 Skip to main content
Skip to main content

As the volume of stored data grows, building the necessary data infrastructure can cost a fortune, and spending is likely to increase in the future. This is why more and more IT companies are abandoning traditional storage in favor of cloud object storage services. According to a forecast (subscription required) by Gartner researchers, the share of Infrastructure & Operations (I&O) leaders that implement at least one hybrid cloud storage capability will increase to 40 percent in 2024, up from 15 percent in 2020.
In this article, we provide a comprehensive overview of the Amazon Simple Cloud Storage System (S3), also known as AWS S3 — an advanced data storage service from a world-renowned company. We explore what Amazon S3 is, its key use cases, and ways you can use this cloud storage service in your product (using Apriorit projects as examples).
Contents:
What is Amazon S3?
Amazon Simple Storage Service (Amazon S3) is a storage service that operates on data as objects, allowing data to be stored in its original format. It’s best suited for storing website content, analytics data, as well as mobile and web application files. In Amazon S3, a user has a wide range of options for organizing data, setting access levels, and integrating with other Amazon services. The Amazon S3 service is already used by advanced companies from around the world, including Dropbox, Twitter, Lyft, Pinterest, Reddit, Airbnb, Netflix, and Spotify. For reducing data access latency, the S3 service can be deployed in any region with AWS infrastructure: North and South America, Europe, Africa, the Middle East, and Asia.
Amazon S3 features
Amazon’s data centers use purpose-built hardware and distributed file systems, which allow for implementing a wide list of features. Let’s briefly go over some of the key features:
- Unlimited number of objects stored
Amazon S3 lets you choose how much data to store and how to access it. This storage solution is independent of the client file system and provides distributed access to objects, which can range from 1 byte to 5 terabytes. As a result, S3 storage is particularly suitable for cloud environments and stateless containers. Object storage makes objects directly available on the web. Also, there are software development kits (SDKs) for many programming languages.
- High performance
Amazon S3 supports parallel requests, so its performance can be scaled by the factor of your computer cluster without making changes to the application. Amazon S3 claims to be able to perform at least 3,500 write requests per second to add data and 5,500 read requests per second to retrieve data.
- Data integrity control
In S3, every object is stored simultaneously in multiple locations. As soon as an object enters storage, Amazon S3 takes care of its reliability by regularly checking and repairing files using redundant data. In addition, the service regularly checks the integrity of stored data using checksums.
- Access control
The S3 service supports transferring data over the SSL protocol with automatic data encryption at the end of the download. If necessary, it’s possible to configure container management policies for object permissions and control access to data using the Amazon Identity and Access Management (IAM) system.
- Support for REST and SOAP APIs
Amazon S3 provides simple standardized Representational State Transfer (REST) and Simple Object Access Protocol (SOAP) web service interfaces. This makes it easy to work with any web development toolkit.
- Direct query capabilities
AWS S3 also provides direct query capabilities that allow powerful analytics to be performed directly on the stored data. This is convenient for big data analytics.
- Logging and monitoring capabilities
To ensure data security, AWS offers a variety of logging and monitoring capabilities in S3. In particular, it enables tracking of server access requests and monitoring of user actions and different application performance metrics.
- Consistency checks
Amazon S3 automatically checks the consistency of read after write operations across all applications. This process is completely free and doesn’t affect the performance, availability, or regional isolation of applications.
- Creation of Lambda functions and S3 Event Notification data chains
Amazon offers the AWS Lambda service for handling event notifications. This Amazon S3 feature provides visibility into Lambda function calls and forwards execution results to AWS services, simplifying event-driven applications and reducing code complexity.
- Integration with other Amazon services
AWS S3 is an Amazon product, which means you can integrate it with a vast number of the company’s services. This is extremely convenient if you either already use other Amazon products or need their functionality. The Amazon ecosystem allows you to set up optimal interactions between services.
Now that you know what this service can do, we can take a closer look at the basic principles of how Amazon S3 works.
How does Amazon S3 work?
Amazon S3 acts as a regular web service, allowing users to upload/download files via a public API. It is based on the HTTP/HTTPS protocol, and like HTTP/HTTPS, it uses the Get command for downloading and Put for uploading.
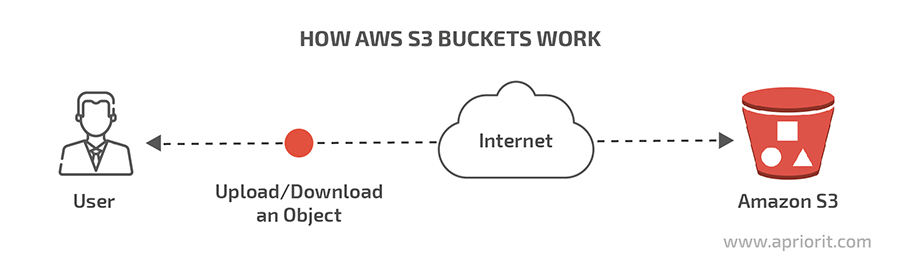
Data in S3 storage is kept as objects, whereas the traditional way to store data is as files. Each object has a unique identifier that also serves as an access key. Data encryption is ensured with 256-bit AES. Also, AWS offers a range of options for protecting your data with server-side and client-side encryption.
