 Skip to main content
Skip to main content
Developing a complex software solution is like doing a puzzle. And the database is an extremely important piece in that puzzle. Databases play a critical role in software development, allowing IT products to efficiently work with large amounts of data.
Сhoosing the right type of database for your project and the most fitting library to manage it can be challenging.
In this article, we explore the differences between relational and non-relational databases, overview Python libraries for working with databases, and compare their performance. In the end, we share guidelines on how to choose the most relevant type of database and Python library for your project.
This article will be helpful for project leaders who work on Python-based solutions and want to gain insights on choosing the right technology stack for product development.
Contents:
- Using Python libraries for database management
- What are relational databases?
- Python libraries for managing relational databases
- What are non-relational databases?
- Python libraries for managing non-relational databases
- Performance comparison of reviewed Python libraries
- How to choose a database and a Python database library for your project
- Conclusion
Using Python libraries for database management
Software solutions require databases to manage the huge amounts of data they generate and collect. A well-structured database makes it easier to ensure that data is accurate, reliable, and quickly accessible to end users. Developers need databases to optimize data retrieval and storage to improve application speed and performance.
Here’s what databases do:
- Help developers store, organize, and manage large volumes of data
- Provide for effective searching, processing, and manipulation of data
- Allow multiple applications to access the same data at the same time
- Provide mechanisms for data protection, such as user authentication, encryption, and access controls
- Allow for easily backing up and restoring data and provide ways to recover data in case of system failure
However, to efficiently configure and manage a database, you also need to choose a suitable database management library.
Python is a popular programming language for working with databases, providing several libraries that simplify the process. Python applications that use a database for persistent storage must perform three distinct tasks:
- Establish a connection to a database or database server
- Process transactions
- Terminate the connection when it’s no longer needed
You can ensure database management using Python libraries, as they provide a convenient way to connect to databases, execute SQL queries, and process query results.
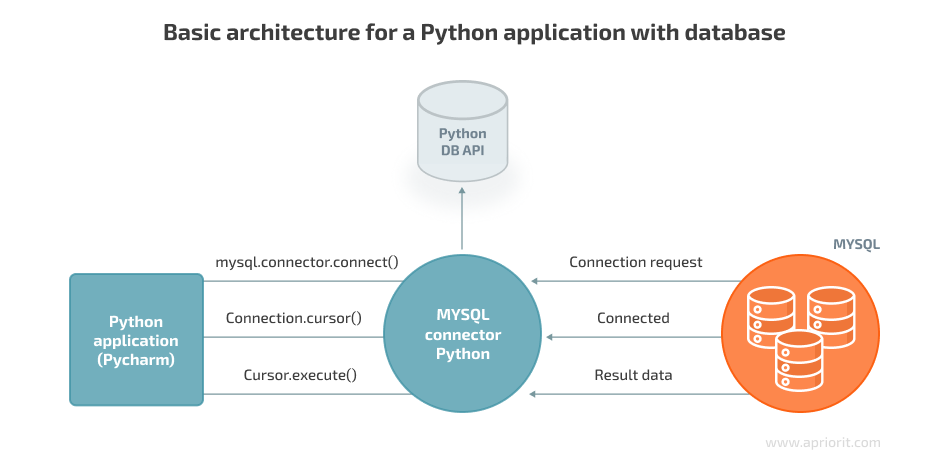
Libraries like SQLAlchemy, Psycopg2, MySQLdb, and SQLite3 provide efficient ways to connect to a database, create tables, insert and retrieve data, and perform other database operations. Let’s explore a few more advantages of using Python libraries for database management:
- Python libraries offer cross-platform support, which means you can use the same library for different databases on different operating systems.
- You can easily integrate Python database libraries with other Python libraries and frameworks such as Flask, Django, and Pyramid, making the process of building web applications and other database software more convenient.
- Python libraries are designed to be fast and efficient, enabling you to work with large datasets without experiencing performance issues.
Using database libraries is a common and efficient way to work with data in Python. However, in some situations, it may be appropriate to use other approaches or tools for working with databases due to a few potential disadvantages of Python libraries:
- If you’re working with large amounts of data in a highly loaded environment, Python database libraries can lead to slow performance and inefficient resource use.
- Python libraries are not as fast as others written in low-level languages like C or C++. If you’re working with large datasets or systems with many transactions, you may experience slower performance.
