 Skip to main content
Skip to main content

Emotions are the key to understanding human interactions, especially those conveyed with facial expressions. Communication Theory by C. David Mortensen shows that we understand only one-third of other people’s feelings from their words and tone of voice; and the other two-thirds comes from people’s faces. Teaching artificial intelligence (AI) to understand our emotions can take human–machine interactions to the next level.
Emotion detection technology has grown from a research project to a $20 billion industry. It’s applied to a lot of activities:
- Marketing research
- Monitoring driver impairment
- Testing the user experience for video games
- Helping medical professionals assess the wellbeing of patients
- And more
It’s possible to apply emotion recognition to pictures, video, audio, and written content. In this article, we concentrate on recognizing emotions in video, as it captures the human face in motion and provides more information on our feelings. We talk about the operating principles of emotion recognition, technologies it can be implemented with, and the key issues with recognizing emotions in video.
In this article, we discuss video- and image-based emotion recognition challenges and explore ways to overcome them. This article will be useful for developers and other specialists who are working on emotional recognition solutions or are interested in emotion recognition technology.
Contents:
How does emotion recognition work?
Emotion recognition (ER) combines knowledge of artificial intelligence (AI) and psychology. Let’s find out how these fields can be united.
On the AI side, emotion recognition in video relies on object and motion detection. Emotion recognition is carried out using one of two AI approaches: machine learning (ML) or deep learning (DL). We’ll take a look at both of these in the next part of the article.
The facial emotion recognition process is divided into three key stages:
- Detection of faces and facial parts — At this stage, an ER solution treats the human face as an object. It detects facial features (brows, eyes, mouth, etc.), notices their position, and observes their movements for some time (this period is different for each solution).
- Feature extraction — The ER solution extracts the detected features for further analysis.
Expression classification — This final stage is devoted to recognizing emotions. ER software analyzes a facial expression based on extracted features. These features are compared to labeled data (for ML-based solutions) or information from the previous analysis (for DL-based solutions). An emotion is recognized when a set of features matches the description of the emotion.
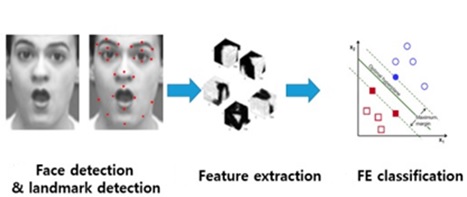
And this is where psychology joins the game. Usually, an ER solution detects seven basic emotions:
- Happiness
- Surprise
- Anger
- Sadness
- Fear
- Disgust
- Contempt
Each emotion is defined by a set of possible positions and movements of facial components. For example, a frown, wrinkled forehead, and upside-down smile is defined as a sign of anger. More advanced emotion detectors recognize complex feelings by mixing these basic classifications. But the results of such analysis still need to be confirmed by humans.
Emotion classification and emotion recognition itself are based on psychological studies of emotions. Most of the datasets and classifiers rely heavily on the work of Paul Ekman, an American scientist who specializes in clinical and emotional psychology. He classified more than 10,000 facial expressions and connected 3,000 of them with emotions. He also discovered that not all facial expressions are necessarily tied to an emotion. Some may indicate physical discomfort, past injuries, muscular twitches, etc. For example, if a short-sighted person squints to see something, that doesn’t indicate an emotion.
Based on this research, Paul Ekman and Wallace V. Friesen created a Facial Action Coding System (FACS). In 1978, it was used as training material for security officers who needed to be able to detect aggression and violence. Later, it was adopted for training emotion recognition software.

Emotion recognition in video comes with technical and psychological challenges. Let’s see what issues you may face when developing such a solution.
Need to detect objects and events in a video?
Entrust this task to Apriorit AI development experts with real-life experience in similar projects.
Challenges of recognizing emotion in images and video
Defining a facial expression as representative of a certain emotion can be difficult even for humans. Studies show that different people recognize different emotions in the same facial expression. And it’s even harder for AI. There’re so many challenges in face recognition, that there’s even an ongoing debate as to whether existing emotion recognition solutions are accurate at all.
A lot of factors make emotion recognition tricky. We can divide these factors into technical and psychological.
Technical challenges
Facial expression recognition shares a lot of challenges with detecting moving objects in video: identifying an object, continuous detection, incomplete or unpredictable actions, etc. Let’s take a look at the most widespread technical challenges of implementing an ER solution and possible ways of overcoming them.
Data augmentation
As with any machine learning and deep learning algorithms, ER solutions require a lot of training data. This data must include videos at various frame rates, from various angles, with various backgrounds, with people of different genders, nationalities, and races, etc.
However, most public datasets aren’t sufficient. They aren’t diverse enough in terms of race and gender and contain limited sets of emotional expressions.
There are three ways to overcome this issue:
- Create your own dataset. This is the most expensive and time-consuming way, but you’ll end up with a dataset perfectly suited for your task.
- Combine several datasets. You can cross-check the performance of your solution on several other datasets.
- Modify the data as you go. Some researchers suggest editing videos that you’ve already used: crop them, change the lighting, slow them down, speed them up, add noise, etc.
Face occlusion and lighting issues
Occlusion due to changes in pose is a common issue for motion detection in video, especially when working with unprepared data. A popular method for overcoming it is by using a frontalization technique that detects facial features in video, creates relevant landmarks, and extrapolates them to a 3D model of a human face.

