 Skip to main content
Skip to main content

Key takeaways:
- Data poisoning is a critical threat to AI-driven products and services, as it affects accuracy and causes compliance and security risks.
- Attacks range from subtle backdoor infiltration to large-scale integrity corruption, so your development team should know the most likely scenarios to ensure proper protection.
- Detecting AI data manipulation is challenging and requires multiple practices including data quality validation and continuous monitoring.
- Mitigating these risks requires specific expertise in secure MLOps, custom dataset sanitization, adversarial training, and penetration testing.
AI adoption has already become a strategic advantage for many businesses. But along with efficiency and innovation, it also introduces new vulnerabilities that are challenging to handle. Data poisoning is one of them.
The aim of manipulating datasets is to compromise model integrity. For many businesses, this risk is hard to grasp because:
- Few organizations know how to design a secure AI project from day one.
- There’s a limited understanding of how AI poisoning impacts business operations.
- Detecting poisoned data in massive datasets is extremely difficult.
- In-house teams often lack expertise in AI-specific threat detection.
This post is meant to help CTOs, product managers, and development leaders design resilient and powerful AI systems by explaining what data poisoning is, why it matters, and how your team can prevent it. You’ll learn about types of attacks (with real-world examples), business risks, and practical prevention tips from Apriorit experts.
Contents:
- What is data poisoning in AI?
- What are the main types of AI data poisoning?
- What are the consequences of AI data poisoning attacks?
- Why is it hard to mitigate AI data poisoning?
- How to prevent AI data poisoning with 7 tips from Apriorit experts
- Prevent data poisoning in your product with Apriorit’s expertise
What is data poisoning in AI?
Data poisoning refers to manipulating pre-training, fine-tuning, or embedding data with the aim to introduce vulnerabilities, backdoors, or biases. To compromise a model’s behavior, an attacker can inject malicious samples, alter labels, or tamper with raw data or preprocessing steps in other ways.
As a result of data manipulation, AI models show performance degradation and face potential security issues. This can turn an AI product from an asset into a liability.
To prevent costly failures, it’s crucial to understand real-life risks and plan proactive prevention measures: dataset validation, data sanitization, ongoing performance monitoring, etc.
Olya Kolomoets, VP of AI Engineering and Integration at Apriorit
AI data poisoning often happens during the training phase, either when a team uses corrupted datasets (or datasets of poor quality), or a malicious insider manipulates correct data. Such actions cause large language models (LLMs) to learn incorrect patterns.
However, poisoning risks remain even after successful training and deployment, especially for LLMs that continue learning from real-world interactions. This means that even a well-trained model can become compromised if it ingests poisoned content during post-release updates or reinforcement learning cycles.
Let’s explore a few scenarios to better understand the real-world impact of data manipulation on businesses.
Examples of potential data poisoning impact on industry-specific AI products:
| Industry | Data manipulation scenarios |
|---|---|
| Automotive | A sticker on a stop sign could trick a self-driving car into reading it as a speed limit sign, creating safety hazards. |
| Cybersecurity | Poisoned logs or network telemetry used to train anomaly detection systems can significantly degrade the detection of malware or intrusion attempts. |
| FinTech | Attackers could manipulate transaction patterns so fraud detection models fail to flag illicit transfers. |
| Healthcare | Poisoned training data might cause an AI diagnostic tool to misinterpret medical images, leading to incorrect treatments. |
| Retail & E‑commerce | AI recommendation engines trained on poisoned customer data may start suggesting irrelevant or unwanted products, damaging loyalty and increasing return rates. |
| Internet of Things | Poisoned training data for voice or sound recognition models could embed hidden trigger commands for IoT devices in background music that could silently open smart locks or doors without the user’s awareness. |
| Transportation & Logistics | Flashing lasers at station cameras could mislead models into believing a train platform is fully occupied, disrupting railway operations according to researchers from Florida International University. |
| Energy | AI systems used in grid management or fault detection could be misled by contaminated sensor data, causing false alerts or failing to detect real outages. |
Any industry that leverages AI algorithms to enhance their products or services might be at risk of data poisoning.
Data poisoning attacks may take different forms, each with unique implications for business operations and security. In the next section, we take a deep look at attack types, as understanding the threats can help your product team identify risks to expect and decide which defenses to strengthen.
Need help delivering secure AI solutions?
Turn your data into a strategic advantage with AI and ML algorithms without sacrificing cybersecurity protection. Let Apriorit experts create the exact product you envision.