- Some databases have features that are not fully supported by Python libraries, meaning that you might need to write custom code to use those features. For example, PostgreSQL provides a robust full-text search engine that allows for efficient searching and indexing of text data. Psycopg2 and SQLAlchemy provide support for full-text search in PostgreSQL, but some advanced features such as phrase search and proximity search are not fully supported. Also, MySQL provides a variety of built-in functions for working with JSON data that allow you to extract, manipulate, and aggregate JSON data in SQL queries. But these features are not fully supported by PyMySQL and SQLAlchemy.
Now, let’s explore types of databases in detail, compare relational vs non-relational databases, and list the most popular Python libraries for database management.
Planning a Python-powered project?
Make sure to deliver efficient and thoughtfully designed software by leveraging the expertise of Apriorit’s experienced developers.
What are relational databases?
A relational database (RDB) is based on the relational model of data, an approach to managing data using a structure and language consistent with first-order predicate logic.
A relational database is defined as follows in the Google Cloud documentation:
“A relational database is a collection of information that organizes data in predefined relationships where data is stored in one or more tables (or ‘relations’) of columns and rows, making it easy to see and understand how different data structures relate to each other. Relationships are a logical connection between different tables, established on the basis of interaction among these tables.”
The structure of a relational database allows you to link information from different tables using foreign keys (or indexes). These keys help you identify any unique piece of data in a table. For example, a foreign key can link a column in table A to a column in table B and can ensure that a value can be added to the column in table A only if the same value already exists in the linked column in table B.
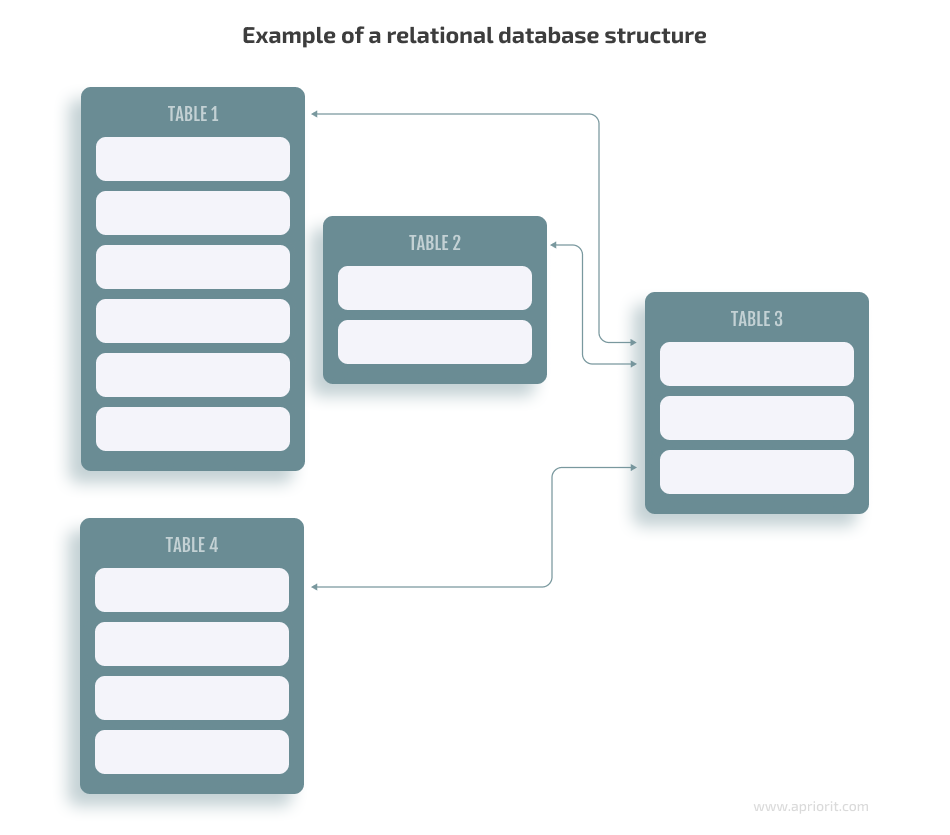
To maintain an RDB, you need to use a relational database management system (RDBMS), which can also be called a database engine or simply a database library.
Python libraries for managing relational databases
Python offers several libraries that make it easy to interact with different relational databases. Let’s explore the five most popular:
1. SQLite
SQLite is a C library that provides a lightweight disk-based database that doesn’t require a separate server process and allows for accessing the database with a nonstandard variant of the SQL query language. It’s a self-contained, serverless, zero-configuration, and transactional SQL database engine.
