 Skip to main content
Skip to main content

Network hooks can be used for multiple tasks: monitoring network activity, proxying, creating firewalls, and even controlling and managing client network traffic on the server side.
In this article, we focus on ways you can use network hooks for proxying network activity. We talk about two filters – socket filter and IP filter – and provide a detailed description of the ways you can use these filters to intercept and alter network connections. This article will be useful for macOS developers who want to learn how to manipulate and control network activity in macOS systems.
Contents:
Proxying macOS network traffic with hooks
Hooking is one of the commonly used manipulation techniques that gives a developer control over the behavior of applications, systems, and specific software components. Developers use various hooks to accomplish all kinds of goals, from improving the performance of an application or process to increasing software security.
As the name suggests, network hooks allow you to control the activity that takes place in a specific network. In this article, we focus on the process of hooking and manipulating network activity in macOS systems.
There are two basic ways you can proxy network traffic: in kernel mode or in user mode. In user mode, you can set hooks using the NetworkExtension framework. In kernel mode, you can proxy network connections using two mechanisms:
- Socket filter. This mechanism works at the transport level and allows you to change, delay, or reject traffic. A socket filter is associated with a specific socket.
- IP filter. This mechanism allows you to monitor, change, or block traffic at the network level.
While both of these filters allow you to accomplish similar goals, they work differently and have their own particularities and limitations.
In this article, we focus on macOS kernel mode processes and mechanisms. In the next section, we talk about socket filters, their specifics, and key stages of the socket filter lifecycle. We also provide a detailed guide to setting up network hooks with the help of these filters.
Setting network hooks with socket filters
A socket filter is a mechanism that allows you to intercept network traffic at the kernel socket level. This filter is located between the user space and the kernel’s network protocol stack. Since it works at the kernel level, a socket filter provides limited options for viewing IP or TCP headers of incoming and outgoing traffic, as that happens later in the processing chain. Still, you can successfully filter traffic with the help of a socket filter due to the availability of such metadata as, say, a recipient’s IP address.
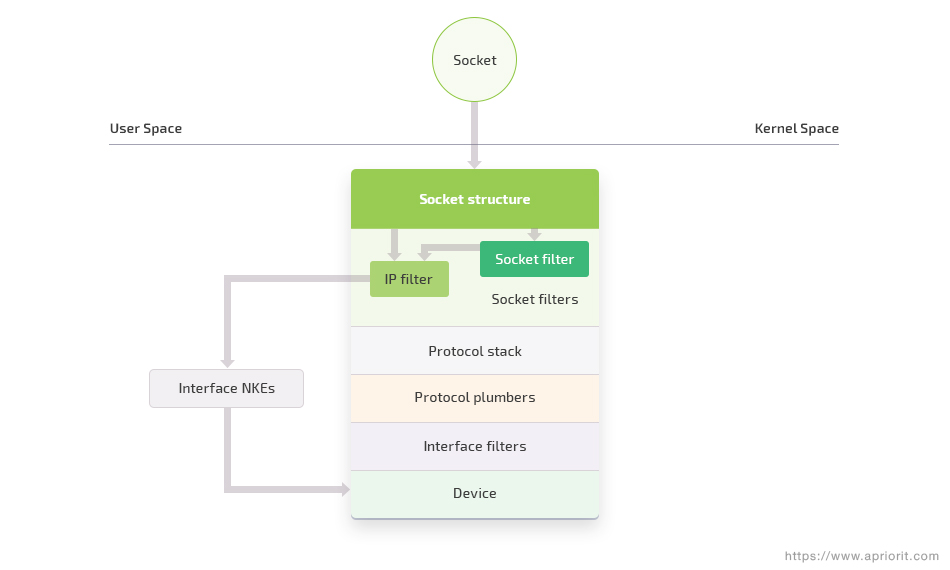
Figure 1: A user-mode socket vs. a kernel-mode socket
Depending on the mode, the term socket has different meanings. In user mode, a socket is a file descriptor, while in kernel mode, it’s a name for a special kernel structure (see Figure 1 above).
