 Skip to main content
Skip to main content

Key takeaways:
- Ensuring compatibility with closed file formats can help businesses significantly enhance software capabilities and improve product competitiveness.
- Reverse engineering proprietary file formats is often the only way to make your solution compatible with them.
- The biggest challenge of reversing is that each file format requires a unique approach.
- The set of reversing approaches you can realistically choose among will depend on how much information your engineers obtain ー and for closed file formats, such information is usually extremely limited.
- To conduct a comprehensive proprietary file format analysis and achieve the desired compatibility benefits, work with engineers who have deep knowledge and rich experience in the field.
Support for different file formats is an essential advantage for any software product, no matter its type, size, and target industry.
It is relatively easy to ensure compatibility with open file formats because documentation is available. However, proprietary, or closed, file formats are a real struggle. The main challenge is that there’s no one-size-fits-all solution for reversing a proprietary file format. In each case, you have to choose your approach depending on the data at hand.
In over 20 years of practicing ethical reverse engineering, we have learned how to analyze and reverse almost anything. From analysis of software, hardware, and firmware to APIs and even proprietary file formats, we help clients enhance their products’ capabilities.
Now, it’s time to share our experience of successfully handling tasks related to proprietary file formats. Read on for practical examples and valuable insights. This article will be useful for development leaders who want to enhance their product’s interoperability by supporting closed file formats.
Contents:
- Three ways to identify a proprietary file format
- 1. How to determine a proprietary file format based on the file signature
- 2. How to reverse engineer the data format using an executable file
- 3. How to reverse engineer a data format without an executable file
- How Apriorit can help with reverse engineering tasks
- Conclusion
Three ways to identify a proprietary file format
There’s no general approach to reverse engineering a closed file format that works every time. Each case is individual.
In this article, we explore three examples of restoring a proprietary file format for different cases:

