 Skip to main content
Skip to main content

Moving object detection is an essential component for various applications of computer vision and image processing: pedestrian detection, traffic monitoring, security surveillance, etc. Though the latest moving object detection methods provide promising results, accurate detection is still tricky because of various challenges like illumination issues, occlusion, and background objects in an uncontrolled environment.
In this article, we discuss the most common challenges of accurately detecting moving objects, give an overview of existing methods for detecting moving objects, and explain how your solution can be improved by applying deep learning.
Contents:
Moving objects that should be detected in a video can be people, animals, or vehicles including cars, trucks, airplanes, and ships. Most of these objects are rigid: their shape doesn’t change. However, there are also non-rigid objects, or objects that can change shape. People and animals constantly change their silhouettes when doing actions and adopting poses. Other objects like waterfalls, hurricanes, clouds, and swaying trees also move, but they should be considered by a detection algorithm as a part of the background.
A video consists of consecutive frames, and there are image processing techniques for detecting an object in each frame and then establishing relationships between pixels in different frames to detect objects that move. This type of video analysis includes the following four steps:
- Feature point classification
- Moving object detection
- Moving object tracking
- Moving object analysis
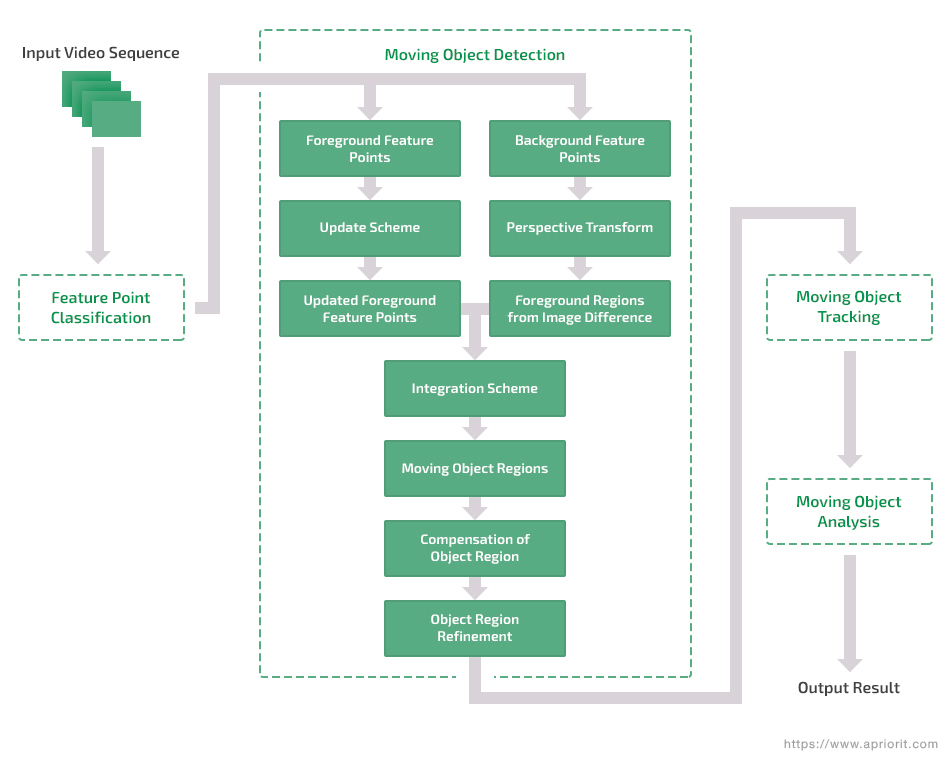
Figure 1. The video analysis process
In this article, we’ll consider only what methods are applied for moving object detection in a video image.
Use the power of deep learning!
Improve your project efficiency and product competitiveness by ensuring top-notch work of your AI-based video classification functionality with the help of Apriorit’s developers.