Here’s what the lifecycle of a socket filter looks like:
- To register a socket filter, we use the sflt_register function:
extern errno_t sflt_register(const struct sflt_filter *filter, int domain, int type, int protocol);In this function, we have a number of meaningful parameters:
- sflt_filter contains pointers to different functions. These pointers are needed for setting callback functions for specific actions: creating a socket, connecting to an external socket, transferring data, etc.
- A domain may have two types: PF_INET(AF_INET) or PF_INET6(AF_INET6).
- type specifies the type of socket. There are three possible options here: SOCK_STREAM, SOCK_DGRAM, or SOCK_RAW.
- protocol is the identifier of the connection protocol (TCP, UDP, ICMP, RAW, etc.).
- When creating a socket filter, we call the sf_attach_func callback function. This function allows us to set custom cookies that can be used in other callback functions.
- When destroying a socket filter, we call the sf_detach_func callback function. This function helps us clear all resources that were allocated by the sf_attach_func function.
- Using the sflt_unregister call, we unload the network filter. At this point, the system begins to disable all filters that use current sockets. Also, when we create new sockets, the filter won’t be created again.
extern errno_t sflt_unregister(sflt_handle handle);Each filter contains a custom identifier called sflt_handle. Based on this identifier, you can determine which filter needs to be disabled.
Now, let’s look closely at the process of creating a socket filter.
Creating a socket filter
First, let’s see what the socket filter structure looks like:
struct sflt_filter
{
sflt_handle sf_handle;
int sf_flags;
char *sf_name;
sf_unregistered_func sf_unregistered;
sf_attach_func sf_attach;
sf_detach_func sf_detach;
sf_notify_func sf_notify;
sf_getpeername_func sf_getpeername;
sf_getsockname_func sf_getsockname;
sf_data_in_func sf_data_in;
sf_data_out_func sf_data_out;
sf_connect_in_func sf_connect_in;
sf_connect_out_func sf_connect_out;
sf_bind_func sf_bind;
sf_setoption_func sf_setoption;
sf_getoption_func sf_getoption;
sf_listen_func sf_listen;
sf_ioctl_func sf_ioctl;
struct sflt_filter_ext
{
unsigned int sf_ext_len;
sf_accept_func sf_ext_accept;
void *sf_ext_rsvd[5];
} sf_ext;
#define sf_len sf_ext.sf_ext_len
#define sf_accept sf_ext.sf_ext_accept
};In a socket filter, you can set the following parameters:
- sf_handle – an identifier that determines a specific filter
- sf_flags – There are four types of flags you can set or retrieve:
- The SFLT_GLOBAL flag marks a socket filter that should be attached to all newly created sockets. This flag is used for marking the global mode of the socket filter.
- The SFLT_PROG flag marks a socket filter that is only attached to other sockets when it’s requested via the SO_NKE socket option. This flag is used for marking the programmatic mode of the socket filter.
- The SFLT_EXTENDED flag marks socket filters that use extended fields within the sflt_filter structure.
- The SFLT_EXTENDED_REGISTRY flag marks a socket filter that wants to attach to all sockets in the system. This filter will also receive notifications for all sockets it’s attached to.
- sf_name – an arbitrary name that will be set for a specific socket filter
The filter also contains different callbacks (pointers to functions), including the following:
- sf_attach is called when a socket is created. This function allows for setting custom cookies – for instance, cookies for getting a process identifier or process path.
- sf_detach is called when a socket is detached from the filter. At this point, all resources allocated in the sf_attach function are deallocated.
- sf_data_in is called when receiving data.
- sf_data_out is called when sending data.
- sf_connect_in is called by a protocol handler before an external socket connects to the system.
- sf_connect_out is called by a protocol handler when connecting to an external socket.
Now that we know more about the structure of the socket filter, it’s time to see how we can use it for proxying network activity.
Proxying network traffic with a socket filter
The first step we need to take for proxying network traffic is registering a socket filter. To register one, we create a sample sflt_filter structure that contains various fields, including pointers to callback functions.
At the initialization stage, we set the PRX_SF_HANDLE identifier and the SFLT_GLOBAL flag so our filter will attach to new sockets when they’re created. We also add two callback functions, prx_socket_filter_attach and prx_socket_filter_detach, for tracking socket attachments, and the prx_socket_filter_connect_out function for tracking outgoing connections.