What are the main types of AI data poisoning?
Globally, there are two main groups of data manipulation attacks:
- Targeted attacks aim to manipulate specific outputs, classes, or behaviors without necessarily harming overall accuracy.
- Non-targeted attacks have a goal to degrade overall model performance or reliability.
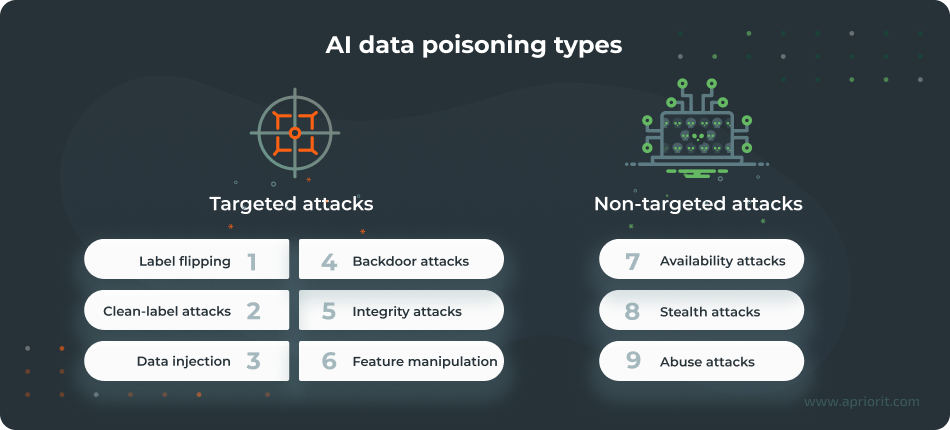
1. Label flipping. Attackers swap correct labels with incorrect ones in training datasets (for example, flipping ‘spam’ to ‘not spam’ in an email dataset). As a result, the model may misclassify information, resulting in poor performance.
2. Clean-label attacks. Poisoned data appears correctly labeled, making detection extremely difficult. Such attacks often exploit feature similarity and are common in image classification tasks. Clean-label attacks are hard to detect because the poisoned data looks legitimate to humans and filters.
For example, an attacker may subtly alter a training image but keep its original label, then insert the modified image back into the dataset. As a result, the model learns from this poisoned data, causing it to misclassify specific target images.
3. Data injection. Malicious actors insert fabricated data points into training sets to steer model behavior in a certain direction. Data injection can happen during crowdsourced data collection or open-source contributions. For example, a sentiment analysis dataset could have fake reviews injected into it, causing an LLM to start promoting competitor products or harmful content.
Research published in Nat Med shows that replacing as little as 0.001% of training tokens with medical misinformation may result in harmful models that are more likely to propagate medical errors. This discovery reveals how minor poisoning efforts can impact real‑world results, highlighting the risks of insufficient data poisoning detection.
4. Backdoor attacks. These include subtle manipulations like inaudible audio triggers, hidden image watermarks, or text phrases. LLMs function normally until a specific trigger makes a model behave in a certain way, enabling attackers to control outputs on demand. For example, a secret keyword in a prompt can make an LLM generate biased content.
In 2024–2025, security engineers documented hidden prompts in code comments that poisoned fine‑tuning datasets for Deepseek’s DeepThink-R1. Such prompts yielded backdoors activated by specific phrases, without needing internet access at inference.
5. Integrity attacks. These attacks focus on corrupting specific classes or outputs while leaving overall accuracy intact and without an obvious drop in performance. For example, an integrity attack might corrupt sentiment analysis so that positive reviews are misclassified as negative.
6. Feature manipulation. Attackers alter critical features, metadata, or key attributes in structured datasets. The goal can be to introduce bias or reduce accuracy. Example: modifying metadata in structured datasets (such as age or income fields) to affect model predictions without changing labels.
7. Availability attacks. Malicious actors inject noisy or contradictory data to degrade overall model performance. An example is adding random noise to image datasets used for classification, reducing accuracy across all predictions.
8. Stealth attacks. These rely on gradual, subtle corruption over time to evade immediate detection, leading to long-term model drift. Stealth attacks are hard to detect because changes accumulate slowly, continuously degrading LLM performance. They typically occur during continuous learning or online training phases.
