL-E 3 is a ready-to-use solution that can be integrated via an API.
Diffusion networks
Diffusion networks, also known as score-based generative models, are generative neural networks that can create data similar to the data they were trained on.
Diffusion models are trained to detect patterns and create images out of the noise. During training, they process data with added noise and then use de-noising techniques to restore the original data. As a result, in contrast to other types of neural networks, diffusion networks don’t require adversarial training.
How do diffusion networks work in practice?
Stable Diffusion is a latent diffusion model for text-to-image generation, although this model can also be used for inpainting, outpainting, and image-to-image transformations. This model has three main parts: a U-Net, a variational autoencoder (VAE), and an optional text encoder.
The latest version of the model at the time of writing is Stable Diffusion 3. Just like DALL-E 3, Stable Diffusion can be integrated into your product or service using an API.
Another popular example of a diffusion model is Midjourney, an AI-powered text-to-image generator. In contrast to Stable Diffusion or DALL-E, Midjourney doesn’t have an API and can be accessed through a dedicated Discord bot or web interface.
Which type of neural network architecture and deployment option to choose depends on the specifics of a particular project, from the resources available to the target image processing operations. To make the right choice, seek advice from professionals.
Now, let’s discuss specific image processing use cases where AI models can be of help.
Related project
Building AI Text Processing Modules for a Content Management Platform
Explore how you can enhance your platform with advanced AI-powered text processing features. We share how our implementation of three AI modules for translation, generation, and formatting improved content management efficiency and user experience.

Along with promising capabilities, AI systems bring a number of limitations and challenges that your development team should be ready to deal with. In the next section, we overview some of the most common.
Challenges of processing images with AI
Working with rapidly developing technologies is always a challenge, as rules and regulations are written on the go, and many uncertainties remain. When it comes to enhancing software or services with AI capabilities, the most critical challenges are already known, so your development team can prepare for them in advance.
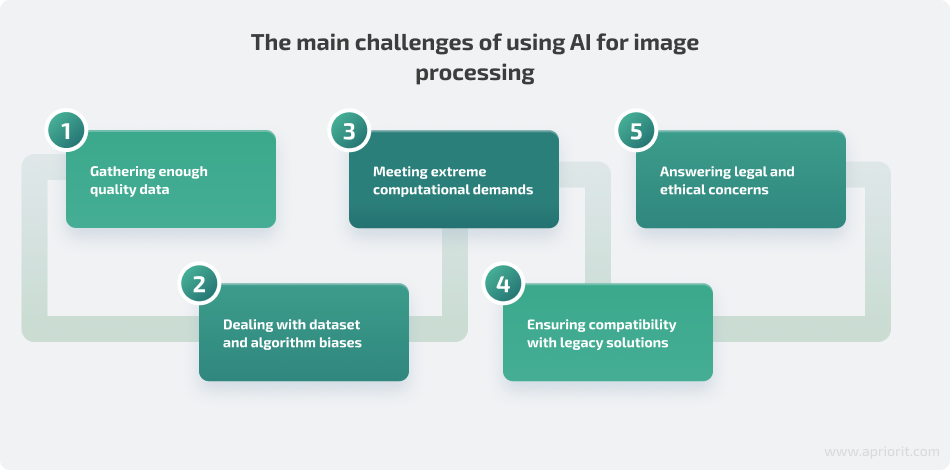
1. Having enough quality data. Quality data is the key to creating an accurate and high-performing AI system. For image processing tasks, it’s important to have enough high-resolution, properly labeled data that an AI model can learn from effectively.
Open datasets, such as the ones we mentioned above, can be suitable for common use cases. But if you work on specific products like medical diagnosis or autonomous vehicle systems, you may need to dedicate more resources to crafting a custom dataset for your AI model.
When there are not enough images to complete a dataset, Apriorit’s AI developers turn to alternative approaches, such as data augmentation techniques. Data augmentation allows us to generate relevant and quality data based on existing images.
2. Dealing with dataset and algorithm biases. Both datasets and algorithms can inherit personal and cultural biases of their creators, potentially making AI model predictions prejudiced and unfair.
With AI image processing, this can affect the entire spectrum of common applications, from image search to image generation, giving preferences to or showing signs of discrimination towards different groups of people based on their gender, race, age, or any other factor.
To increase the fairness of the AI systems we create, Apriorit developers dedicate a lot of time to balancing the datasets we use to train our models and cross-testing our algorithms to detect and fix potential biases.
3. Covering extreme computational demands. While some AI models that work on simple tasks seem to be energy-efficient, complex neural networks used for tasks like image generation and video editing can require a lot of computational power, especially when performing real-time image processing.
To address this sort of challenge, Apriorit’s AI professionals pay special attention to finding the perfect balance between productivity and resource consumption for every AI solution we create. Sometimes, we recommend using distributed computing frameworks like TensorFlow or pruning unnecessary parameters to make the model more energy efficient.
4. Ensuring compatibility with legacy solutions. Integrating AI-powered image processing capabilities into an existing product or service can be quite challenging. Developers need to address things like scalability, data security, and data integration. Some cases may require standardizing data formats and storage methods while others will demand introducing significant scalability enhancements first.
At Apriorit, we can help you understand what improvements need to be implemented before enhancing your existing solution with AI image processing.
5. Answering legal and ethical concerns. Each year, more and more countries turn their attention to regulating the operation of AI-powered systems. These requirements need to be accounted for when you only start designing your future product. However, even if your region or industry doesn’t have specific requirements for AI solutions just yet, if your solution works with personal data, you may still need to make it compliant with data protection regulations and laws like the GDPR, the California Consumer Privacy Act, and HIPAA.
In addition to expert professionals in AI development, Apriorit can enhance your project with top-level business analysis and quality assurance specialists who will account for regulatory requirements in your solution’s design and test the ready product for compliance.
Conclusion
Enhanced with AI, your software solutions can tackle complex computer vision tasks with high speed and accuracy. Whether you want your product to detect objects in images, recognize people’s faces, restore lost and damaged data, or create high-resolution graphics, AI is the right choice.
To gain a competitive edge and unlock the full potential of this technology, it’s crucial to have the right team on board. Apriorit specialists from the artificial intelligence team always keep track of the latest improvements in AI-powered image processing and generative AI development. We are ready to help you build AI and deep learning solutions based on the latest field research and using leading frameworks such as Keras 3, TensorFlow, and PyTorch. Our experts know which technologies to apply for your project to succeed and will gladly help you deliver the best results possible.
Ready to take your business to the next level with AI innovations?
Partner with us to create bespoke AI solutions that give you a competitive edge on the market and cater to your specific needs and objectives.
Have a question?
Ask our expert!
R&D Delivery Manager


