 Skip to main content
Skip to main content

Our developers have a keen interest in using image recognition technologies for various purposes. Convolutional neural networks (CNNs) and machine learning solutions like ImageNet, Facebook facial recognition, and image captioning have already achieved a lot of progress. The main goal of these technologies is to imitate human brain activity to recognize objects in images. However, there’s still room for improvement, as many errors still occur.
For instance, during work on one of our projects concerning practical implementations of convolutional neural networks, we encountered a challenge with increasing Mask R-CNN performance. In this article, we share how we managed to improve Mask R-CNN performance six to ten times by applying TensorRT.
This article may be useful for software developers and data scientists, particularly those who are solving image processing tasks using NVIDIA CUDA, cuDNN, and other machine learning frameworks.
Contents:
Applying CNNs to image processing
Over the past few years, deep learning has continued to expand and convolutional neural networks have been released, creating a revolution in image recognition.
The CNN is a class of artificial neural network that can be a powerful tool for solving various real-life tasks (low traffic detection, human detection, or stationary object detection). In addition to image recognition, CNNs are constantly used for video recognition, recommendation systems, natural language processing, and other applications that involve data with a spatial structure.
A CNN is an artificial neural network with a special architecture that uses relatively little pre-processing compared to other image classification algorithms. This means that the network learns the filters that in traditional algorithms were engineered by hand. A CNN is unidirectional and fundamentally multi-layered. It provides partial resistance to scale changes, offsets, turns, angle changes, and other distortions. Separation from human effort and independence in prior knowledge in future design are the central advantages of this type of network.
Need help with image processing?
Enhance your solutions with professionally developed image recognition features from Apriorit’s expert AI developers!
Types of convolutional neural networks
Region-based convolutional neural networks (R-CNNs) and fully convolutional networks (FCNs) are the most recent types of convolutional neural networks. Both have been influential in semantic segmentation and object detection, helping to solve image processing problems related to detecting sports fields, detecting buildings, and generating vector masks from raster data.
Fast R-CNN, that was developed in 2015, is a faster version of the R-CNN network. Based on the previous version, it employs several innovations to improve training and testing speed while also increasing detection accuracy and efficiently classify object proposals using deep convolutional neural networks. In its operations, Fast R-CNN is exposed to many signs initially found on the image. Further, these signs are projected onto the regions they don’t need to be recalculated.
Faster R-CNN (a more advanced version of Fast R-CNN) uses a special neural network (a region proposal network) to determine the most interesting regions.
Faster R-CNN uses two networks: a region proposal network for generating region proposals and a network for detecting objects. The main difference between Faster R-CNN and Fast R-CNN is that Faster R-CNN uses selective search to generate region proposals. The time cost of generating region proposals is much smaller in a region proposal network than with selective search, when the region proposal network shares the most computation with the object detection network. In short, a region proposal network ranks region boxes (called anchors) and proposes the ones most likely to contain objects.
Mask R-CNN is a neural network based on a Faster R-CNN network. The Mask R-CNN model provides the ability to separate overlapping detection boxes of Faster R-CNN by generating masks.
Mask R-CNN is a two-stage framework.
The first stage is applied to each region of interest in order to get a binary object mask (this is a segmentation process). At the first stage, a Mask R-CNN scans the image and generates proposals (areas that are likely to contain objects).
The second stage operates in parallel with the rest of the neural network responsible for the classification and generation of bounding boxes and masks. A binary mask is calculated for each class, and the final selection is based on the results of the classification.
This type of network has shown good results in detection and segmentation as well as in detecting the posture of people.

