 Skip to main content
Skip to main content

The terms machine learning and deep learning are often used interchangeably. However, their capabilities and therefore their applications are different.
In this article, we draw a fine line between machine learning and deep learning and determine when to apply them. We hope this analysis will make it easier for you to choose the right approach for your artificial intelligence project.
Contents:
Machine learning vs deep learning
Before we can determine which approach better suits your project goals, let’s take a brief look at their basics.
Machine learning: definition and use cases
Machine learning (ML) is a subset of artificial intelligence (AI) that relies on the use of statistical learning algorithms. The key task of machine learning systems is to find patterns in existing data and then try to predict similar patterns in new data. To do so, machine learning systems continuously learn and improve themselves by processing structured data. This ability to learn from experience allows machine learning systems to automatically adapt to changes and make better predictions over time.
Algorithms are the core of any machine learning system. We can outline four main categories of machine learning algorithms:
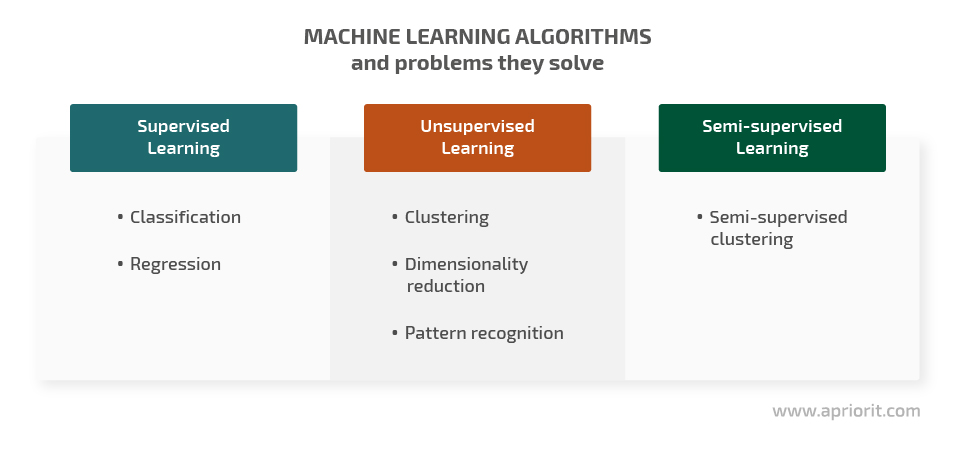
Supervised learning algorithms require properly labeled data to successfully train machine learning models. If trained on poorly labeled data, supervised learning algorithms won’t be able to provide accurate results. Based on known examples of input/output pairs, these algorithms learn to match inputs to outputs in new data. Common applications of supervised learning include relatively simple classification and regression tasks, such as filtering spam emails or predicting the cost of a house based on its location.
Unsupervised learning algorithms are trained on unlabeled data. While having known inputs, these models need to figure out the right outputs on their own. They do it by looking for patterns, differences, and similarities in the processed data. Common applications of unsupervised learning include grouping objects with similar characteristics (clustering) and recommending goods and services to customers.
Semi-supervised algorithms are trained on datasets that include a small volume of labeled data and a large volume of unlabeled data. After being trained on a dataset with labeled data, a semi-supervised model can label the rest of your dataset. These algorithms are widely applied for such tasks as speech analysis and web content classification.
Reinforcement learning is often listed as a machine learning technique, but it usually depends on deep learning models. In this technique, algorithms are treated as agents who get rewarded for performing the right actions and punished for making mistakes. Using this feedback, a model learns how to operate in a specific environment and determines the ideal behavior in a particular context. Common real-life applications of reinforcement learning include game personalization and training of autonomous vehicles.
Ready to take your business to the next level with AI?
Partner with Apriorit and transform your ideas into cutting-edge solutions to stay ahead of the competition!
Deep learning: definition and use cases
As deep learning is a subset of machine learning, these terms are often conflated. However, their degree of technical complexity and capabilities are different.
Whereas machine learning uses basic models relying on separate algorithms, deep learning models use neural networks — multi-layered networks of algorithms that operate similarly to the human brain. But in contrast to the human brain, neural networks are capable of determining unobvious relations between items, especially when analyzing items from different knowledge domains.