// The IP address 5.135.163.178 in binary form in the network byte order
const in_addr_t kDefaultProxyServerIPBytes = 2997061381;
// A handle for the network filter; should be unique for each filter
#define PRX_SF_HANDLE 'prx0'
//The name of the network filter
#define PRX_SF_BUNDLEID "com.proxy.kernel.socketfilter"
// Field description can be viewed in the definition of the filter
static struct sflt_filter s_prx_socket_filter = (struct sflt_filter) {
.sf_handle = PRX_SF_HANDLE,
.sf_flags = SFLT_GLOBAL,
.sf_name = PRX_SF_BUNDLEID,
.sf_unregistered = NULL,
.sf_attach = prx_socket_filter_attach,
.sf_detach = prx_socket_filter_detach,
.sf_notify = NULL,
.sf_getpeername = NULL,
.sf_getsockname = NULL,
.sf_data_in = NULL,
.sf_data_out = NULL,
.sf_connect_in = NULL,
.sf_connect_out = prx_socket_filter_connect_out,
.sf_bind = prx_socket_filter_bind,
.sf_setoption = NULL,
.sf_getoption = NULL,
.sf_listen = NULL,
.sf_ioctl = NULL,
.sf_ext = { 0 }
};After defining the structure, we register the filter using the sflt_register call:
bool prx_register_socket_filter()
{
s_prx_socket_filter.sf_handle = PRX_SF_HANDLE; // Set up a unique handle for the filter
errno_t error = sflt_register(&s_prx_socket_filter, PF_INET, SOCK_STREAM, IPPROTO_TCP); // Register the filter for TCP processing
return (error == 0);Now, let’s take a look at the process of socket creation monitoring. To monitor the creation of new sockets, we set the prx_socket_filter_attach callback function when initializing the sflt_filter structure. In the following code, we create a cookie with a four-byte server IP address. This address will then be used for redirecting outgoing connections. This is how it works:
errno_t prx_socket_filter_attach(void **cookie, socket_t so)
{
in_addr_t* addr_ipv4 = IOMalloc(sizeof(in_addr_t)); // Allocate memory for a cookie
if (!addr_ipv4)
{
return ENOMEM;
}
*addr_ipv4 = kDefaultProxyServerIPBytes; // Set the address of the proxy server in the cookie
*cookie = addr_ipv4;
return KERN_SUCCESS;
}We could also use the server IP address directly in other callback functions with the help of the kDefaultProxyServerIPBytes static variable. However, in this example, we wanted to show how you can set and use a cookie.
Note: In a socket filter, in the attach callback function, you can get information about both a socket and the process that initiated its creation. This information can be placed in a cookie as, for example, a custom structure. If the information about the process will be required in other callback functions, you can get it only from the attach callback function.
With an IP filter, the mechanism is a bit different. An IP filter doesn’t have any callback functions that are called when creating or closing a socket. This filter has a cookie that is set at the initialization of the ipf_filter structure, the ipf_detach callback function that gets notifications about disabling the IP filter, and the ipf_input and ipf_output callback functions that are called when sending or receiving IP packets.
In an IP filter, we can get information about a local or remote socket. This information can be retrieved from the struct __mbuf structure that’s passed to the arguments of the ipf_input and ipf_output callback functions. Theoretically, you can also get information about a process using an IP filter, although doing so will be much more challenging than with a socket filter.
Now, let’s take a look at the process of monitoring outgoing connections.
In the following example, we try to replace the original IPv4 destination addresses with our own. To do so, we first need to check the socket type so we’ll only process IPv4 connections. Then, we’ll bring the sockaddr structure of the destination address to the sockaddr_in structure.
The sockaddr structure is more abstract and is used through the pointer for getting IPv4 or IPv6 structures. The sa_family field in the sockaddr structure points to the type we need to convert the structure to.
If this field has the AF_INET value, then the pointer to indicates data in the sockaddr_in structure. If it has the AF_INET6 value, then the pointer to indicates data in the sockaddr_in6 structure.
To get the IPv4 address from the sockaddr_in structure, we need to use the sin_addr field, which is an object in the in_addr structure. This structure is the one that actually stores the IPv4 address.