The SQLite library is an extremely helpful tool for Python developers. They can use it to query data, update records, and leverage other advanced SQL features.
Although the SQLite Python library is well suited for working with local databases, it may not be suitable for:
- Large-scale applications
- Client–server applications
- Heavy write-intensive applications
Also, SQLite may not be the best choice for applications that require high concurrency, such as those that have many users accessing and modifying the database at the same time. While SQLite supports multiple concurrent connections, it doesn’t handle concurrent writes as well as other databases.
To use the SQLite database with Python, you need to import the SQLite3 module, which provides a simple and efficient API for working with SQLite databases. You can create, connect, and manipulate SQLite databases using the sqlite3.connect(), cursor(), execute(), and fetchall() functions.
Here is an example of how to use the SQLite library in Python by establishing a connection with the database, creating tables, adding data, and committing changes:
import sqlite3
# Create a connection to the database
conn = sqlite3.connect('test.db')
# Create a cursor object
cur = conn.cursor()
# Create a table
cur.execute('''CREATE TABLE users
(id INTEGER NOT NULL PRIMARY KEY, name TEXT, email TEXT)''')
# Insert some data
cur.execute("INSERT INTO users VALUES ( 'Bob', ’[email protected]’)")
# Commit changes
conn.commit()
# Execute a SQL query
cur.execute('''SELECT * from users''')
result = cur.fetchall()
# Close the connection
conn.close()Read also
Choosing an Effective Python Dependency Management Tool for Flask Microservices: Poetry vs Pip
Empower your microservices architecture with only the most suitable Python tools. Discover how to choose the best for your product.

2. Psycopg2
Psycopg2 is an open-source library that allows Python programs to interact with PostgreSQL databases. It provides a set of functions and classes for working with database connections, executing SQL statements, and handling database errors.
It’s worth using the Psycopg2 library because it:
- Provides access to the full range of PostgreSQL database features, including advanced data types, stored procedures, and triggers
- Allows for connection pooling, which can improve performance by efficiently managing multiple database connections
- Supports asynchronous database access using Python’s asyncio module
However, Psycopg2 has some downsides as well. For instance, this library:
- Adds overhead to database interactions, which can impact performance in some cases
- Isn’t suitable for projects that need to work with other databases, as Psycopg2 is a PostgreSQL-specific adapter
Let’s explore a few examples of how you can use Psycopg2 to manage RDBs in Python solutions. This code shows you how to install Psycopg2, create tables in it, make changes to tables, insert data, and query the database:
pip install psycopg2
import psycopg2
# Connect to a PostgreSQL database
conn = psycopg2.connect(
dbname="database",
user="username",
password="password",
host="localhost",
port="5432"
)
# Create cursor object to execute database commands and queries
cur = conn.cursor()
# Create a table
cur.execute("""
CREATE TABLE users (
id serial PRIMARY KEY,
name varchar(50),
email varchar(50),
)
""")
# Make changes to the database
conn.commit()
# Insert data into a table
cur.execute("INSERT INTO users (name, email) VALUES (%s, %s) ",
(“Bob”, "[email protected]"))
# Query the database for all users
cur.execute("SELECT * FROM users")
rows = cur.fetchall()
# Close communication with the database
cur.close()
conn.close()3. Cx_Oracle
Cx_Oracle is a popular open-source Python module that you can use to connect to Oracle databases. It conforms to the Python database API 2.0 specification while offering lots of additions and a couple exclusions.
The major advantage of cx_Oracle is that it’s highly optimized for Oracle databases, delivering high performance while working with large volumes of data.
On the downside, this library is only compatible with specific versions of Python (at the moment of writing, Python 3.6 and higher), and the use of cx_Oracle requires an Oracle Database license, which can be costly.
Let’s see how to install cx_Oracle and then explore a few actions you can do to tables and data with its help:
pip install cx-Oracle
import cx_Oracle
# Connect to Oracle database
conn = cx_Oracle.connect('username/password@hostname:port_number/db_name')
# Create a cursor object
cur = conn.cursor()
# Create a table
cur.execute('''CREATE TABLE
Users(id number(10), name varchar2(20), email varchar2(30))''')
# Insert a new row into the user’s table
cur.execute("INSERT INTO users (name, email) VALUES (:1, :2)", (‘Bob’, ‘bob@mail.com’))
# Execute a SQL query
cur.execute('SELECT * FROM users')
# Fetch all rows
rows = cur.fetchall()
# Close the cursor and connection
cursor.close()
connection.close() Related project
Building an AI-based Healthcare Solution
Unveil a success story of leveraging Python for building an AI-based healthcare system. Find out how the delivered solution helped our client achieve 90% precision and a 97% recall rate when detecting and measuring follicles. Such an efficient processing of ultrasound videos saves doctors’ time, allowing them to quickly analyze video files and easily re-check the system’s results if needed.

