 Skip to main content
Skip to main content
In 2021 alone, humans created, copied, and consumed around 74 zettabytes (trillions of gigabytes) of data. It may seem like we have all the data we need, but in fact each year it gets harder and harder to find relevant information. Luckily, techniques like data mining can help us bring back order to the hoards of data and use it to improve our cybersecurity.
Analyzing your databases and security logs with data mining techniques can help you improve the detection of malware, system and network intrusions, insider attacks, and many other cybersecurity threats. Some techniques can even accurately predict attacks and detect zero-day threats.
In this article, we examine key data mining techniques and five use cases of data mining in network and endpoint security. This post will be useful for teams that develop cybersecurity software and want to improve its threat detection capabilities.
Contents:
Data mining in cybersecurity: process, pros, and cons
What is data mining? Data mining is the process of analyzing information, discovering new patterns and data, and predicting future trends. It’s often used in scientific research, business development, customer relations, and other spheres.
While the term data mining is usually treated as a synonym for knowledge discovery in databases (KDD), it’s actually just one of the steps in the KDD process. The main goal of KDD is to obtain useful and often previously unknown information from large sets of data. The entire KDD process includes four steps:
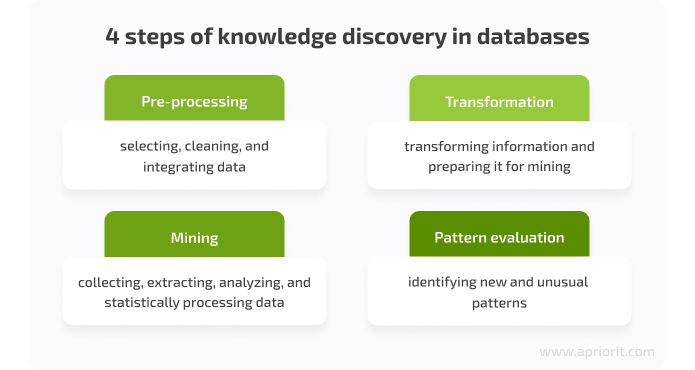
KDD is widely applied in any field that can benefit from the analysis of vast amounts of data: scientific studies, business analysis, marketing research, etc. It’s also used by cybercriminals to find new ways of attacks, and by cybersecurity professionals to detect and stop these new attacks.
Combining data mining and cybersecurity allows for determining features of cyber attacks and improving attack detection processes. To obtain valuable knowledge, data mining uses methods from statistics, machine learning (ML), artificial intelligence (AI), and database systems.
Data mining helps you quickly analyze huge datasets and automatically discover hidden patterns, which is crucial when it comes to creating an effective anti-malware solution that’s able to detect previously unknown threats. However, the final result of using data mining methods always depends on the quality of data you use.
Relying on data mining to improve your protection comes with its own advantages and disadvantages. Let’s take a look at them:

These are the general pros and cons of mining data for cybersecurity purposes. Besides them, each data mining technique has its own advantages, limitations, and specific use cases. Let’s take a look at six key data mining approaches to cybersecurity.
Want to improve the security of your software?
Leverage Apriorit’s 20+ years of experience in cybersecurity development to safeguard your solution from attacks and data leaks.
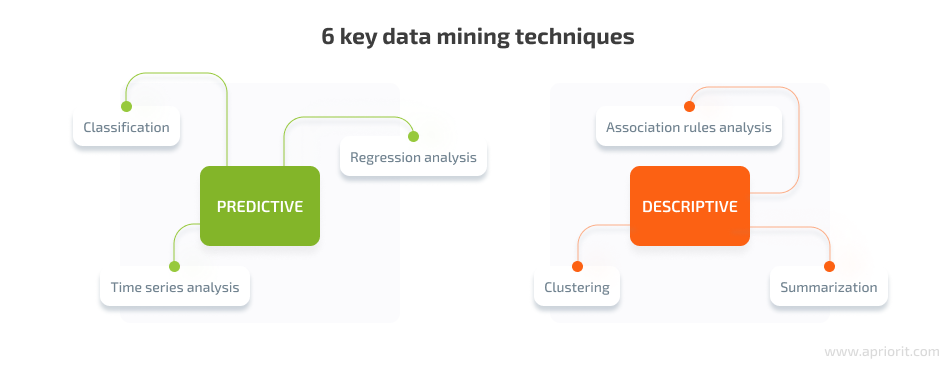
6 key data mining techniques
You can mine databases using predictive or descriptive techniques. Prescriptive techniques make predictions based on past events, while descriptive techniques are focused on the analysis and structuring of existing databases.
Let’s take a look at six key data mining techniques for cybersecurity:
Classification
This technique creates a model of your database by breaking a large dataset into predefined classes, concepts, and groups of variables. You can also use it to analyze variables added to the database after building the model and assign them with a corresponding class. To achieve accurate real-time classification, you need to pay a lot of attention to supervised training of the algorithm as well as to testing how it works. In cybersecurity, classification is often used to detect spam and phishing emails.
Regression analysis
These algorithms predict the changing value of one variable based on the known average values of other variables in a dataset. Using this technique, you can build a relationship model between dependent and independent variables in the database. Analyzing changes in variables and comparing these changes to the dependent variables can help you identify reasons for change and the influence of one variable on another. Regression analysis is widely used for forecasting trends and events, including possible cyber attacks.
Time series analysis
These algorithms discover and predict time-based patterns by analyzing the time of any data entry changes in the database. This technique is particularly useful for getting insights into all sorts of periodic activities by mining multi-year databases. You can rely on time series analysis for predicting security vulnerabilities and attacks that occur during a certain event, season, or even time of the day.
Association rules analysis
This is one of the most widespread groups of data mining algorithms. Association rules analysis can help you with finding possible relations between variables that frequently appear together in databases and discover hidden patterns. You can apply this technique to analyze and predict user behavior, examine network traffic, and define patterns of cyberattacks. Security officers often use association rules analysis to study attackers’ behavior and ways of thinking.
Clustering
Clustering helps to identify data items that have common characteristics and understand similarities and differences in variables. It’s similar to classification, but clustering cannot sort variables in real time. This technique can only help you structure and analyze an existing database. In contrast to classification, clustering allows for making changes in the model and creating subclusters without having to rework all the algorithms.
Summarization
This data mining technique is focused on compiling brief descriptions of datasets, classes, and clusters. Summarization can help you better understand the contents of your datasets and the results of the data mining process by grasping the essence of data and eliminating the need to dig through it manually. In cybersecurity solutions, summarization is mostly used to generate reports and visualize logs.
Keep in mind that each of these data mining techniques can be augmented with ML and AI algorithms. These cutting-edge technologies can help you discover more hidden patterns and improve the accuracy of predictions. However, adding ML and AI to a cybersecurity solution will surely add to the complexity of its development and maintenance.
Next, we’ll take a closer look at particular use cases showing how you can use data mining for cybersecurity solutions.
Related project
Developing a Custom Secrets Management Desktop Application for Secure Password Sharing and Storage
Explore how our team designed and implemented a cross-platform secret management software that helped our client protect sensitive information and improve overall company security score by 30%.

Data mining use cases in cybersecurity
You can apply data mining to any database and adjust it to any goal you want to achieve. In cybersecurity, mining algorithms often help to discover unusual data records and events that may indicate a security incident.
Here are the five most common applications of data mining in computer security:
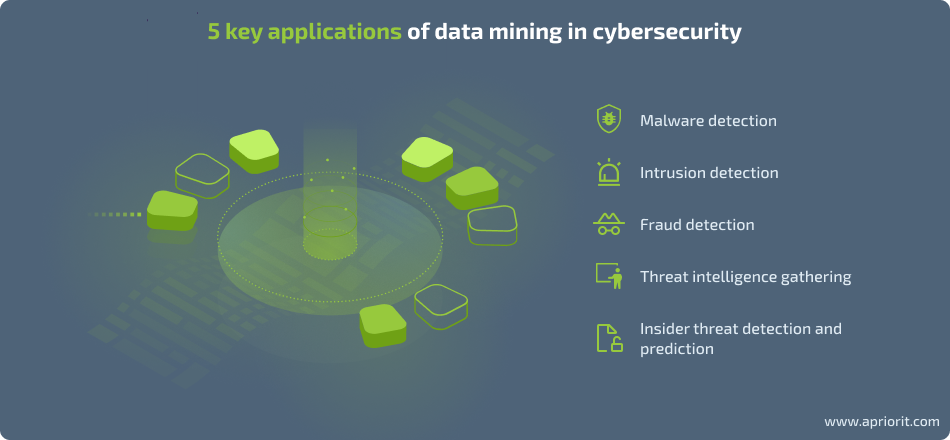
1. Malware detection
When building security software, developers use data mining methods to improve the speed and quality of malware detection as well as to detect zero-day attacks.
There are three strategies for detecting malware:

Anomaly detection involves modeling the normal behavior of a system or network in order to identify deviations from normal activity patterns. Anomaly-based techniques can detect even previously unknown attacks and can be used for defining signatures for misuse detectors.
However, anomaly detection can report even legitimate activity if it deviates from the norm, thus producing false positive alerts.
Misuse detection, also known as signature-based detection, identifies only known attacks based on examples of their signatures. This technique has a lower rate of false positives but can’t detect zero-day attacks.
The hybrid approach combines anomaly and misuse detection techniques in order to increase the number of detected intrusions while decreasing the number of false positives. Hybrid detection algorithms don’t build any models. Instead, they use information from both malware and legitimate programs to create a classifier, which is a set of rules or a detection model generated by the data mining algorithm. Then the anomaly detection part of the system searches for deviations from the normal profile and the misuse detection part of the system looks for malware signatures in the code.
No matter which strategy you choose, development of a malware detection system consists of two steps:

First, the data mining algorithm extracts malware features from records on API calls, n-grams, binary strings, program behaviors, and other events. You can apply static, dynamic, or hybrid analysis to extract malware features from potentially unsafe files.
During the classification and clustering step, you can use corresponding techniques to divide file samples into groups based on feature analysis. At this point, you’ll need to build a classifier using classification algorithms such as RIPPER, decision tree, artificial neural network, naїve bayes, or support vector machines.
Using ML techniques, each classification algorithm constructs a model that represents both benign and malicious classes. Training a classifier using such file sample collection allows you to detect even newly released malware.
Read also
AI and ML for Fraud Detection: Top Use Cases, Approaches, and Technologies
Employ cutting-edge technology in your data protection strategy. Discover how artificial intelligence can help you quickly analyze massive arrays of data and detect fraudulent activity.