Here’s what the process of getting an IPv4 address looks like:
errno_t prx_socket_filter_connect_out(void* cookie, socket_t so, const struct sockaddr *to)
{
if (!cookie || !to) // If cookies weren’t set or the remote address is unavailable, do nothing
{
goto exit;
}
if (to->sa_family == AF_INET) // Process only IPv4 connections
{
struct sockaddr_in* sockaddr_ipv4 = (struct sockaddr_in*)to;
sockaddr_ipv4->sin_addr.s_addr = *(in_addr_t*)cookie; // Set a new IP address
}
exit:
return KERN_SUCCESS;
}As a result, all new IPv4 connections are redirected to the new IP address we’ve specified.
It’s noteworthy that the bind callback function can be processed similarly to the connect_out function.
The detach callback function is called when the filter is detached. This function clears all previously set cookies and other resources that were allocated for the filter.
This is how we can implement the detach callback function:
void prx_socket_filter_detach(void *cookie, socket_t so)
{
if (cookie)
{
IOFree(cookie, sizeof(in_addr_t));
}
}To disable the filter, we need to call the sflt_unregister function:
bool prx_unregister_socket_filter()
{
errno_t error = sflt_unregister(PRX_SF_HANDLE);
return (error == 0);
}To disable a specific filter, use its unique handle that was specified at the initialization stage.
This is what the process of proxying a network connection with a socket filter looks like. In the next section, we look closely at ways you can use the second mechanism – an IP filter – to accomplish the same task.
Setting network hooks with IP filters
An IP filter is a mechanism that allows you to monitor, change, or block network activity at the network level, where you have only packets going in and out. At this level, there’s no connections and sessions – they are processed by higher-level protocols and mechanisms at the transport level, where the socket filter is applied.
The programming interface of the IP filter is similar to the interface of the socket filter.
Here’s what the IP packet header format looks like:

IP filter lifecycle
Similarly to a socket filter, here’s what the IP filter lifecycle looks like:
1. The first phase is the registration of an IP filter with the help of the ipf_addv4 or ipf_addv6 function for IPv4 and IPv6 addresses respectively.
extern errno_t ipf_addv4(const struct ipf_filter *filter, ipfilter_t *filter_ref);
extern errno_t ipf_addv6(const struct ipf_filter *filter, ipfilter_t *filter_ref);There are two main categories of IP filters: IPv4 and IPv6. Both use the same ipf_filter structure to determine the filter.
For registering an IP filter, two arguments are required: filter and filter_ref. Let’s look at each:
1) filter is a structure that determines IP filters. The filter structure allows for setting cookies and the filter name. Cookies can be used in all callback functions, and the name can be used for determining a specific filter.
struct ipf_filter
{
void *cookie;
const char *name;
ipf_input_func ipf_input;
ipf_output_func ipf_output;
ipf_detach_func ipf_detach;
};In this structure, there are a number of fields:
- ipf_input for setting a callback that’s called when receiving IP packets
- ipf_output for setting a callback that’s called when sending IP packets
- ipf_detach for setting a callback that’s called when the filter is detached
In contrast to socket filters, IP filters should be explicitly detached or removed by calling the ipf_remove function.
2) filter_ref is a link to the filter. It’s a pointer to the opaque_ipfilter struct that’s initialized when creating a new filter. This pointer is mostly needed for disabling a specific filter, but it also can be used in other IP filter functions.
2. The second phase of the IP filter lifecycle is receiving incoming and outgoing IP packets in the ipf_input and ipf_output callback functions respectively.
3. The next phase is disabling the filter with the help of the ipf_remove function.
extern errno_t ipf_remove(ipfilter_t filter_ref);The filter_ref argument is the filter link that was initialized when we set the filter.
4. The final phase is processing the ipf_detach callback function. This function will only be called if it was set when the filter was initialized.
An IP filter allows you to both change the address of the receiver and alter any part of the packet, including the data at the application level. Also, this filter can be used to fully replace a current packet with a new one.
Now, let’s see what steps we should take to proxy network traffic with the help of an IP filter.
Proxying network traffic with an IP filter
First, we need to set the IP filter structure by filling in the required fields and callback functions.