4. PyMySQL
PyMySQL is a pure-Python MySQL client library that creates an API interface to access MySQL relational databases. This library serves as a handy interface to interact directly with MySQL databases by incorporating SQL statements within the confines of Python scripts. It’s widely used in many Python-based web applications and data-driven projects.
Main benefits of PyMySQL:
- Being implemented in Python, PyMySQL doesn’t require any external dependencies or installation of additional software.
- With PyMySQL, you can perform various database operations, such as creating tables, inserting data, updating data, deleting data, and executing SQL queries.
- PyMySQL supports transactions and provides functionality for handling errors and exceptions.
However, PyMySQL also has some downsides:
- PyMySQL is designed specifically for MySQL databases and may not work with other database systems.
- It doesn’t support low-level APIs that MySQL provides, such as store_result, use_result, and data_seek.
- Since PyMySQL is written in pure Python, it can be slower than C-based libraries.
You can install PyMySQL using pip, the Python package manager:
pip install pymysqlLet’s explore some examples of how to use PyMySQL in Python for database management: to connect to databases, create tables, and execute queries.
import pymysql
# Connect to the database
conn= pymysql.connect(
host='localhost',
port=3306,
user='root',
password='password',
database='database'
)
# Create a cursor object
cur = conn.cursor()
# Create a table
cur.execute('''
CREATE TABLE users (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
email VARCHAR(100) NOT NULL,
PRIMARY KEY (id)
)
''')
# Commit the transaction
conn.commit()
# Execute the query to insert data
cur.execute('''
INSERT INTO users (name, email) VALUES
('Elon', '[email protected]'),
('Bob', '[email protected]')
''')
conn.commit()
# Execute the query to select data
cur.execute('SELECT * FROM users')
# Fetch the results
rows = cur.fetchall()
# Close the cursor and connection when finished
cur.close()
conn.close() 5. SQLAlchemy
SQLAlchemy is a Python library that provides two primary approaches to working with relational databases: SQLAlchemy Core and SQLAlchemy object-relational mapping (ORM).
SQLAlchemy Core provides a low-level API for interacting with databases, allowing you to build and execute SQL statements directly.
SQLAlchemy ORM offers a higher-level API that allows you to work with database tables and rows as Python objects. The ORM automates many of the details of database interactions, including generating SQL statements, managing transactions, and mapping between Python objects and database rows.
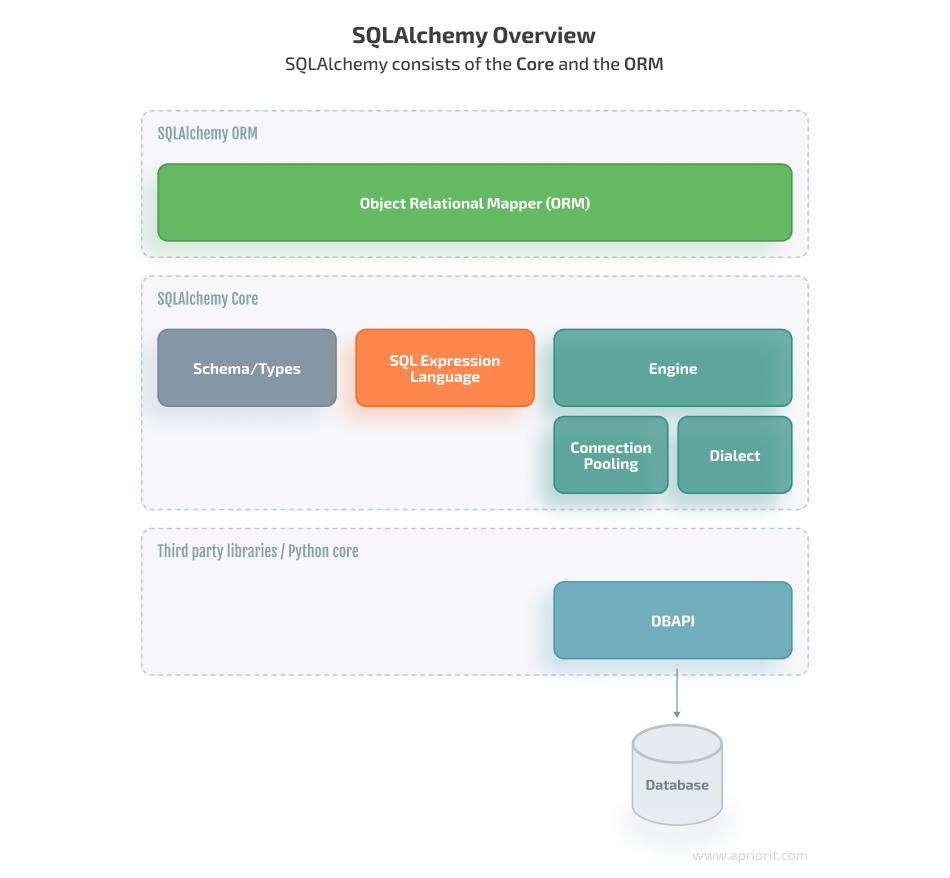
Both Core and ORM are powerful tools for working with databases, and the choice between them depends on your specific needs and preferences:
- Core is more suitable for advanced users who require full control over database interactions.