In contrast to machine learning models, deep learning models show better performance on large datasets and allow for using already built and trained neural networks for new tasks. To make complex predictions, deep learning systems may use massive volumes of data, also known as big data, processed by a neural network.
While there are many types of neural networks, we’ll take a look at the three most common:
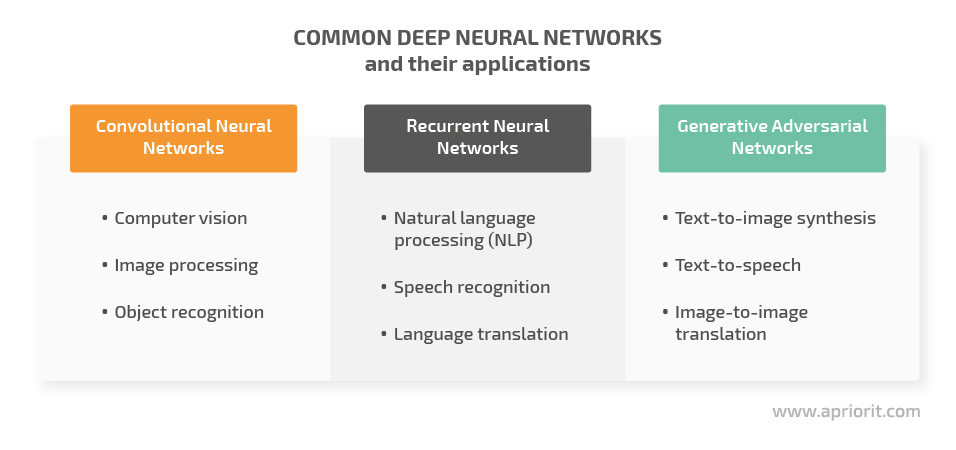
Convolutional neural networks (CNNs) tackle computer vision and image recognition tasks and are mostly used for processing, analyzing, and classifying visual content. A CNN usually consists of three layers: convolutional, pooling, and fully connected. In such a network, each layer is more complex and processes more data than the previous.
Some widely applied CNNs are AlexNet, GoogLeNet, and VGGNet.
Recurrent neural networks (RNNs) usually process time series and sequential data and are widely applied for completing natural language processing (NLP) tasks. The key factor distinguishing RNNs from other neural networks is that they rely on feedback connections, using the output from the previous calculation as an input for the current step. An RNN also has “memory,” meaning the network remembers all of its previous calculations.
Common examples of RNN architectures include long short-term memory and bidirectional recurrent neural networks.
Generative adversarial networks generate content by pitting two neural networks — a generator and a discriminator — against each other. GANs create new, synthetic data instances that only slightly resemble their training data. For example, a GAN can generate images that look like authentic photographs. However, these images won’t belong to any real person (see Figure 1).

There are different variations of GANs: text-to-image synthesis, text-to-speech, image-to-image translation, and more.
Read also
Accomplishing Speaker Recognition Tasks with Machine Learning and Deep Learning — Practical Evaluation of Tools, Techniques, and Models
Explore key approaches to developing AI-driven speech-processing solutions. Our experts offer practical insights into the tools, techniques, and models available for speaker recognition and compare their performance across different datasets.