2. Intrusion detection
Attackers can execute malicious intrusions through an organization’s networks, databases, servers, web clients, and operating systems. Using data mining techniques, you can analyze audit results and identify anomalous patterns. Thus, you can detect intrusions, network and system scanning, denial of service, and penetration attacks.
Data mining methods are especially effective to detect these types of intrusions:

To detect host-based attacks, your cybersecurity software needs to analyze features extracted from programs. Detecting network-based attacks requires such a solution to analyze network traffic. And as with malware detection, you can look for either anomalous behavior or cases of misuse.
Intrusion detection systems are usually based on classification, clustering, and association rules techniques. These techniques allow for extracting attack features from a database, systemizing them, and flagging any new records with the same features. Some of the algorithms you can use here are regression and decision trees, bayesian networks, k-nearest neighbors, learning automata, and hierarchical clustering.
You can also add prediction capabilities to the intrusion detection system. Techniques like classification and time series analysis can calculate the possibility of a future intrusion. And using AI algorithms will make it easier to detect hidden or previously unknown suspicious activity.
3. Fraud detection
Detecting fraud is challenging because fraudulent activities are usually well-hidden and cybercriminals constantly invent new fraud patterns.
Data mining techniques that leverage machine learning can pick up many types of fraud, from financial fraud to telecommunications fraud and computer intrusions. Using machine learning for fraud detection is particularly benefitial because it can:
- Scale to take into account changes in the number and complexity of your databases
- Learn to detect and predict new types of fraud
- Accurately calculate the probability of fraudulent activity
You can use both supervised and unsupervised ML algorithms to detect fraud.
With supervised learning, all available records are classified as either fraudulent or non-fraudulent. This classification is then used for training a model to detect possible fraud. The main drawback of this method is its inability to detect new types of attacks.
Unsupervised learning methods learn fraud patterns from untagged records. They create their own classification and feature descriptions for fraudulent activities. Unsupervised learning helps identify privacy and security issues in data without using statistical analysis. It’s also capable of analyzing and detecting new types of fraud.
Related project
Developing a Custom MDM Solution with Enhanced Data Security
Discover a real-life story of how our client managed to improve their cybersecurity posture attracted new clients. Read on to find out the details of Apriorit’s work on client’s solution for Android management with remote device control, suspicious activity monitoring, data protection, and other features.

4. Threat intelligence gathering
Pieces of evidence about cybersecurity threats are usually scattered across an organization’s network. These records can be used to form training datasets, build mining models, and improve prediction accuracy. But the challenge is to find a relevant piece of data in terabytes of records.
Data mining algorithms help to discover such hidden data and convert it into a structured threat intelligence database. You can use clustering, association rules, and summarization techniques to discover these types of intelligence:

Data mining is often used only for the first stages of threat intelligence: discovering and structuring data. After that, a cybersecurity expert has to manually review discovered data and decide how to act on it. However, you can also use data mining techniques to build a machine learning-based framework for gathering and processing data.
5. Insider threat detection and prediction
Insider threats are activities of legitimate users that may cause harm to an organization. Detecting insider threat activities is usually a tricky task because these actions often look similar to ordinary user activities, or they can be purposely masked from threat detection mechanisms.
Since big data algorithms can detect unusual behavior of both machine and human users, they are widely used to detect and predict insider threats. Similar to intrusion detection systems, insider threat detection systems are based on identifying features of legitimate and threatening actions.
There’s a great variety of machine learning-based classification and clustering algorithms, both supervised and unsupervised, that help to detect insider threats. Also, you can train deep neural networks based on data mining principles to examine cybersecurity logs and detect possible insider activity in real time.
Conclusion
Reliable, relevant, and well-structured data is the foundation of almost any cybersecurity solution. And while organizations generate tons of data every day, manually gathering and processing all that data to combat cybersecurity threats is impossible.
Data mining techniques can help you identify the characteristics of any malicious activity and even predict possible attacks. They are particularly efficient at gathering threat intelligence and detecting malware, intrusions, fraud, and insider attacks. The main benefit of enhancing your protection with data mining is the ability to identify both known and zero-day attacks.
Protect your software from hidden and unusual threats!
Apriorit’s experienced teams are ready to help you develop, test, and maintain your software with security in mind.
Have a question?
Ask our expert!
VP of Engineering