Let’s dive into each scenario, starting with the one where we can avoid reverse engineering altogether.
Need help reversing a proprietary file format to improve compatibility and meet critical business goals?
Delegate this task to Apriorit’s experienced reverse engineering specialists. We use proven tools, ethical methods, and legal approaches to deliver actionable insights.
1. How to determine a proprietary file format based on the file signature
Work with any file format starts with discovering the format’s name and finding a parser that can work with it. Sometimes, this process can be straightforward, and you can find a relevant parser by simply typing “<file extension> parser” in Google.
However, a file extension sometimes doesn’t match the file’s real format. For example, computer games often specify their resource file extensions as DAT, although inside they can be ZIP files. Also, some video formats based on the Matroska container use a custom codec for streaming videos, and therefore they have non-standard file extensions.
To determine the file format, you can use specialized tools such as:
- file(1) — a tool for determining file types in Linux
- Binwalk — a tool for analyzing, reverse engineering, and extracting firmware images
- FACT extractor — a tool for extracting most common container formats
Then, you need to check whether a file is archived and encrypted. A way to do this is by using the Data Visualizer feature in Hex Workshop.
If a file is likely to be archived, try opening it with 7-Zip. Surprisingly, this file archiver can identify formats by scanning the beginning of the file. Even if a file has some custom header before ZIP data, 7-Zip still can identify it.
Another helpful tool is Offzip, which allows you to search for zlib streams in binary code and extract them as files.
All these tools provide an opportunity to identify known file formats and avoid file format reverse engineering without an actual need. But if you fail to find the file format, you can try to search for it using the file’s signature. To discover the file’s signature, open your file in a hex editor.
A file signature, also known as a magic number, is a unique sequence of bytes at the beginning of the file that’s used to identify its format. Usually, the file signature refers to the first two to eight bytes of a file. Once you have a file’s signature, search for magic numbers on Google and GitHub, using different variants of how these digits can be described on websites or in code.
Say your file’s signature starts with the following bytes: 41 50 52 34 65 76 65 72. Here are a few examples of search requests you should try:
- 41 50 52 34 65 76 65 72 signature
- 41 50 52 34 65 76 65 72 magic
- 41 50 52 34 signature
- 41 50 52 34 magic
- 41505234 (because the signature can also be a DWORD)
- 0x41 0x50 0x52 0x34 0x65 0x76 0x65 0x72 signature
- 0x41505234
- 0x34525041 (in case it’s little-endian)
- You can also use American Standard Code for Information Interchange (ASCII). In our case, our search query for the file signature will look like “APR4ever.”
Such an approach can help you identify what this file format is similar to or even find a ready-to-use parser. You can also find other files in such a format and analyze who created them and how they can be parsed.
2. How to reverse engineer the data format using an executable file
If you didn’t manage to find something after thoroughly searching for a file signature on Google, it can mean that your file format is indeed rare. In this case, you can start reverse engineering your proprietary file format using an executable file that can parse this particular format.
But how can you find this executable file? There are two options:
- Find the executable file by the signature of the target file
- Analyze the target file at runtime
Let’s briefly explore each approach.
Option 1: Find an executable file by the signature of the target file
Scan the entire program catalog that works with the file you plan to reverse engineer, searching for the signature in binary form. Launch a search by file contents to find a signature that matches your target file. Look for the bytes the target file begins with using specialized tools like Effective File Search or Total Commander for Windows or a command-line tool like grep or Binwalk on Linux and macOS respectively.
If you manage to find a matching signature, load the executable file into the interactive disassembler (IDA), search where the file signature is checked, and start reversing the code that performs further parsing of data.
If a file doesn’t have a signature or you don’t find anything when searching by file contents, you can analyze the file at runtime.
Option 2: Analyze the target file at runtime
Launch the Process Monitor, set a filter for file operations, and try to catch the moment when the proprietary file is opened. Then, look at the relevant row in the Process Monitor to find a CreateFile operation or the first ReadFile for your file. Look at the Stack of this event to see which executable file attempted to call ReadFile() and, what’s more important, what the address is in the code. Upload your file to IDA and see how the parsing runs, just like with signature search.
Quite often, the code for parsing is located close to the place where reading starts. In such a case, look at all the ReadFile operations, see how many bytes are read, and see where these bytes are located in the file.
However, some files can be developed in a more complicated way. For example, a developer could have used classes of streams or even custom classes to access files based on the hierarchy of classes with virtual functions and multithreading instead of using simple functions for reading files.
In such cases, when you find the ReadFile function, you won’t find any parsing code close to it. All you’ll see is a ReadFile that’s called from some virtual function, and the read data will be stored in a buffer.
In this scenario, you’ll have to:
- Recover the class of the reader
- Find the class that uses the reader to receive data from the buffer
- Understand how that class synchronizes with the reader
Only then can you find the class that parses the data from your file.
However, sometimes you might need to recover data from a file having neither a signature nor an executable file. Let’s explore what can be done in such cases.
3. How to reverse engineer a data format without an executable file
Before we start exploring an example of how to recover data from a proprietary file format without an executable file, let’s briefly overview the general logic of how information is stored in a file.
It’s important to understand that all files have structured data. No one creates file formats in a way that allows for randomly placing objects.
Every file format has a certain logic. And this logic is usually related to the file’s purpose. For example, files of filesystem images must have specific structures to be able to store metadata such as size, name, and other attributes. Image files must be able to store information about an image’s size, the number of colors, and other image metadata.
Developers usually have limited options for organizing information storage in a file they create. The choice of logic is usually based on the developer’s knowledge and experience. There’s no need to overcomplicate such a task and try to come up with original ideas, especially when creating a proprietary file format.
Related project
Auditing the Security of a Connected Vehicle Communication System
We share a real-life example of strengthening a car’s communication system with reverse engineering. Discover the steps it takes to assess a vehicle communication solution, identify vulnerabilities, and implement measures to boost both performance and system protection.

Now, let’s explore how to reverse engineer a file format using a real-life example. Here we have a random firmware file in a closed format. We can’t find any information on the internet based on its signature, and it doesn’t have a distinct extension that can help us identify the format.