Changing lighting and contrast is also very common in an unconstrained environment. Usually, developers implement illumination normalization algorithms to increase the recognition rate.
There are also some unconventional approaches. For example, some researchers suggest adding an infrared or near-infrared layer to a data stream. This layer isn’t sensitive to illumination changes and adds records of skin temperature changes that may indicate emotions.
Identifying facial features
An emotion recognition solution scans faces for eyebrows, eyes, noses, mouths, chins, and other facial features. Sometimes, it’s complicated to identify human emotions through pictures due to:
- The distance between features. The software “remembers” the average distance between landmarks and looks for them only within this range. For example, it might have trouble detecting widely spaced eyes.
- Feature size. ER solutions struggle with detecting uncommon features, like unusually thin or pale lips, narrow eyes, etc.
- Skin color. In some cases, a solution may misclassify or misinterpret a feature due to a person’s skin color. We talk about this more in the section on recognizing racial differences.
In order to improve the accuracy of feature identification, some researchers implement a part-based model that divides facial landmarks into several parts according to the physical structure of the face. This model then feeds these parts into the network separately, with relevant labels.
Recognizing incomplete emotions
Most algorithms focus on recognizing the peak high-intensity expression and ignore lower-intensity expressions. This leads to inaccurate recognition of emotions when analyzing self-contained people or people from cultures with traditions of emotional suppression (we’ll get back to that later).
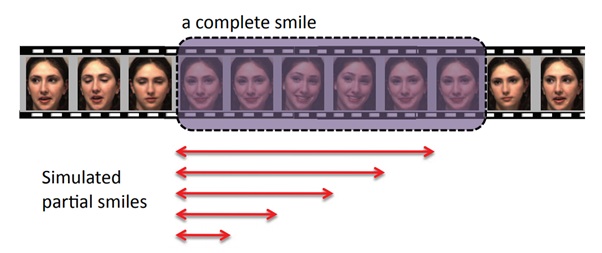
It’s possible to train an algorithm to detect early indicators of emotions by adding extra labels to datasets. To do so, in addition to emotion markers and face feature landmarks, you need to add expression intensity tags to the labels.
Another option for solving this issue is implementing a peak-piloted deep network. This type of network compares peak and non-peak expressions of the same emotion and minimizes the changes between frames.
Related project
Navigating AI Image Processing: Use Cases and Tools
Our article walks you through the key steps of AI-powered image processing, its practical applications, and challenges, providing insights to help your development team excel. Learn how to harness AI potential for complex computer vision tasks.

Capturing the context of emotion
Surroundings and body posture can provide the same amount of information on emotions as a face. But capturing context is a resource-consuming task, as it requires analysis of the whole image instead of just a face. Also, expressions of emotion with gestures is even less studied than facial expressions.
Context-aware neural networks (e.g. CACA-RNN and CAER-Net) divide a video stream into two layers: a face (or several faces) and surroundings (body posture, gestures, items in the frame, etc.). The network is divided as well – into a face emotion analyzer and context analyzer. The final result takes into account both network readings.
Context-aware emotion recognition is divided into two streams
Racial differences
We may have a real problem with detecting emotions on pictures of others, especially if they’re a different race and/or share different cultural traditions. This is a big challenge even for the most profound AI solutions. For example, in 2015, Google Photo algorithms didn’t recognize people with dark skin.
The problem here lies in the diversity of data and the composition of research development teams. Most public datasets contain a lot of data on white men, but not on women and people of color. Also, labeling teams often consist of white males, and these teams tend to test solutions on themselves.
One possible solution to this problem would be a more profound analysis of datasets before training. Another would be creating more diverse teams.
Psychological challenges
Psychologists have been studying the connection between facial expressions and emotions since the 1950s. Yet there are still a lot of blindspots. Since these studies are the basis for emotion recognition software, it’s important to be aware of their shortcomings.
Cultural differences in emotional expression
Although people all around the world feel the same emotions, we express them differently. In Western cultures, most people express each of the seven basic emotions with a distinct set of facial and body movements. Japanese and Chinese people, however, are usually more restrained, indicating emotions only with distinctive eye activity.
This has to be taken into account when choosing training data. Use a relevant dataset that contains people from the same culture as the subjects whose emotions you want to detect, or test your solution against several datasets.