- ORM is more suitable for users who prefer interacting with the database via Python objects and classes.
Overall, SQLAlchemy is a helpful tool for Python developers, as it:
- Provides advanced querying capabilities such as filtering, ordering, grouping, and joining data from multiple tables
- Offers transaction management features which allow SQLAlchemy to perform multiple operations on a database as a single transaction
- Supports a variety of SQL databases, including PostgreSQL, MySQL, SQLite, Oracle, and Microsoft SQL Server
Major disadvantages of this library are the following:
- While SQLAlchemy is considered fast, in some cases, it can be slower than raw SQL because the ORM layer can add additional overhead to queries.
- SQLAlchemy can use a lot of memory, especially when working with large datasets. The ORM layer may create a large number of objects in memory, which might slow down your application and use up system resources.
- Debugging SQL queries generated by SQLAlchemy can be more challenging than debugging raw SQL queries.
To install SQLAlchemy, you can simply use pip:
pip install sqlalchemyNow, let’s explore examples of how you can manage databases using SQLAlchemy in Python. Here are examples of working with SQLAlchemy Core and SQLAlchemy ORM:
1. SQLAlchemy Core
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData
# Create an engine to connect to the database
engine = create_engine(‘dialect[+driver]://user:password@host/dbname’)
# Define metadata for the database schema
metadata_obj = db.MetaData()
# Define a table to store information about users
users = Table(
'users',
metadata_obj,
Column(‘id', Integer, primary_key=True),
Column('name', String),
Column('email', String),
)
# Create the table in the database
metadata.create_all(engine)
# Insert some data into the table
connection = engine.connect()
connection.execute(users.insert(), [
{'name': ‘Bob', 'email': ‘[email protected]},
{'name': ‘Elon', 'email': ‘[email protected]},
])
# Query the database to retrieve the inserted data
result = connection.execute(users.select()) 2. SQLAlchemy ORM
from sqlalchemy import create_engine, Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import sessionmaker
# Create a database engine
Engine = create_engine(‘dialect[+driver]://user:password@host/dbname’)
# Create a session factory
Session = sessionmaker(bind=engine)
# Create a base class for declarative models
Base = declarative_base()
# Define a model
class User(Base):
__tablename__ = 'users'
id = Column(Integer, primary_key=True)
name = Column(String)
email = Column(Integer)
def __repr__(self):
return f"<User(name='{self.name}', email={self.email})>"
# Create a table in the database
Base.metadata.create_all(engine)
# Create a new user
new_user = User(name='Bob', email=’bob@mail.com’)
# Add the user to the database
session = Session()
session.add(new_user)
session.commit()
# Query the database for all users
users = session.query(User).all()Now, let’s discuss what non-relational databases are and which Python tools you can use to manage them.
Read also
Python for Building FinTech Solutions: Benefits, Tools, and Use Cases
Discover how Python can help you build secure and reliable financial technology software. Apriorit experts explain the core tasks such a solution should handle, libraries and frameworks to use, and aspects to take into account when developing a Python solution for FinTech.

What are non-relational databases?
Non-relational, or NoSQL, databases enable the storage and querying of data outside the traditional structures found in relational databases.
Non-relational databases have no rows, tables, primary keys, or foreign keys. Instead, they use a storage model optimized for requirements specific to the type of data being stored. That’s why you can encounter several types of NoSQL databases, with the most popular being document-oriented, key-value, wide-column, and graph databases.