Apparently, the data is in the largest file: swfl_00005684.bin.001_032_079. But we also can see the swfl_00005684.xml.001_032_079 file, which can be useful for uncovering how to parse data from the target file.
The first rule is don’t neglect metadata.
In this case, we see an XML file near the file we want to recover. Once we open the swfl_00005684.xml.001_032_079 file, we discover a description of the BIN file parts:
<flash-segments>
<flash-segment compression-status="UNCOMPRESSED">
<short-name>swfl_00005684_0042A00</short-name>
<source-start-address>0000000</source-start-address>
<source-end-address>00001FF</source-end-address>
<target-start-address>0042A00</target-start-address>
<target-end-address>0042BFF</target-end-address>
<compression-method>UNKNOWN</compression-method>
<checksum>371E</checksum>
</flash-segment>
<flash-segment compression-status="UNCOMPRESSED">
<short-name>swfl_00005684_0115000</short-name>
<source-start-address>0000200</source-start-address>
<source-end-address>00005CD</source-end-address>
<target-start-address>0115000</target-start-address>
<target-end-address>01153CD</target-end-address>
<compression-method>UNKNOWN</compression-method>
<checksum>0D73</checksum>
</flash-segment>
<flash-segment compression-status="UNCOMPRESSED">
<short-name>swfl_00005684_0F15000</short-name>
<source-start-address>00005CE</source-start-address>
<source-end-address>043BA91</source-end-address>
<target-start-address>0F15000</target-start-address>
<target-end-address>13504C3</target-end-address>
<compression-method>UNKNOWN</compression-method>
<checksum>EE1F</checksum>
</flash-segment>
</flash-segments>In this example, SOURCE-START-ADDRESS points to the beginning of the fragment that offsets in the BIN file. And SOURCE-END-ADDRESS is the end of this fragment.
After extracting data fragments from the swfl_00005684.bin.001_032_079 file, as described in the XML file, we get three files. One of them is a digital signature, and the other two have another proprietary format with the HAR#$%&@ signature.
We find out that these two files are archives. The first clue is that Data Visualizer shows us that the files have a little text in the beginning and then have high-entropy data.
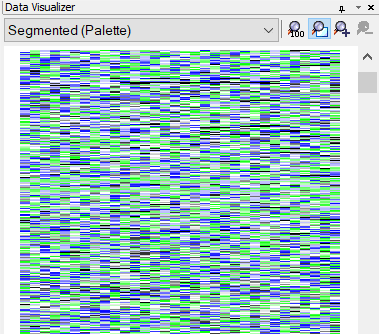
Read also
Best Reverse Engineering Tools and Their Application: Apriorit’s Experience
Discover the most useful software reverse engineering tools. See how they can benefit your project, from security research and vulnerability assessment to malware analysis and system optimization.

The second clue is how this file looks in a hex editor:

It looks like a table with the names of files from an archive. However, the challenge is to find a way to parse this data so we can connect zlib streams with their metadata.
Since we have determined that this is information about files in an archive, we will paste this data into Notepad to see which data will change and which not. Here’s what we end up with:

Therefore, there are high chances that the file’s metadata saved in an archive will contain information like create/update dates, attributes, and the size of compressed and decompressed files.
Information about create/update dates will vary a little for different files within the archive, because the file metadata is usually presented in Unix Time format. This is why we can see that this data is mostly repeated.
The second rule we can learn working with this file is to know how common data types look in the hex editor. By common data types, we mean Unix Time, Dos Time, Float, Double, etc.
It’s obvious that if metadata contains a catalog description (not a file), it won’t have sizes mentioned.
After the directories, we have an entry as shown in the screenshot below. Since it’s a file descriptor, this entry has the size fields filled with values.