A 2025 paper by Sangwon Jang, June Suk Choi, Jaehyeong Jo, Kimin Lee, and Sung Ju Hwang introduces the Silent Branding Attack that subtly embeds logos in fine‑tuning datasets, causing models to reproduce those logos in outputs without any textual trigger. This is an example of a stealthy and high‑success poisoning technique that tampers with AI output results and leads to misinformation.
9. Abuse attacks. Malicious actors inject incorrect information into legitimate online sources that AI systems use for post-deployment training. Such attacks often target online sources like Wikipedia or forums used for model updates. As a result, LLMs can propagate misinformation.
In 2025, an AI researcher claimed he had seeded custom protocols across the internet, and later tricked Qwen 2.5 into retrieving that content and outputting explicit lyrics using an 11‑word query. This case shows the possibility of attackers seeding malicious packages in a similar manner.
Related project
Developing a GDPR-Compliant AI-Powered LMS for Pharma Employee Training
Discover how we helped a global pharma company automate personalized training and boost engagement with an AI-driven LMS that scales securely and complies with the GDPR.

What are the consequences of AI data poisoning attacks?
Data poisoning in AI models may disrupt entire business operations, leading to costly consequences such as the following:
1. Degraded AI accuracy. Poisoned data affects your model’s learning process, making predictions unreliable. For example, healthcare LLMs might misclassify symptoms or manufacturing quality control systems might approve defective parts. As a result, your product might lose its market position to competitors with more accurate solutions.
2. Security incidents and compliance risks. Compromised datasets can create backdoors or trigger behaviors that expose sensitive information. Attackers may even embed malicious patterns that bypass fraud detection or authentication systems. In regulated industries like healthcare or finance, this could lead to data leaks that violate HIPAA or the GDPR, along with penalties for non-compliance.
3. Financial losses. Apart from re-engineering expenses for model retraining and validation, an organization suffering from data manipulation might also face operational downtime, which can disrupt production or service delivery. Another type of extra spending may appear from legal liabilities if customers claim harm due to faulty AI decisions.
4. Damage to reputation and trust. AI-driven decisions influence customer trust. So if your system makes incorrect, harmful, or biased recommendations because of poisoned data, you risk losing client confidence, getting negative media coverage, and dealing with long-term brand damage that impacts market share.
Data poisoning transforms physical and digital assets into attack vectors, expanding the threat landscape for AI-driven businesses across different industries. Comprehending these risks is the first step toward building resilient AI systems.
Olya Kolomoets, VP of AI Engineering and Integration at Apriorit
Unfortunately, it’s not easy to identify data poisoning in your datasets. Let’s explore the key challenges of dealing with data manipulation in the next section.
Why is it hard to mitigate AI data poisoning?
Dealing with AI data manipulation risks causes several complex challenges. Let’s look at the main difficulties your development team might face when dealing with data poisoning in AI solutions:
- Complexity of detection. Poisoned data often looks statistically similar to clean data, making it hard to spot. Attackers use subtle perturbations or hidden backdoor triggers that evade traditional validation checks. Moreover, large-scale datasets with millions of samples sourced from public repositories amplify this challenge. Even private datasets aren’t immune, as attackers can compromise storage systems or corrupt valid samples.
- Variability of LLMs. Detection and mitigation strategies differ for various AI models, so there’s no one-size-fits-all approach to spot AI data poisoning. This is why enterprises deploying multiple AI systems must tailor defenses according to each type of AI model, increasing complexity and cost.
- Addressing insider and external threats. Insider (white-box) attacks are a type of data poisoning carried out by actors with privileged access, thereby bypassing perimeter defenses. An insider threat refers to any attacker who has gained legitimate access or internal‑level knowledge of your systems, whether through employment, compromised credentials, social engineering, or other means. External (black-box) attacks are carried out by external adversaries with no inside knowledge, exploiting weak spots. Preventing and mitigating each type of threat requires your team to plan and implement different security mechanisms.
- Managing third-party data risks. Many AI systems rely on external data providers or public datasets. If these sources are compromised, poisoned data can cascade into multiple models, affecting product accuracy, data security, and brand reputation.
- Lack of in-house expertise. Effective prevention and detection require deep knowledge of both AI development and cybersecurity. Companies of all sizes might face a lack of specialized teams, leading to delayed response and higher remediation costs.
These challenges make data poisoning a high-impact risk for any organization deploying AI. To mitigate them, consider delegating technical tasks to outsourcing software development companies like Apriorit that have strong AI development and cybersecurity skills.
In the next section, we offer proven methods to help your team prevent data poisoning risks, safeguarding business continuity, compliance, and trust.