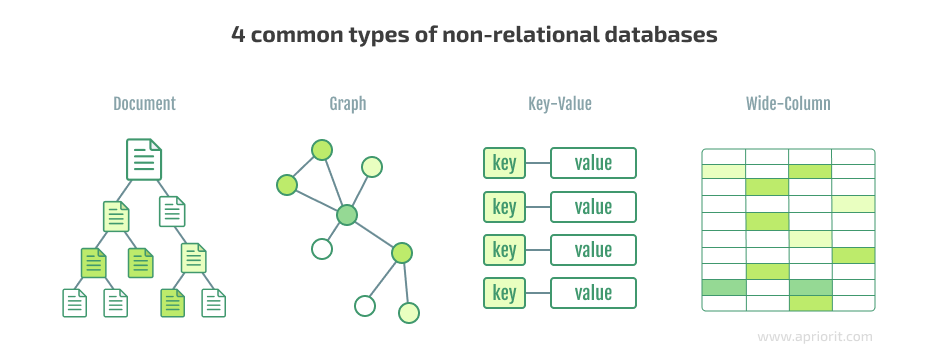
One of the biggest advantages of non-relational databases is their flexibility. Unlike their relational counterparts, which are rigidly structured and require a predefined schema, non-relational databases are schemaless. This means that data can be stored in a more natural, unstructured way, making it easier to manage large amounts of data.
Additionally, non-relational databases are designed to be highly scalable, making it easy to add more nodes to a growing database. This allows for better performance, faster data access, and more convenient database management.
Python libraries for managing non-relational databases
Let’s discuss several Python libraries that are commonly used for managing non-relational databases:

1. PyMongo
PyMongo is a Python library for working with MongoDB.
MongoDB is a popular document-oriented database that stores data in collections analogous to tables in a relational database. Each collection contains a set of documents, which is the fundamental unit of data in MongoDB. These documents are similar to JavaScript Object Notation (JSON) and can have different fields and data types, making MongoDB a good choice for handling unstructured data.
PyMongo offers lots of advantages, including:
- Easy integration in your Python application
- A simple yet powerful interface for querying and manipulating data
- Support for all MongoDB features, including sharding, replication, and indexing
- Ease of learning and extensive documentation, making it a great choice if your team includes junior developers
However, PyMongo also has some disadvantages, including the following:
- No built-in ORM system, which can make it hard to work with complex data models
- Can be slower than other MongoDB Python libraries due to its design, which is focused on flexibility and ease of use rather than performance
To use PyMongo, you first need to install it using pip:
pip install pymongoLet’s also explore a simple example of how you can use PyMongo to create databases and interact with documents:
import pymongo
# Create a client, database, and collection instances
client = pymongo.MongoClient('mongodb://localhost:27017/')
db = client['my_database']
collection = db['my_collection']
# Insert a document
document = {'name': Bob, 'email': ‘bob@mail.com’}
result = collection.insert_one(document)
# Find a document
query = {'name': 'Bob'}
result = collection.find_one(query)
# Update a document
query = {'name': ‘Bob’}
new_values = {'$set': {'email': ‘bob_new@mail.com’}}
result = collection.update_one(query, new_values)2. Cassandra Driver
Cassandra Driver is a Python library for working with Apache Cassandra, which is a highly scalable and distributed NoSQL database management system designed to handle large amounts of data across multiple servers. Apache Cassandra uses a partitioning scheme to divide data into partitions, or shards, which are then replicated across multiple nodes in the cluster. This allows for high availability and fault tolerance in case of node failures or network issues.
Cassandra Driver is a popular choice for interacting with Apache Cassandra databases, as it:
- Provides a high-level interface for interacting with Apache Cassandra
- Supports all Apache Cassandra features, including flexible data modeling, automatic partitioning, and tunable consistency
- Includes an object mapper that allows you to map Apache Cassandra tables to Python classes, which can make it easier to work with data in an object-oriented manner
- Allows for asynchronous operations, making it easy to run queries in parallel (which can be especially useful when working with large datasets and high-throughput applications)
The two major disadvantages of Cassandra Driver are:
- It’s designed specifically for Apache Cassandra databases and won’t work with other systems.
- Cassandra Driver can be difficult to learn and use, particularly for those who are new to this tool.