Figure 1. Image segmentation with Mask R-CNN
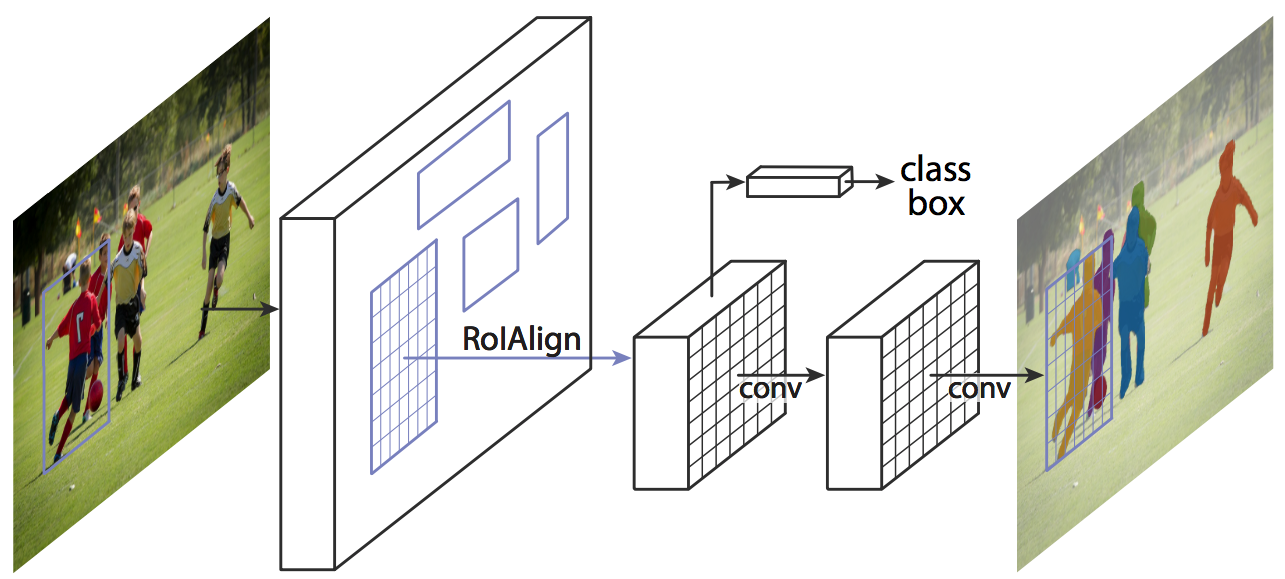
Figure 2. Mask R-CNN architecture
The main benefit of Mask R-CNN is that it provides the best performance among similar solutions in multiple benchmarks and can easily be adjusted for more complex tasks such as processing satellite imagery.
Insufficient performance is one of the main issues related to satellite imagery processing.
After its implementation, Fast/Faster R-CNN runs at five frames per second. If we use Mask R-CNN, the mask layer even adds a bit of overhead. This performance is still suitable enough for real-time tasks (detecting low traffic, humans, stationary objects, etc.). However, its performance may not be enough for certain cases of real-time processing or heavy image processing tasks like those related to satellite imagery.
Satellite imagery is high-resolution and requires fast data collection. For instance, the average revisit time to any desired imaging location of the Worldview-3 satellite is less than one day. Moreover, WorldView-3 is able to collect data on up to 680,000 square kilometers per day. The satellite sends a blistering 1.2 gigabytes of data back to earth every second. In this case, high-performance solutions are critical.
Additionally, this five-frame-per-second performance is true only for low-resolution cameras that gather only light in the visible RGB spectrum (which represent only a small part of satellite imagery). However, satellite images are made by high-resolution devices.
Because of these two challenges, processing a single satellite image that comes from a modern satellite may take minutes or even hours. This isn’t suitable for certain cases of real-time satellite imagery processing, such as detecting change (airport traffic, war tactics, city development, stormwater runoff, fire development), saving energy, and performing detailed environmental analysis.
By using modern software-as-a-service and distributed computing frameworks, we developed an approach that allows us to boost the performance of state-of-the-art object detection solutions.
Related project
Building an AI-based Healthcare Solution
Discover how Apriorit’s AI experts developed a robust solution that could track, detect and measure ovarian follicles across ultrasound video frames, helping our client improve accuracy, simplify doctor’s routine and provide high-quality services to patients.

Improving Mask R-CNN performance with TensorRT
Using the capabilities of general-purpose graphics processing units, it’s possible to more than double the performance of Mask R-CNN solutions using just one additional graphics card. However, this increase in performance is still not significant for modern quantities of data and speed of data collection.
In order to further improve neural network performance, many software solutions have been developed that optimize GPU utilization. For example, you can improve Mask R-CNN with TensorRT, OpenCV, and TensorFlow. These solutions implement software capabilities to use GPU hardware and provide algorithms for distributed computing. We decided to use Tensor RT4 for Mask R-CNN as it provides a feature for automated optimization of neural network solutions.
The NVIDIA TensorRT system is designed to solve deep learning tasks and includes tools for optimizing and executing trained neural networks on NVIDIA graphics processors. With TensorRT, you can optimize neural network models, calibrate for lower precision with high accuracy, and deploy models to hyperscale data centers or embedded or automotive product platforms. TensorRT-based applications on GPUs run up to 100x faster than on a CPU during inference for models trained in all major frameworks.
Implementing Mask R-CNN adds non-significant performance overhead in comparison to Faster R-CNN. Therefore, it extends Faster R-CNN and makes it possible to achieve 20-frame-per-second performance per GPU when successfully porting Mask R-CNN to the TensorRT runtime. This performance is at least four times better per GPU than the original frame rate of Faster R-CNN.
Building a custom Mask R-CNN model with TensorRT is a relatively fresh solution that provides limited capabilities for optimizing artificial neural networks. The main problem is converting certain layers of Mask R-CNN using TensorFlow. We describe an approach to overcome this problem.
Read also
Navigating AI Image Processing: Use Cases and Tools
Uncover the power of artificial intelligence to enhance your software with top-notch image processing features. Read the full article to discover the essentials of AI image processing, its core stages, top use cases, and helpful tools.

Mask R-CNN and TensorFlow combination
TensorFlow is a machine learning library created and maintained by Google. It’s essentially a tool that allows you to implement or simplify a machine learning implementation for any system or task. The main entity of the TensorFlow framework is Tensor. Its architecture isn’t developed to handle all operations on data, but rather to handle the results and distributed computing capabilities. Considering this, it’s possible to handle certain layer operations with Mask R-CNN. The main requirement is that the result should be wrapped in Tensor. We developed a simple module as a proof of concept.
As an example, the identity layer, used for classification with Mask R-CNN, is one of the non-supported layers when porting a TensorFlow-based neural network to the TensorRT runtime. This layer is responsible for moving data between GPU modules, among other tasks. In order to do this, the same data should be transferred from one Tensor to another. The identity layer of Mask R-CNN works with two-dimensional data, and it’s possible to transfer data unchanged to utilize capabilities of matrix algebra. In this particular case, multiplying the identity matrix works (see Figure 3).

Figure 3. Replacement of TensorFlow identity
Conclusion
Testing of the full implementation showed from six to ten times better performance than the original implementation of Mask R-CNN on low-resolution image samples. We expect identical performance on the tile input of high-resolution imagery.
Our team is constantly working on solutions based on artificial intelligence and machine learning. Image processing and computer vision are among the most challenging and breathtaking tasks we face.
Enhance your next project with AI!
Delegate engineering challenges to Apriorit experts and receive efficient software that meets your technical requirements and business needs.
Have a question?
Ask our expert!
R&D Delivery Manager