Read also
How to Build a Secure and Resilient GenAI Architecture: Key Considerations and Best Practices
Deliver generative AI systems with security in mind. Apriorit experts share practical approaches to safeguarding models, pipelines, and sensitive data.

How to prevent AI data poisoning with 7 tips from Apriorit experts
Preventing data poisoning requires a combination of technical safeguards, process discipline, and continuous monitoring.
Below, we list practical strategies that have proved efficient in Apriorit’s experience working on multiple AI-driven projects. They will help your team reduce data manipulation risks and maintain the integrity of your AI product:

1. Establish data provenance
Track the history of all training data, including metadata, logs, and digital signatures. Detailed records can help your team identify compromised inputs and accelerate recovery after an incident.
Also, retain a detailed record of all data sources, updates, modifications, and access requests. These measures won’t necessarily help you detect a data poisoning attack, but they will come in handy in case of a security incident, helping your organization recover and identify the responsible party.
Apriorit’s tip: Use data version control tools to track dataset changes and detect manipulation attempts.
2. Validate data quality
Apply strict validation checks to filter anomalies and outliers before using datasets for LLM training. Make sure your team applies proven methods like exploratory data analysis to understand the main features, patterns, anomalies, and relationships within a dataset.
Also, consider using statistical techniques like clustering methods to distinguish deviations from expected patterns, pointing out potential poisoning attempts. To streamline data quality validation, use tools like TensorFlow Data Validation, Alibi Detect, and IBM Adversarial Robustness Toolbox.
AI data poisoning risks differ significantly between public and private datasets.
Public sources are exposed to web scraping injections and upstream corruption. Apart from validating sources for training data, you should apply integrity checks and hashing to detect corruption. Also, use anomaly detection to spot injected or manipulated data during scraping.
Private datasets face insider threats and account compromises. Therefore, enforce strict access controls, multi-factor authentication, and role-based permissions, and monitor user activity for unusual patterns.
Vadim Nevidomy, Head of AI at Apriorit
3. Monitor training dynamics
Monitoring training dynamics helps teams maintain visibility into how a model learns over time. Track gradient changes, weight updates, and performance metrics during training. Subtle shifts in those metrics can indicate poisoned inputs even when accuracy looks stable.
Apriorit’s tip: Use tools like TensorBoard, MLflow, and Evidently AI that provide dashboards, making it easier to inspect gradients, activations, feature profiles, and overall training progress.
4. Secure data handling
Enforce robust access controls and apply the principle of least privilege. Make sure only authorized users with verified identities can access sensitive data. Such actions will help your team address common poisoning vectors like insider threats and compromised accounts.
Apriorit’s tip: Implement RBAC and multi-factor authentication for all data access points. Combine this with audit trails to detect insider threats early.
5. Use adversarial training
Proactively safeguard your AI product by using advanced ML models that can learn to recognize patterns associated with poisoned data. Then introduce adversarial examples during training to teach those models to classify misleading inputs and resist manipulation. This proactive defense can help your team reduce vulnerability to backdoor and integrity attacks.
Apriorit’s tip: Start by introducing low-complexity adversarial examples like simple perturbations before scaling to more sophisticated attacks, such as gradient-based or generative adversarial. This approach helps your team validate model resilience without overwhelming resources.
6. Run red-team simulations
Test your defenses under realistic attack scenarios. For example, seed poisoned subsets and measure detection latency, or attempt label flipping and backdoor triggers in controlled sandboxes. Analyze attack simulation results and tune your AI model accordingly, teaching it to flag data poisoning attempts.
Such an approach requires additional effort from your team, but it can help you identify gaps and tune thresholds for maximum risk reduction.
Apriorit’s tip: Document every simulation outcome and feed insights back into your data pipeline. Use these findings to refine preprocessing steps, adjust anomaly detection thresholds, and update model retraining schedules. Treat red-team exercises as a continuous feedback loop, not a one-off event.
7. Establish post-deployment monitoring
As we’ve mentioned, even a well-trained LLM can be poisoned during post-release training. Make sure your team sets monitoring to detect sudden performance degradation, increased false positives/negatives, unintended outputs, and biased results.
Apriorit’s tip: Use drift detectors (tools or custom scripts) to establish continuous monitoring. This will help your team detect sudden accuracy drops and backdoor activation. Helpful tools for drift monitoring are Evidently AI, Alibi Detect, WhyLabs, and Fiddler AI. Also, establish sufficient infrastructure controls to prevent the model from accessing unintended data sources.