When to choose deep learning over machine learning
As you can see, machine learning and deep learning aren’t equal. Let’s summarize the key differences between machine learning and deep learning:
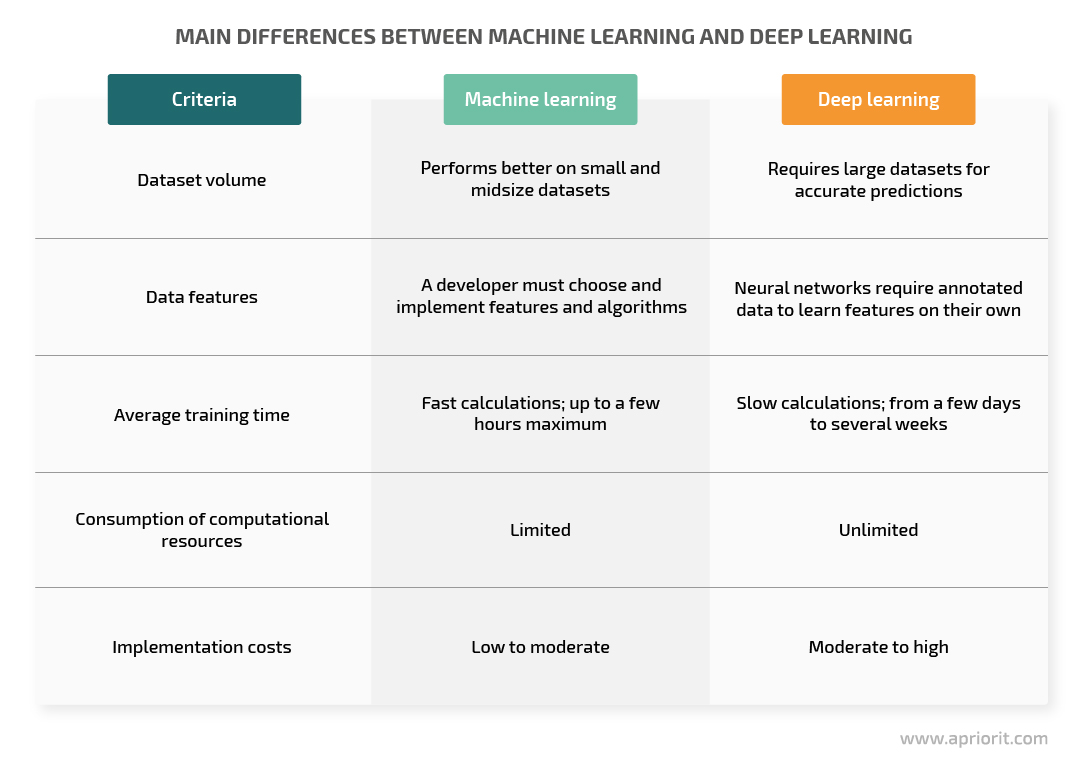
It’s better to use machine learning when you:
- have a small set of quality labeled data to train a machine learning model
- want to automate routine business processes (user identity verification, sales information analysis, medical diagnosis, etc.)
Deep learning performs better that machine learning when you:
- have large volumes of unstructured data
- need to handle complex tasks requiring decision-making: image classification, speech recognition, NLP, and so on
Note that you can choose between these approaches for particular subsystems, thus making use of both in the same software system.
Real-world applications of machine learning and deep learning
To make it easier for you to distinguish tasks solved by machine learning and deep learning, let’s look at some real-life use cases:
Healthcare and medicine
Deep learning is winning the race in the healthcare sector. Deep learning models can be used for testing chemicals and speeding up drug development. Doctors can rely on deep learning models to determine accurate diagnoses in puzzling cases.
Customer recommendations
Striving to improve the customer experience, many companies enhance their services with deep learning capabilities. For instance, Facebook uses both machine learning and deep learning methods to help users discover relevant content and establish new connections. Netflix, Google, and Amazon do the same to improve the experience of their customers. Google and Amazon also provide custom toolsets for user experience personalization.
Automotive
One of the industries showing the biggest potential for applying machine learning and deep learning is automotive. AI-powered solutions can be applied to assisting drivers on the road, predicting potential problems with a vehicle’s mechanical state, automating the process of filling out insurance claims, and, of course, powering self-driving cars.
We can already see AI solutions solving most of these tasks in examples from Tesla, Waymo, and Mercedes-Benz.
Finance
Machine learning solutions are widely applied throughout the financial sector. Banks can leverage machine learning models to automate loan approvals. Deep learning models, in turn, can be used to analyze human behavior and detect and stop fraud attempts.
Investment bankers have long used computerized trading algorithms, but their static models don’t adjust well to changing markets. In the machine learning age, adaptive algorithms reduce risk and increase gains. Also, AI can be of help in fighting money laundering.
Security
Deep learning is also widely applied in cybersecurity products, especially in the field of facial recognition. Deep learning models can successfully process and analyze pixelated and blurred images — something even humans can’t do. Therefore, they seem to be a compelling solution for facial biometrics.
Facebook uses their own face recognition system called DeepFace to identify fraudulent accounts and notify legitimate users when the system recognizes their face in someone else’s profile image.
Read also
Applying Long Short-Term Memory for Video Classification
Learn when and how to use long short-term memory networks for speech recognition and language modeling. This technology can effectively solve video classification challenges by remembering the state of previous frames.