Objects in storage contain the data itself, which occupies the most volume, along with two types of metadata. The first type is system metadata used by Amazon S3 to obtain such information as the object’s creation date, size, and time of last modification. The second type is metadata defined by a user, such as key–value pairs. Together, metadata and the data itself help AWS S3 to identify and efficiently organize work with information in storage.

Separating metadata and data allows clients to handle information separately at the metadata level, allowing the S3 service to efficiently query data and load only the necessary objects when needed. Metadata, as well as object’s data, supports access control management.
Amazon S3 uses so-called buckets to group objects. A bucket is actually a container for objects of a certain type. Buckets must have names that are unique within the entire AWS infrastructure.
Load balancing in AWS is ensured with a special Elastic Load Balancing (ELB) utility. It has the following features and capabilities:
- It can be used both internally and externally
- It allows for directing traffic to instances in one or more availability zones in a given region
- It performs regular checks on target instances, and if an instance becomes corrupted, it redirects the traffic
- It can be integrated with the AWS Auto Scaling service, which allows instances to be added and removed automatically when Auto Scaling scales up or down
- It offers an application load balancer for content-based routing and SSL
- It offers a Network Load Balancer for high performance, low latency, and Layer 4 connections
To better understand the way Amazon S3 works, let’s overview common Amazon S3 use cases.
Amazon S3 use cases
Amazon S3 is convenient for low-cost storage and mass distribution of information in large volumes. S3 storage can be embedded into any application, be it a mobile game, video hosting service, or corporate document management system. In particular, AWS S3 can be used for:
- Hosting content of websites and mobile apps
Any kind of data can be placed in object storage: audio and video files, documents, backups, code fragments. This solves two main tasks: providing reliable storage for any volume of data and quickly distributing that data to any number of users. You can also store a whole application on S3 servers for your customers to download.
- Single-page application hosting
AWS S3 allows users to deploy single-page applications (SPAs) on Amazon servers. The pay-as-you-go model and infrastructure that scales to any size allow developers to conveniently store SPAs written on Angular, React, and other popular frameworks.
- Data backup and recovery
Using the integrated AWS Command Line Interface (CLI), users can place code files and make backups and versions (i.e. create a code repository). This allows you not to worry about the amount and reliability of storage for development-critical data.
- Archiving
Amazon S3 allows you to archive data with S3 Glacier and S3 Glacier Deep Archive. You can also restore archived objects in as little as a minute for urgent retrieval and from three to five hours for standard retrieval. Large data recovery from S3 Glacier and all S3 Glacier Deep Archive recoveries are performed within 12 hours.
- Big data analysis
You can use AWS Lake Formation to quickly create a data lake. This service collects data from all your databases and resources in Amazon S3, moves it to a new data lake, cleans it up, and classifies it using machine learning algorithms.
As you can see, the scope of Amazon S3 use cases is quite wide. Let’s take a look at how to use Amazon S3 in practice.
Amazon S3 implementation scenarios
At Apriorit, we work closely with Amazon S3, as this storage service provides uninterrupted access to data from anywhere in the world and is highly protected from unauthorized access requests. In particular we use it for:
- hosting SPAs written on Angular
- ensuring integration between distributed teams and applications
- enhancing MongoDB report exporting
- exchanging documents
- saving license agreements in a bucket
- securely exchanging passwords
Below, we describe two Amazon S3 implementation scenarios used in one of our recent projects:
- Exchanging files among users
- Storing publicly accessible files
Let’s take a brief look at each of them.
Exchanging files among users
Our task was to make it possible for users of a web portal to exchange documents. The space on the application server is usually limited to executable files and markup pages. The user files may be quite large, and it’s difficult to predict the number and volume of uploaded files. Also, it’s not an easy task to set up a service that will respond to user requests and upload or download files. It’s important for such a service to support authentication and authorization as well. We chose the AWS S3 service as it meets all these criteria.