Read also
Building a Secure AI Chatbot: Risk Mitigation and Best Practices
Improve chatbot reliability and protection. Discover key security practices to reduce vulnerabilities and support compliant AI interactions.

Prevent data poisoning in your product with Apriorit’s expertise
Here’s how Apriorit will help you prevent data manipulation attacks during project development, testing, and maintenance:
- We start looking for signs of data poisoning during data collection and validation.
- During training, we monitor how chosen datasets impact our model behavior.
- At the testing phase, we can also conduct penetration testing, looking for backdoors that could have been either introduced by malicious actors or caused by poor-quality data.
- After production, we use different monitoring tools to spot incorrect behavior.
Additional security efforts like penetration testing and security audits are especially important for products running on LLMs, as an LLM can access files on a computer and other resources like emails and web pages that could be poisoned.
Partner with Apriorit for professional, scrupulous, and secure AI development. Here’s what our engineers can do for you:
- Custom dataset preparation and sanitization. Our engineers create and validate custom datasets, cleansing them of potentially harmful injections and ensuring data integrity before training begins.
- Secure MLOps implementation. We set up secure deployment and training pipelines, including data version control. Our developers also automate model drift monitoring and establish real-time anomaly detection.
- Adversarial training and robustness testing. We enhance the resilience of your AI models by training them on adversarial examples and conducting stress tests to uncover vulnerabilities to manipulation.
- Training infrastructure protection. To prevent unauthorized insider and malicious interference, Apriorit engineers audit and configure strict access controls for development environments and training data.
Apriorit offers a wide range of AI services, from AI consulting and model fine-tuning to full-scale GenAI development and maintenance. We’re ready to assist you with AI projects of any complexity and to reliably detect AI training data poisoning attempts.
With 20+ years of experience in cybersecurity development and a focus on following a secure SDLC, our engineers will help you create a truly protected solution.
Want to enhance your AI project’s protection?
Delegate technical tasks to Apriorit engineers, leveraging our expertise in AI development and cybersecurity. Let’s create a resilient and efficient solution that’s tailored to your business goals and requirements.
FAQ
What is AI poisoning?
AI poisoning, or data poisoning, is a cyber attack in which adversaries manipulate training datasets to degrade model performance or embed hidden vulnerabilities.
How does AI poisoning work?
<p>AI poisoning works by tampering with datasets used to train or fine-tune an AI model. This can happen through various attack types including label flipping, data injection, and backdoor attacks.</p>
<p>Attackers often exploit open datasets, crowdsourced data, or insecure data pipelines to introduce poisoned samples without detection. As a result, an AI solution can show poor performance and reduced accuracy, and it can provide incorrect or harmful outputs.</p>
What can happen after AI poisoning?
<p>Once AI training data manipulation techniques have been used, your product can suffer from consequences such as:</p>
<ul class=apriorit-list-markers-green>
<li>Reduced accuracy, as an AI model can start producing inaccurate predictions or classifications</li>
<li>Security vulnerabilities if attackers manage to trigger specific behaviors using crafted inputs</li>
<li>Biased or unethical output if poisoned data has introduced or worsened bias in decision-making</li>
<li>Operational risks, especially in critical industries like finance, healthcare, and automotive where poisoned models might propagate misinformation, leading to severe financial or safety incidents</li>
</ul>
How can I defend against AI poisoning?
<p>To prevent data poisoning, use proven methods like:</p>
<ul class=apriorit-list-markers-green>
<li>Data validation. Implement strict checks for data integrity and source reliability.</li>
<li>Robust training techniques. Use algorithms that are resistant to outliers and adversarial samples.</li>
<li>Continuous monitoring. Track model performance for anomalies and model drift.</li>
<li>Secure data handling. Protect data collection and storage from unauthorized access.</li>
<li>Differential privacy and sanitization. Reduce the impact of malicious samples by cleaning and anonymizing data.</li>
</ul>
What is the difference between data poisoning and prompt injection?
<p>These two types of attacks target different stages of the AI lifecycle:</p>
<ul class=apriorit-list-markers-green>
<li>Data poisoning targets LLMs and other AI models by corrupting datasets, affecting long-term behavior.
<li>Prompt injection targets inference time in large language models (LLMs) by manipulating user inputs or instructions to override intended behavior.</li>
</ul>