People from the West and the East convey emotions differently. For Brazilians, a broad smile indicates happiness. Japanese express the same emotion with a subtle smile.
Identifying children’s emotions
Infants and children indicate emotions differently than adults. They understand more than they can verbally express, and they react to everything around them with different facial expressions. Also, children don’t restrain their emotions.
However, scientific studies can’t confirm that these facial expressions indicate emotions, at least not when it comes to infants and preschoolers. Another issue comes with the fact that children’s emotions are interpreted by adults. For example, early studies of infant emotions claimed that babies as young as 7 months were capable of expressing anger. In fact, they were simply scowling, and there’s no reliable way to connect this expression with emotion at such a young age.

A child and an adult express the same emotion differently, yet software by Microsoft recognizes both expressions as “surprise.” Image credit: Microsoft
Incorrect emotion indicators
Indicators of the seven key emotions are well studied, but not all studies agree on what these indicators mean. For example, a scowl is considered an expression of anger by a lot of psychological studies. But other studies state that only 30% of people actually scowl when they’re angry. That means 70% of people express anger differently, and may use a scowl to express other emotions.
This problem of emotion recognition with AI lies in the psychology field rather in programming. Using a limited number of indicators can lead to false-positive results and an incorrectly trained AI. So it’s best to keep an eye on new studies of emotional expressions and constantly train your solution against new data.
Let’s find out how different AI approaches help to detect and interpret facial expressions to recognize emotions in video.
Related project
Leveraging NLP in Medicine with a Custom Model for Analyzing Scientific Reports
Learn how our NLP model enhanced client’s report processing and analysis, providing valuable insights and streamlining workflows for a leading medical research organization. With our solution, the client achieved over 92.8% accuracy and was able to conduct faster, more insightful medical research.

Technologies for recognizing emotions in video and images
When it comes to emotion recognition in video and images, there’s no universal solution. Developers choose the most suitable technology for their tasks or create a new approach. We divide the most popular solutions into two categories: those that are based on machine learning algorithms and those that are based on deep learning networks. After that, we take a look at emotion recognition software from Microsoft, Amazon, and Affectiva.
Both machine learning and deep learning are subsets of AI. The key difference between them lies in the way they analyze data.
Machine learning algorithms parse data, learn its characteristics, and then recognize the same data in the real world. They require human intervention and a lot of structured training data to achieve an accurate result.
Deep learning models, or artificial neural networks, try to emulate the way a human brain works. They consist of layers of ML algorithms, each providing a different interpretation of data. The more layers, the deeper the network. Unlike ML, DL can study data on its own.
Now let’s take a look at several machine learning and deep learning approaches for human emotion recognition in videos.
Machine learning algorithms
Support-vector machines (SVM) algorithm is a linear classification technique widely applied for image processing. Experiments by University of Cambridge on applying SVM algorithms for emotion recognition have shown 88% accuracy. This is a promising result; however, the classification time is high compared to other ER methods. Also, recognition accuracy will be lower when an SVM algorithm is applied to real-world videos instead of controlled datasets.
Bayesian сlassifiers are algorithms based on Bayes’ theorem. Compared to other machine learning approaches, Bayesian сlassifiers need less data for training and are able to learn from both labeled and unlabeled data. Using maximum likelihood estimation, they achieve higher accuracy outside laboratory tests. A group of researchers tested three classifiers for recognizing emotion in videos with unlabeled data and got the following results:
- A naїve Bayes classifier can achieve around 71% accuracy when training with unlabeled data.
- A tree-augmented naїve Bayes classifier achieves around 72% accuracy.
- Stochastic structure search achieves almost 75% accuracy.
Random Forest (RF) is a machine learning algorithm applied for classification, regression, and clusterization. It’s based on a decision tree predictive model that’s tailored for processing large amounts of data. RF handles both numerical and categorical data, allowing this algorithm to recognize emotions and estimate their intensity. RF accuracy varies between 71% and 96% depending on the complexity of detected features.
The k-nearest neighbors algorithm (k-NN) is a type of lazy learning method used for classification and regression tasks. k-NN is easier to implement than other ML algorithms, as it doesn’t require the creation of a statistical model. However, the more data is processed by the algorithm, the slower it gets. The accuracy of this algorithm varies between 68% and 92% depending on the complexity of detected features.
Deep learning algorithms
Deep convolutional neural networks (CNNs) are one of the most popular deep learning approaches to image and video processing. Various types of CNNs are applied for emotion recognition purposes:
- Fast R-CNN is implemented for image processing solutions that need to detect emotions in real time.
- Faster R-CNN is used to identify facial expressions by generating high-quality region proposals. Both Fast R-CNN and Faster R-CNN use SVM algorithms for classification.
- 3D CNN captures motion information encoded in multiple adjacent frames for action recognition via 3D convolutions.
- C3D exploits 3D convolutions on large-scale supervised training datasets to learn spatio-temporal features of different emotions.
The accuracy of recognizing emotions with these types of CNNs ranges from 84% to 96%.
Recurrent neural networks (RNNs) are suitable for processing sequences of data. A traditional neural network processes pieces of information independent of each other. An RNN adds loops to its layers. This allows the network to capture the transition between facial expressions over time and detect more complex emotions.
Long short-term memory (LSTM) is a type of RNN focused on classifying, processing, and making predictions based on a series of data. The accuracy of emotion recognition with LSTM reaches 89%.
A deep belief network (DBN) is a generative graphical model. Unlike other neural networks, a DBN consists of interconnected layers of latent variables and learns to extract hierarchical representations from the training data. This network has a better accuracy rate for processing videos with facial occlusion: from 92% to 98%.
Deep autoencoders (DAEs) are unsupervised neural networks based on two symmetrical DBN algorithms. The networks we mentioned previously are trained to recognize emotion. A DAE is optimized to reconstruct its inputs by minimizing the reconstruction error. This method is effective for lower dimensional features and low-resolution videos: its accuracy reaches 95–99%.
Now let’s see what some AI vendors have to offer for solving emotion recognition tasks.
Read also
10 Nuances of Testing AI-Based Systems
Explore the key aspects of AI testing and gain a deeper understanding of how it differs from traditional software testing. Enhance your QA strategy by focusing on critical areas that ensure the stability and performance of your AI systems.