Methods for detecting moving objects
The first steps in video analysis are detecting target objects and clustering their pixels. In this section, we’ll consider the following approaches to detecting moving objects:
- Background subtraction
- Temporal differencing
- Frame differencing
- Optical flow
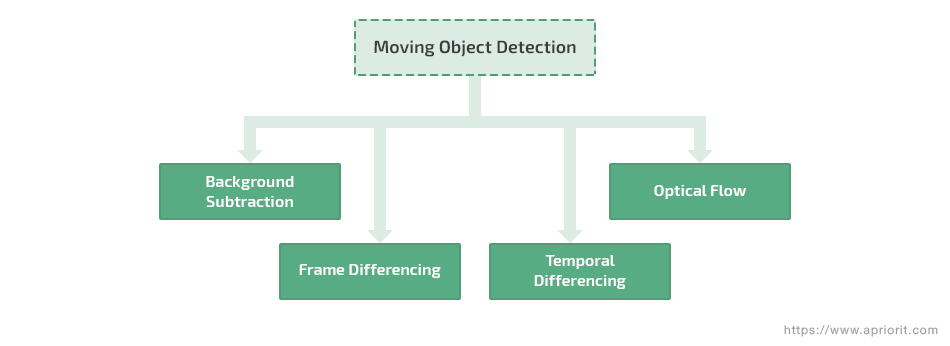
Figure 2. Traditional approaches to moving object detection
1. Background subtraction and modeling
Background subtraction, also known as foreground detection, is a frequently used method for segmenting motion in static scenes. By using mathematical modelling or probability theory, moving foreground objects are subtracted pixel by pixel from a static background image. The background image, or model, is created by averaging images over time, and the extracted foreground can be used for object recognition. Below, you can see what techniques are applied to a video frame during background subtraction:
Figure 3. General concept of background subtraction
Imagine you have a room full of people in a video, and after implementing background subtraction, you’re left with only people. Now you can work just with the people, which significantly simplifies further object detection.
Though this method provides a good silhouette of objects, it’s based on a static background, so any changes in the image will be marked as foreground. In addition, the background model should be updated over time to adapt to dynamic scene changes. Several algorithms have been introduced to handle these challenges, including Mixture of Gaussians (MOG) and foreground segmentation, adaptive MOG, and a double Gaussian model.
Background subtraction algorithms for moving cameras can be divided into two categories:
- Point trajectory-based methods track points to extract trajectories and cluster them according to motion similarity. These types of methods include approaches like trajectory classification.
- Spatio-temporal segmentation methods extend image segmentation to the spatial-temporal domain, where the spatial aspect determines semantic similarity over image space and the temporal aspect associates the motion of object pixels over time. This means that we should consider the spatio-temporal relationships of pixels to detect a moving object. However, many methods consider only the temporal aspect to detect moving objects.
Trajectory classification
Trajectory classification is a moving object detection method for moving cameras. This method includes such stages as choosing specific points in the first video frame and then obtaining a trajectory that represents continuous displacements at each point in adjacent frames.
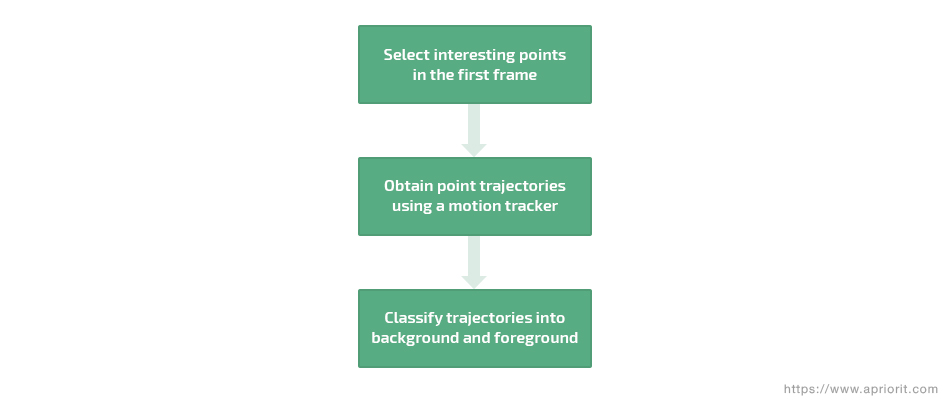
Figure 4. General concept of a trajectory classification technique
In the end, a clustering approach is applied to classify the trajectories into background and foreground regions where moving objects can be detected.