To install the library, run the following command in your terminal:
pip install cassandra-driverHere’s an example of how to use Cassandra to create instances, elements, and tables, and to insert rows:
from cassandra.cluster import Cluster
# Create a session instance
cluster = Cluster(['127.0.0.1'])
session = cluster.connect()
# Create a keyspace
session.execute("CREATE KEYSPACE mykeyspace WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'}")
# Create a table
session.execute("CREATE TABLE mykeyspace.mytable (id int PRIMARY KEY, name text, age int)")
# Insert a row
session.execute("INSERT INTO mykeyspace.mytable (id, name, age) VALUES (1, 'John', 30)")3. Redis-py
Redis-py, or Redis Python client, is an interface for the Redis database that allows Python applications to access and manipulate data stored in Redis. The client provides a Pythonic interface for performing Redis operations and supports advanced features like pipelining, transactions, and scripting.
Redis is an in-memory key–value data storage that can be used as a database, cache, and message broker. It provides high performance, scalability, and availability, making it a popular choice for building fast and scalable applications. Redis supports a variety of data structures, including strings, lists, sets, and hashes.
Some of the key advantages of Redis-py include the following:
- Maintains a pool of connections to Redis, making it easy to reuse connections across multiple threads or processes
- Automatically reconnects to Redis in the event of a network error or server failure
- Provides support for Redis transactions, allowing multiple commands to be executed atomically
However, Redis-py also has a few potential downsides that you should be aware of:
- Doesn’t provide built-in support for asynchronous programming models like asyncio, which can limit its usability in certain types of applications
- Doesn’t provide built-in support for sharding or clustering, although Redis itself is highly scalable and can be used in distributed systems
To install the Redis Python client, use pip:
pip install redisAnd here’s a code example that shows basic Redis data structures and operations:
import redis
# Create a Redis client object
r = redis.Redis(host='localhost', port=6379, db=0)
# Set a key–value pair
r.set('name', 'Bob')
r.set('email', '[email protected]')
# Retrieve the value of the key
value = r.get('name')
print(value) # Output: b'Bob'
# Add an item to a set
r.sadd('users', 'Bob')
r.sadd('users', '[email protected]')
# Retrieve the members of the set
users = r.smembers('users')
print(users) # Output: {b'Bob', b'[email protected]'}
# Create a list
r.lpush('users', 'Bob')
r.lpush('users', '[email protected]')
# Retrieve the list
users = r.lrange('users', 0, -1)
print(mylist) # Output: [b'[email protected]', b’Bob']
# Create a hash
r.hset('users', name', 'Bob')
r.hset('users', 'email', '[email protected]')
# Retrieve the hash
users = r.hgetall('users')
print(users) # Output: {b'name': b'Bob', b'email': b'[email protected]'}Related project
Developing Software for a Drone Battery Charging and Data Management Unit
Explore the successful story of using Python together with other advanced technologies to develop an MVP of the drone battery recharging kit. Find out how we helped our client create embedded software for the single-board computer, an iOS application, and cloud infrastructure to support the system.
Performance comparison of reviewed Python libraries
Above, we explored how to arrange database management with Python engines. We looked at five libraries for working with relational databases and three more for non-relational databases, paying attention to ease of use and the features they provide. Now, we will compare some metrics to check the performance of each library.
We’ll perform a simple test that involves inserting 100,000 records into a database using each library. Meanwhile, we’ll measure the time it takes to insert the records and compare the results.
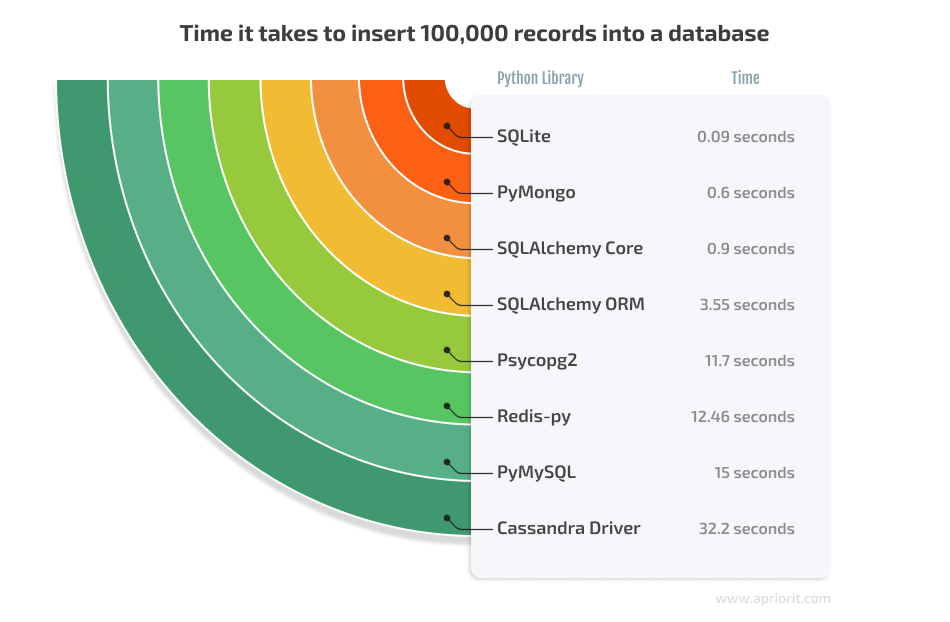
As we can see, SQLite was the fastest library, taking only 0.09 seconds to insert 100,000 records. PyMongo was the second fastest, taking 0.6 seconds, while Cassandra Driver was the slowest, taking 32.2 seconds.