//The IP address 5.135.163.178 in binary form in the network byte order
const in_addr_t kDefaultProxyServerIPBytes = 2997061381;
#define PRX_IPFILTER_NAME "org.prx.ctl" // A unique name of the filter
static struct ipf_filter s_prx_ip_filter = {
.cookie = NULL,
.name = PRX_IPFILTER_NAME, // The name of the filter
.ipf_input = NULL,
.ipf_output = prx_ip_filter_data_out, // The callback function for the outgoing traffic
.ipf_detach = NULL
};
static ipfilter_t s_prx_ipf_v4_ref; // Add a link to the filter. The variable is needed for initialization and deinitialization of a specific IP filter.Next, we move to filter registration:
bool prx_register_ip_filter()
{
errno_t error = ipf_addv4(&s_prx_ip_filter, &s_prx_ipf_v4_ref); // Register the IPv4 IP filter
return (error == 0);
}Once the filter is registered, the system starts calling the set callback functions. Let’s look closer at one of them: the data_out callback function that’s called when sending IP packets.
The capabilities of the IP filter aren’t limited to the sending of packets. This filter also allows you to alter and decline packets as well as implement your own packets.
In the following example, we show you how to change the destination IP address to a custom address.
First, we need to get the data from the mbuf_t pointer. We can do this using the mbuf_data function, which will return the pointer to the beginning of the data. To get the length of the data, we can use the mbuf_len function.
Once we get the struct ip data pointer, we check its type for processing the IPv4 addresses. Then, we replace the s_addr destination address in the ip_dst structure stored in struct ip with our own IP address.
Since the packet was changed, we need to inject it once again. But the system will see this packet as a new one, so it will be processed by the current filter once more. To avoid this repeated processing, we need to pass the s_prx_ipf_v4_ref filter link to the ipf_inject_output packet implementation function.
If the alteration of the current packet is successful, we’ll need to stop further processing of this packet. To do so, we need to bring back the EJUSTRETURN value in our current callback function, which will free the packet and stop its further processing.
errno_t prx_ip_filter_data_out(void *cookie, mbuf_t *data, ipf_pktopts_t options)
{
kern_return_t ret = KERN_SUCCESS;
struct ip *ip = (struct ip *)mbuf_data(*data); // Receive a pointer to the beginning of the data
static const uint32_t kIPv4AddressType = 4; // Set the value to 4 to specify the type for processing IPv4 addresses
if (ip->ip_v == kIPv4AddressType)
{
ip->ip_dst.s_addr = kDefaultProxyServerIPBytes; // Set a new destination IP address
ret = ipf_inject_output(*data, s_prx_ipf_v4_ref, options); // Inject an IP packet as though it had just been sent to ip_output
}
return ret == 0 ? EJUSTRETURN : ret;
}Once this callback function is called, all outgoing IPv4 traffic will be redirected to the IP address specified in the kDefaultProxyServerIPBytes variable.
Finally, we can finish our work with the IP filter with the following actions:
bool prx_unregister_ip_filter()
{
bool result = true;
if (s_prx_ipf_v4_ref) // If the IP filter was registered
{
errno_t error = ipf_remove(s_prx_ipf_v4_ref); // Remove the registered filter
if(error != 0)
{
result = false;
}
}
return result;
}This is what the process of proxying network traffic with an IP filter looks like. As you can see, it isn’t that difficult if you’re attentive and follow the instructions.
Conclusion
In this article, we described the ways you can proxy network traffic and what network hooks are better to use in macOS systems. We examined two macOS mechanisms – socket filter and IP filter – that can be used for monitoring, altering, and declining network traffic.
A socket filter works at the transport level and provides you with a wide range of capabilities for getting the data you need. An IP filter, in turn, works at the network level and, compared to a socket filter, has limited capabilities. At the same time, an IP filter is much easier to use than a socket filter.
We also took a look at the hooks that are part of macOS kernel mode. Similar hooks are also present in user mode, particularly in the NetworkExtension framework, but their capabilities are limited. Maybe we’ll get back to investigating the true potential of user mode hooks in macOS systems in future articles.
At Apriorit, we have a dedicated team of macOS developers and network monitoring and management engineers whose key priorities are data security, system performance, and continuous improvement. They’ll gladly assist you in implementing the macOS project of your dreams. Get in touch with us to discuss the details.
Have a question?
Ask our expert!
Program Manager