However, a clustering approach faces difficulties in addressing points near the intersection of two subspaces. That’s why region segmentation is applied for labeling regions with points that belong to neither the foreground nor the background by comparing the region trajectories with the point trajectories. However, the watershed algorithm used for saving the boundary fragments often leads to deformation of an object’s shape and contour. Thus, point trajectory is not free from inaccurate trajectory classification or edge-preserving performance of moving objects.
Read also
How to Use Google Colaboratory for Video Processing
Find out how your team can leverage Google Colab to efficiently process and analyze video without the need for high-end hardware.

2. Temporal and spatial differencing
Temporal differencing is one of the most popular approaches for detecting moving objects in video captured with a moving camera. In contrast to detecting moving objects in video captured by a stable camera, there’s no need to build a background model in advance, as the background is changing all the time. The temporal differencing method detects the moving target by employing a pixel-wise difference method across successive frames.
Spatial differencing includes various approaches based on the semantic similarity of pixels across video frames. Thus, there can be a stable spatial relationship between current pixels and randomly selected pixels in the current frame. This approach became the basis of a detection algorithm that sets up a spatial sample set for each individual pixel and creates and defines a spatial sample difference consensus.
Recently, a new approach was introduced based on spatial filtering and region-based background subtraction. The proposed spatial filter uses the spatial coherence around the pixel neighborhood of foreground regions. It works great for removing noise and blurry parts of moving objects. This spatial filter can be easily extended to a spatio-temporal filter by including temporal neighbors.
Though the spatio-temporal segmentation results are temporally consistent, these methods often have to deal with over-smoothing problems.
3. Frame differencing
The frame differencing approach is based on detecting moving objects by calculating the pixel-by-pixel difference of two consecutive frames in a video sequence. This difference is then compared to a threshold to determine whether an object is in the background or foreground. This method has appeared highly adaptable to dynamic changes in the background, as it computes only the most recent frames. However, this approach also has some challenges to overcome. Particularly, it may inaccurately detect objects that move too fast or that suddenly stop. This happens because the last frame of the video sequence is treated as the reference, which is subtracted from the current frame.
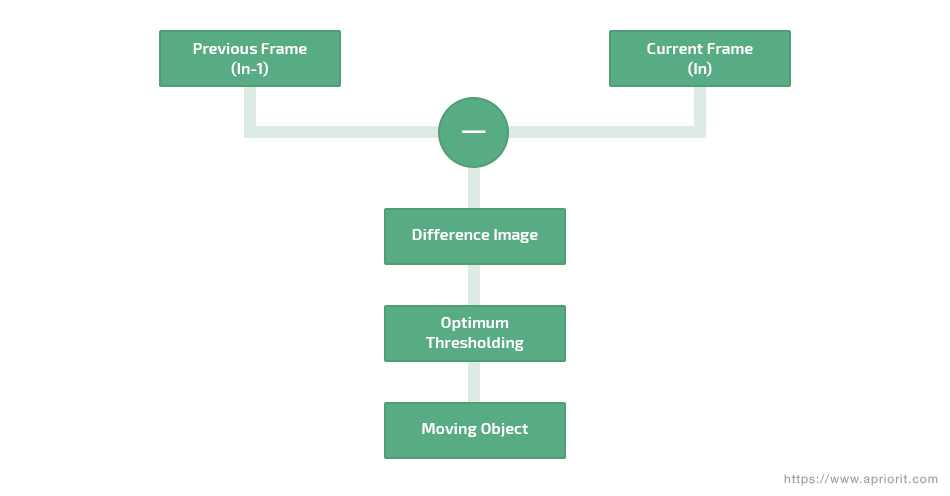
Figure 5. General concept of frame differencing
Frame differencing with a reference frame is a modified temporal differencing method that was first introduced in 2017. Difference images are calculated by subtracting two input frames one at each pixel position. Instead of generating difference images using the traditional continuous frame differencing approach, this approach uses a fixed number of alternate frames centered around the current frame.