It’s important to note that the results of this test may not be representative of every use case. However, this test provides a simple comparison of the performance of each library for a basic insert operation.
Note: The performance of each library may depend on the complexity of the query, the size of the database, and the hardware on which it is used.
How to choose a database and a Python database library for your project
Relational and non-relational databases have different strengths and weaknesses and are suited for different use cases. When considering which type to choose, you need to keep in mind lots of nuances and the specifics of the data you’re working with.
Below, we share some general guidelines from our experience working on dozens of projects at Apriroit:
| Use a relational database if: | Use a non-relational database if: |
|---|---|
| – You have structured data with clearly defined relationships between different data points and you need to enforce the consistency and accuracy of that data. – You have a well-defined database schema that doesn’t change frequently. – Data is easily searchable and can be retrieved quickly. – You need to perform complex queries that require joining multiple tables. – You need to handle a large number of concurrent users accessing the same data. – Your application requires ACID transactions to ensure data consistency and reliability. | – You have unstructured or semi-structured data that doesn’t fit a schema. – You need to store and retrieve large volumes of data quickly. – Your application requires high availability even if some servers go down. – You need to be able to change the database schema frequently without affecting existing data. – You need to handle semi-structured or unstructured data formats like JSON, XML, or binary data. |
When choosing a Python library for database interaction, it’s vital to consider the specific requirements of the project and the features and capabilities provided by each library.
- SQLite is well-suited for small-scale projects and applications that require a lightweight, embedded database engine. It’s a good choice for mobile and desktop applications as well as for small web applications that don’t require the scalability or performance of larger databases.
- SQLAlchemy is a good choice for large-scale web applications that require complex queries and data modeling.
- Psycopg2 fits web applications that require high performance and scalability as well as applications that need to support complex data types.
- PyMySQL suits applications that need to interact with MySQL databases and don’t require the advanced features provided by other databases.
- Cx_Oracle is a good choice for applications that require high performance and scalability for working with Oracle databases.
- PyMongo provides a simple interface for interacting with MongoDB databases. It’s a nice choice for applications that need to store and query large amounts of unstructured data.
- Redis-py is an in-memory data store that provides a key–value interface for storing and retrieving data. It’s a good choice for applications that require high performance and low latency, such as real-time analytics or caching.
- Cassandra Driver works best for applications that require high availability, scalability, and performance for handling large amounts of data across multiple data centers.
When making the final decision about tools for your project, consider the features, performance, and ease of use of each library. It’s also important to examine the availability of documentation, community support, and security when selecting a database library. By choosing the right database library, you can improve the performance, scalability, and reliability of your application.
Conclusion
Understanding which data types your solution will work with is the first step towards choosing the right type of database and the database itself. However, the challenges don’t stop here. To efficiently manage your database and make sure your future product performs flawlessly, you also need to pick the right database management library.
Python offers lots of libraries that make it convenient to work with relational and non-relational databases. Understanding the specifics of database management systems and the nuances of ensuring efficient database management with Python libraries will help you choose the most suitable option and enhance your project’s technology stack.
At Apriorit, we have professional teams of Python experts with vast experience in software development. Our specialists will help you choose technologies tailored to the specifics of your project and deliver a competitive product.
Want to build solid software?
Entrust your Python-based development to Apriorit’s engineers and enjoy a smooth and transparent delivery process of desired solution within established timeline.
Have a question?
Ask our expert!
Program Manager