Emotion recognition solutions
As we mentioned, the market for emotion detection software is booming. There are dozens of solutions, ranging from very accurate to nearly useless. We’ll take a look at the three most frequently used.

Microsoft Azure provides a Face API for processing real-time and prerecorded images and videos. Face API has several major applications:
- Face detection — Detects a face in an image or video as well as a person’s approximate age, gender, and emotion
- Face verification — Compares two faces and analyzes if they belong to the same person (useful for security checks)
- Search for similar faces — Analyzes a face, compares it to a database of faces, and detects similar features
- Face grouping — Groups people based on universal traits: age, gender, expression, facial features, etc.
- Identifying people — Compares a face to previously scanned faces and identifies a person if their face is matched with a verified identity
Amazon Rekognition is an AWS emotion recognition API. It analyzes real-time and prerecorded images and videos. This API detects objects and activities, recognizes handwritten text, counts people and objects in the frame, and monitors for unsafe content. It has three applications:
- Face recognition — Detects a face and identifies a person by comparing the analyzed face to a database of previously identified faces
- Celebrity recognition — Compares a detected face to a database of celebrities
- Face analysis — Analyzes key attributes of a face: gender, approximate age, emotions, glasses, hair, facial features
Vision AI is a computer vision platform from Google. It consists of two products:
- AutoML Vision — A tool for automating training of custom ML models
- Vision API — A tool for detecting and classifying objects, recognizing handwritten text, identifying popular places and brands, marking explicit content, etc. Regarding emotion recognition, Vision API detects faces in images and detects emotions. But unlike other solutions, it doesn’t identify people or recognizes age or gender.
Affectiva is a company that specializes in developing human perception AI. It has four products for emotion recognition:
- Emotion SDK — Analyzes facial expressions in real-time videos from a device’s camera to detect seven basic emotions and recognize age, gender, and ethnicity
- Automotive AI — Analyzes facial and vocal expressions of drivers and passengers in order to ensure a safe ride
- Affdex — A cloud-based solution that detects customers’ reactions to new products (designed specifically for market research)
- iMotions — Сombines data from visual emotion monitoring with biometric data such as heartbeat, brain activity, and eye movement (designed for scientists and researchers)
Conclusion
Emotion recognition is a popular and promising sphere that has a chance to simplify a lot of things, from marketing studies to health monitoring. It can also be useful for generative AI development and similar types of projects.
Developing facial emotion recognition software requires both deep knowledge of human psychology and deep expertise in AI development. While the first provides us with an understanding of what facial expressions indicate what emotions, AI still has much to learn in order to recognize them correctly.
When choosing a vendor that offers custom emotion detection software development services, make sure to check whether they have relevant experience and are aware of what challenges to expect.
Plan on starting a new AI development project?
Get two steps ahead by leveraging Apriorit’s experience and AI technology knowledge.
Have a question?
Ask our expert!
R&D Delivery Manager