4. Optical flow
The optical flow method uses the flow vectors of moving objects over time to detect them against the background. For every pixel, a velocity vector is calculated depending on the direction of object movement and how quickly the pixel is moving across the image. Optical flow can also be used for detecting both static and moving objects in the same frame. This approach is based on the following principles of motion vectors:
- In-depth translation creates a set of vectors with a common focus of expansion.
- Translation at a constant distance is reflected as a range of parallel motion vectors.
- Rotation perpendicular to the view axis forms one or more sets of vectors beginning from straight line segments.
- Rotation at a constant distance leads to a variety of concentric motion vectors.
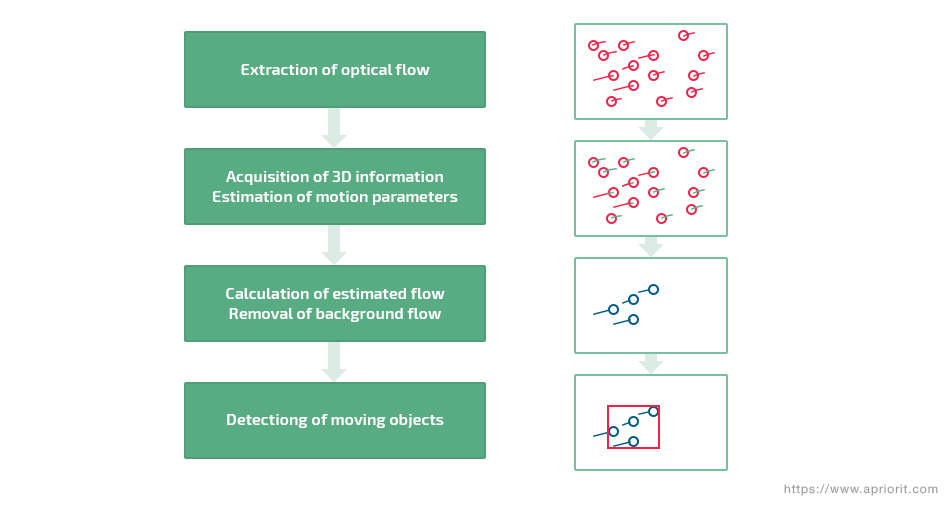
Figure 6. General concept of optical flow
This method has a high level of detection accuracy as it copes even when the camera is shaking. However, optical flow is time-consuming, as it requires computing the apparent velocity and direction of every pixel in a video frame. This method can be used for real-time moving object detection, but it’s very sensitive to noise and may require specialized hardware.
Let’s see what other challenges can lead to inaccurate detection of moving objects.
Related project
Building an AI-based Healthcare Solution
See how we used AI to help our client deliver an advanced healthcare solution for detecting and measuring follicles. With impressive results — 90% precision and a 97% recall rate — this project allowed our client to optimize doctors’ work and improve patient care.
7 critical challenges in detecting moving objects
The challenges of detecting moving objects in a video depend on the environment where this video is captured and the camera used. A video captured indoors may contain shadows and sudden changes in illumination.
If a video is filmed outdoors, there are even more challenges, as the environment is uncontrollable. In this case, we often have to deal with complex backgrounds, abrupt motion, occlusion, and moving shadows. Besides, there can be motion-blurred objects or partial lens distortion if a video is captured with a moving camera.