Challenges of implementing machine learning
The promising capabilities offered by machine learning and deep learning come at a price. Below, we list some of the most common challenges to take into consideration when starting a machine learning or deep learning project:

Lack of quality data. Both machine learning and deep learning heavily depend on the use of quality data. Collecting and preprocessing enough data to train and test your machine learning system is a true challenge. Besides, data used for machine learning analysis often changes, so there’s a constant need for relevant data. If you want to work on a machine learning product, data is the first thing you should take into consideration. Thus, you should either invest in gaining new data or obtain access to big data through third-party providers.
This challenge can be addressed in two ways: by leveraging open-source datasets or creating a custom dataset. Apriorit developers always research whether it’s possible to customize ready datasets and pre-trained models to a particular task. When needed, we prepare custom datasets for the solutions we build to make sure our models provide the most accurate results possible.
Data privacy concerns. The lack of transparency in the way machine learning models use data raises a lot of data privacy concerns. Industries like healthcare, finance, and cybersecurity heavily rely on the use of personal information. But when fed to a machine learning system, all this information must be depersonalized and strongly protected.
In order to avoid information discrimination, it’s best to perform feature analysis using processed data containing zero identifying information whenever possible. Additionally, some machine learning developers use containerization technologies for data processing to create the minimum number of libraries without using any personal data. Microsoft also suggests converting trained neural networks to CryptoNets that can deal with encrypted data.
Quality assurance issues. Traditional quality assurance (QA) approaches aren’t applicable to machine learning solutions. QA specialists usually don’t know how to determine an algorithm’s efficiency, so they can only check the system interface. This is why testing the AI system’s performance often becomes a developer’s task.
Obviously, there may be some cases when the system will make mistakes that are uneventful and actually admissible for machine learning algorithms. Specially trained testers or machine learning developers should check whether these mistakes are too frequent. There are mathematical metrics for each type of algorithm that evaluate different indicators of their quality and performance.
Technical complexity. Building a machine learning system is much more difficult than developing a traditional piece of software. Possible challenges vary from finding competent specialists to choosing the right algorithms to making your team work in synergy.
The complex architecture of a machine learning system requires model builders to create a model that is the core of the system and test its predictive accuracy. Meanwhile, system engineers need to concentrate on system design and performance using dynamic programming languages like Python or R. Some system performance requirements can force model builders to reconsider the model itself and modify the algorithms used.
To somewhat simplify this complex process for you, we outline six effective tips for the machine learning development process below.
Read also
Decentralized Finance (DeFi) Solutions: Benefits, Challenges, and Best Practices to Build One
Discover the potential of DeFi to transform financial services, from trading to lending. This article explores key use cases, benefits, and challenges of developing secure and efficient DeFi applications.
Tips for developing your own machine learning solution
Over the last several years, Apriorit has successfully implemented multiple AI projects ranging from recognizing and processing objects in images and video records to classifying cancer types.
Based on these experiences, we can outline several useful tips for developing a machine learning solution:
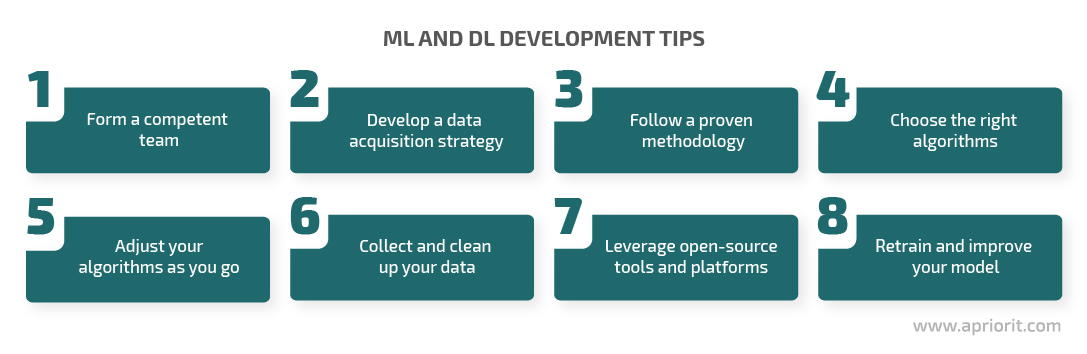
Form a competent team. Any machine learning project requires forming a team with very specific expertise. Even though there are libraries with prebuilt algorithms, it’s almost impossible to imagine a real-world task for which an out-of-the-box algorithm would work without pre-processing or modifications. Therefore, if your project requires building sophisticated mathematical models, you’ll surely need analysts and developers with an advanced math background. Also, consider looking for developers with a background in data science and strong data engineering skills. And don’t forget about the importance of a discovery phase in software development, so search for experienced business analysts for your project.