For the sake of curiosity, we use the Offzip scanning tool to confirm our guess, and here’s the result:
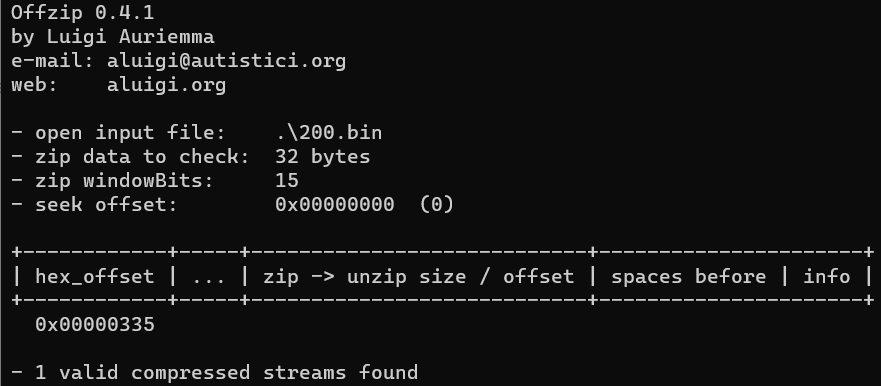
Let’s see the data we have at the end of the HAR file at offset 0x335:

It’s a zlib stream at offset 0x335 which has the length of 0x99 bytes.
These are the same digits we’ve already seen in the metadata. So we can conclude that this HAR file only contains the /tmp/manifest/usr/share/swe/00005684/00f15000.manifest file, and the rest are catalogs.
So, we extracted a file of unknown format only using data from the file itself because we understood what we expected to find there.
How Apriorit can help with reverse engineering tasks
With more than two decades of experience in the fields of cybersecurity, software development, and reverse engineering, we offer a wide range of services:

The Apriorit team is ready to help you with tasks of any complexity:
- Analyze complex software systems, binaries, and undocumented code
- Improve product compatibility, even with proprietary and closed file formats
- Detect vulnerabilities, assess risks, and identify weaknesses
- Restore lost or damaged documentation and recover architecture
- Protect your intellectual property while optimizing system performance
- Resolve challenges with outdated and vulnerable code
- Enhance legacy systems and improve their maintainability
- Reveal hidden security risks and reinforce system protection
- Ensure smooth product evolution, even for legacy software
We ensure your system is secure and maintainable for future growth. Apart from deep software and hardware analysis, our engineers will also help you implement robust security improvements for long-term reliability.
Conclusion
Knowing how to reverse engineer a proprietary file format can help you ensure your software works with a wide variety of file formats.
But reverse engineering a closed file format is challenging. It requires not only expert skills in reverse engineering but also deep knowledge in lots of other topics. For example, it’s essential to pay attention to other files that are stored near the one you need to reverse engineer and know what different data types look like in a hex editor.
At Apriorit, we have experienced teams of reverse engineers who are ready to help you with any project. Apart from working with closed file formats, our expertise includes researching malware, searching for vulnerabilities in embedded software, analyzing for intellectual property rights violations, as well as supporting and patching undocumented code.
Want to improve your software’s interoperability and security?
Leverage Apriorit’s expert skills in reverse engineering and ability to solve challenging and non-trivial tasks. Let’s find the best solution for your project together.
FAQ
What is a proprietary file format?
This is a closed format that’s often designed to be secret: the specification of the data encoding format is not publicly released, or is only disclosed under NDAs. Data in a proprietary file format usually can’t be decoded and interpreted without proprietary software or hardware.
What is an example of a proprietary file format?
Well-known examples of proprietary, or closed, file formats are WMA and CDR. Older Microsoft formats like DOC and XLS were once closed and undocumented, but Microsoft has since published their specifications and introduced open standards such as DOCX and XLSX.
Why would you need to reverse engineer a proprietary file format?
The most common reason for software developers to reverse engineer a proprietary file format is to improve software interoperability and enhance compatibility.
Is it legal to reverse engineer a proprietary file format?
Generally, reverse engineering of file formats is considered legal when it’s used for improving interoperability and for computer forensics. Note, however, that legal positions on handling closed file formats differ according to each country’s laws related to software patents.
What tools or libraries can help with reverse engineering file formats?
The technology stack for reverse engineering depends on the file type and project goals. Commonly used hex editors include HxD, 010 Editor, and ImHex for inspecting raw binary data. For file format analysis and parsing, we recommend choosing Binwalk, Radare2, or Ghidra.
Have a question?
Ask our expert!
Program Manager