Let’s look at a diagram of how we organized the file exchange process:
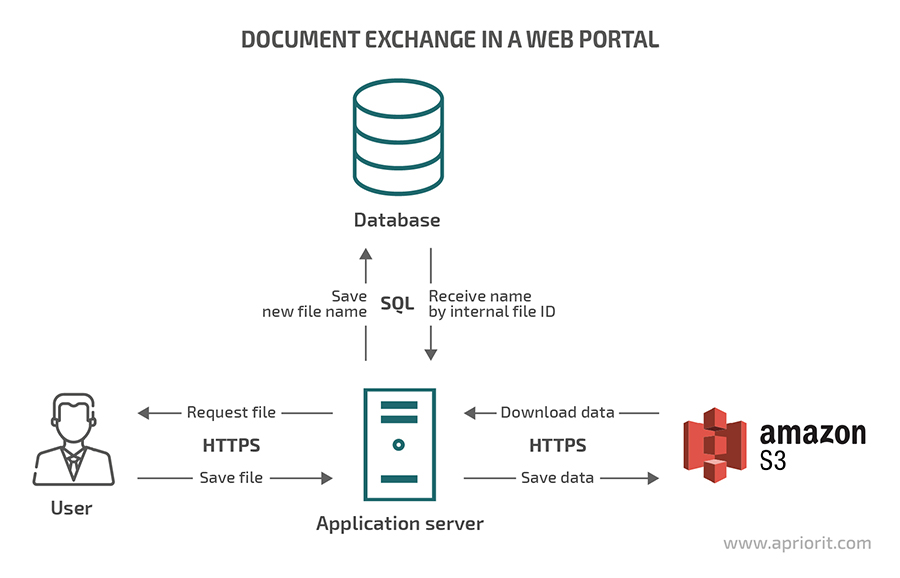
After being authenticated and authorized by the application, a user makes a request to the application server via the secure HTTPS protocol to download or upload a file. The application server then retrieves the name of the desired file from the database by its identifier in the customer’s system or generates a new name when a new file is uploaded.
With the file name known to the S3 repository and using the access keys to the S3 service, the application server now generates another request using the HTTPS protocol. With the help of the public REST API, the server retrieves the desired file with an existing name or uploads a new file with a pre-generated name. After getting the data from the repository, the application server sends that data to the user. The user may have no idea how the files are actually physically stored. These functions are performed by the S3 repository.
Storage of publicly accessible files
The other use case is quite common in mobile app development and concerns files that should be publicly accessible, such as user avatars.
Let’s take a look at the following scheme:
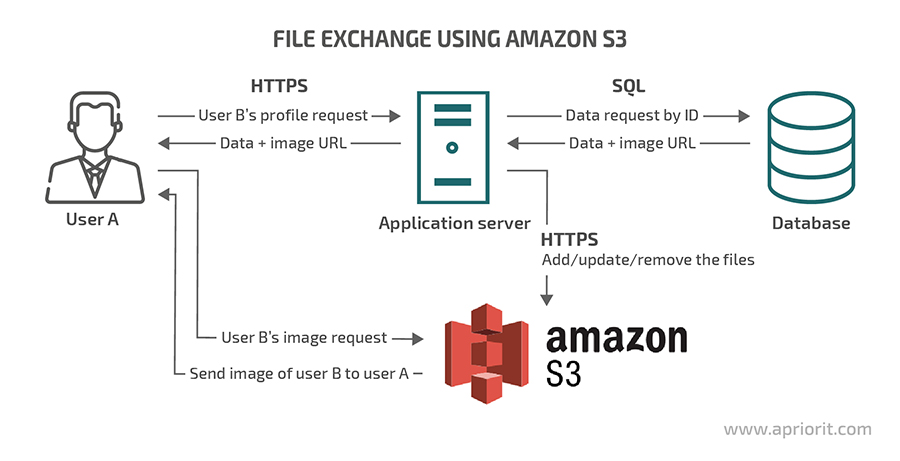
Here, user A requests a profile of user B from the application server. In the server’s response, there is only text data. This way, only the public URL to the avatar file stored in the S3 repository is sent as an image. After that, user A makes another request directly to the public API of the S3 service and receives the desired image.
Why we used Amazon S3
Amazon S3 is quite convenient for tasks related to storing and sharing files. In the case of exchanging user files, the AWS S3 benefits are as follows:
- AWS S3 takes care of the user authentication and authorization procedures
- No need to deploy your own service (API) for file storage
- No need to allocate disk space on the application server or any other server for file storage
- Easy management of available space via the web interface
- User-friendly storage file manager accessible from the AWS console
In the second scenario, the advantages are the same as above. However, we get an additional benefit of the application server not being involved in processing the user’s file access requests at all. This responsibility is transferred entirely to the S3 service, and the server is completely free from performing these simple but resource-consuming requests.
Conclusion
Storing huge amounts of data and ever-increasing infrastructure costs are challenges for companies of all levels and sizes. Amazon S3 can help because of its rich list of features and pay-as-you-go model. It can be used for securely storing all kinds of data, whether it’s website content, information from IoT devices, or big data. Using S3 storage, you can significantly reduce infrastructure costs as well as increase the efficiency and speed of your system.
Amazon S3 is only one of the many tools our experts use to build highly performant cloud systems. Contact us and we will assist you with smooth and fast implementation and setup of your cloud storage.
Have a question?
Ask our expert!
VP of Innovation and Technology, Canada Branch Director