Follow a proven methodology. To ensure the reliability of your project, it’s best to follow a proven methodology. Two widely used machine learning methodologies are Sample, Explore, Modify, Model, and Assess (SEMMA) and the Cross-Industry Standard Process for Data Mining (CRISP-DM).
SEMMA is an iterative process for data mining that uses modeling techniques. Be cautious when using this methodology, as it pays more attention to procedures and tends to leave business objectives out of focus. CRISP-DM, in turn, mostly focuses on business objectives.
Develop a data acquisition strategy. Data is the heart of any machine learning solution, so you need to think ahead about how to get more relevant data. There are at least three common sources of data:
- Open resources like Kaggle and Google Dataset Search
- Sources you can get access to through partnerships with other organizations (receive or buy from universities, data providers, other companies, etc.)
- Hand-crafted data that you create or gather and process on your own, either manually or with the help of data processing software
You can work with each of these types of data sources, balancing them according to your task at hand.
Collect and clean up your data. Training and testing AI models often requires extremely large volumes of quality data. Therefore, it’s best to start collecting the needed data early on and ensure the consistency and cleanness of that data.
In particular, try to get rid of any data duplications as well as incomplete, invalid, and conflicting data. To do so, you may use different techniques, data management tools, and even machine learning algorithms.
Choose the right algorithms. Consider all machine learning algorithms available, keeping in mind criteria such as scalability, reliability, and efficiency. It’s important to understand that there’s no universal model, so it may be reasonable to customize your existing algorithms or apply two or more algorithms and compare results.
For instance, when Apriorit worked on computer vision with OpenCV, we picked two approaches: machine learning algorithms and a background subtraction algorithm.
Adjust your algorithms as you go. Conduct experiments to evaluate the results of each algorithm you use. Document every step and your results, as this will be valuable for the further development of your solution.
Leverage open-source tools. There’s a great variety of open-source libraries and toolkits that you can use for machine learning development, along with ready datasets and pre-trained models. You can employ several of them in your solution for better testing of your model.
Depending on your needs, you can apply mlpack in C++, Caffe in Python and C++, or NuPIC for streaming analytics in Java, Python, Clojure, JavaScript, C++, and Go.
If you want to implement deep learning in Scala or Java, use a programming library such as Deeplearning4j. When dealing with human language data, NLTK will help you build programs in Python. Shogun toolbox is popular among machine learning developers as it can be used for many languages, including MATLAB, Octave, Python, R, Java, Lua, Ruby, and C#.
Google, Amazon, and Microsoft have already made available their own toolkits for developers, so you can use one of them to create your own product as well.
Retrain and improve your model. Machine learning systems tend to produce less accurate results over time. To prevent this, you need to continuously monitor, test, and retrain your machine learning algorithms and models.
Inspect your model for incorrect learning and biases and regularly audit its results. This is especially vital for models that learn from previous predictions. To simplify this task, you can use model interpretability tools like SHAP and LIME.
Related project
Leveraging NLP in Medicine with a Custom Model for Analyzing Scientific Reports
Explore our success story of developing and integrating an NLP-powered solution to help our client boost their research efficiency. Learn how NLP can transform medical research by accelerating data analysis and summarizing scientific reports with high accuracy.

Conclusion
Deep learning is a subset of machine learning that has a wider range of capabilities and can handle more complex tasks than machine learning. Therefore, the choice between deep learning vs machine learning mostly depends on the complexity of the task at hand. Other factors to take into consideration are the quality and volume of available datasets, your computational resources, and the required speed of calculations.
Developing machine learning solutions requires a deep understanding of machine learning technology as well as advanced knowledge of mathematics and data science. At Apriorit, we have a team of AI development experts who successfully deliver complex machine learning and deep learning projects.
Ready to adopt AI innovations?
Leverage Apriorit’s expertise to build custom AI solutions that enhance performance and capture market opportunities.
Have a question?
Ask our expert!
R&D Delivery Manager