Let’s take a closer look at some of the most common challenges:
1. Illumination challenges
Sudden changes in lighting may lead to false positive object detection. For example, indoors there may be a sudden switching on or off of lights, or the light source might move. Outdoors, there may be fast changes from bright sunlight to cloudy or rainy weather, shadows that fall on moving objects, and reflections from bright surfaces. Additionally, there’s always a risk that the background may have the same color as a moving object.
That’s why the background model should be adaptable to variations in illumination and abrupt changes of brightness in order to avoid mistakes in detecting moving objects.
To deal with these challenges, researchers have offered a variety of solutions, including continuously updating background models, using local features of a moving object, and extracting Cepstral domain features.

Figure 7. Illumination challenge
2. Changes in the appearance of moving objects
All objects are three-dimensional in real life, and they may change their appearance when in motion. For instance, the front view of a car is different from the side view. If objects are people, they may also change their facial expressions or the clothes they wear. In addition, there can be non-rigid objects like human hands that change their shape over time. All of these changes to objects pose a challenge for object tracking algorithms. Various methods have been proposed to overcome this challenge. The most effective are those that focus on tracking articulated objects:
- The adaptive appearance model is based on the Wandering-Stable-Lost framework. This model creates a 3D appearance using a mixture model that consists of an adaptive template, frame-to-frame matching, and an outlier process.
- Learning motion patterns with deep learning allow the separation of independent objects using a trainable model that transfers optical flow to a fully convolutional network.

Figure 8. Appearance change challenge
3. Presence of unpredicted motion
When it comes to traffic surveillance, there’s a problem of detecting objects with abrupt motion. For instance, the jackrabbit start of a vehicle may cause a tracker to lose the object or cause an error in a tracking algorithm. Another source of detection issues are objects that move too slow or too fast. If an object moves slow, the temporal differencing method will be unable to detect the portions of the object. With a fast object, there will be a trail of ghost regions behind the object in the foreground mask. Intermittent motion — when an object moves, then stops for a while, and then starts moving again — is also challenging.

Figure 9. Abrupt motion
To overcome the challenge of unpredictable motion speed, researchers have proposed such solutions as:
- integrating the Wang-Landau algorithm
- introducing intensively adaptive Markov-chain Monte Carlo sampling
- integrating Hamiltonian dynamics
- and more
Read also
Using Modified Inception V3 CNN for Video Processing and Video Classification
Discover how your team can leverage Inception V3 for video analysis and image classification. Apriorit’s experts show all the steps, from adding new data classes to the pre-trained neural network to using the modified model for classifying video streams.
4. Occlusion
Occlusions can also make it much more difficult to detect and track moving objects in a video. For instance, when a vehicle drives on the road, it may become hidden behind tree branches or other objects. Objects in a video stream may be occluded fully or partially, which represents an additional challenge for object tracking methods.

Figure 10. Occlusion challenge
There are several ways you can deal with occlusions:
- using an online expectation-maximization algorithm
- maintaining appearance models of moving objects over time
- considering information on the spatio-temporal context
- integrating a deformable part model into a multiple kernel tracker
5. Complex backgrounds
Natural outdoor environments may be too complex for many moving object detection algorithms. The reason for this is that the background may be highly textured or contain moving parts that shouldn’t be detected as objects. For instance, fountains, clouds, waves, and swaying trees create irregular or periodic movements in the background. Dealing with such dynamics in the background is challenging.

Figure 11. Complex background
It’s been suggested that this problem can be overcome with an auto-regressive model, applying a Bayesian decision rule to statistical characteristics of image pixels, or using an adaptive background model based on homography motion estimation.
6. Moving shadows
We’ve already mentioned that shadows may fall on moving objects, but what if objects themselves cast shadows? These shadows also move, and they’re difficult to distinguish from the moving objects that cast them. Particularly, they prevent further image processing activities like region separation and classification that should come after background subtraction.

Figure 12. Shadow challenge
Among the proposed methods for overcoming this problem are a modified Gaussian mixture model and a shadow elimination algorithm based on object texture and features.
7. Camera problems
In addition to object-related challenges, there are also issues related to camera limitations. Video may be captured by shaky cameras or cameras with low resolution or limited color information. As a result, a video sequence may contain block artifacts caused by compression or blur caused by vibrations. All these artifacts can confuse moving object detection algorithms if they aren’t trained to deal with low-quality videos. A great variety of solutions have been proposed for overcoming camera challenges, but this problem remains open.

Figure 13. Camera problems
Solving moving object detection challenges with deep learning
Thanks to the availability of large video datasets like CDnet and Kinetics and deep learning frameworks like TensorFlow and Caffe, neural networks are beginning to be used for dealing with the challenges of moving object detection. In this section, we want to show you when to use deep learning for object detection, and how various neural networks can be applied to eliminate drawbacks of moving object detection methods and overcome general challenges of detecting moving objects in a video sequence.
Read also
Applying Long Short-Term Memory for Video Classification
Explore how AI-powered LSTM models can significantly improve the accuracy and efficiency of video classification tasks.
Convolutional neural networks
Convolutional neural network (CNN) models have already provided impressive results in image recognition. Their application to video processing has become possible by representing space and time as equivalent dimensions of the input data and performing 3D convolutions of both these dimensions simultaneously. This is achieved by convolving a 3D kernel to a cube, formed by stacking multiple contiguous frames.
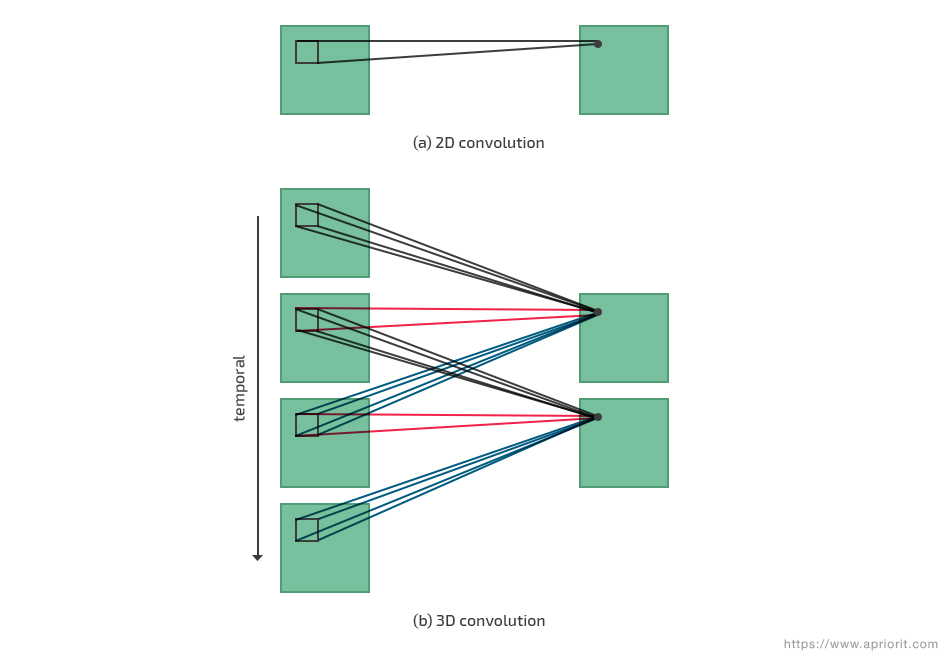
Figure 14. Visual comparison of 2D and 3D convolution
Using a CNN model for background subtraction shows better performance for cameras with smooth movement in real-time applications. In addition, a pre-trained CNN model can work well for detecting the trajectories of moving objects in an unconstrained video.
Recurrent neural networks
Recurrent neural network (RNN) models combine convolution layers and temporal recursion. Long RNN models are both spatially and temporally deep, so they can be applied to various vision tasks involving sequential inputs and outputs, including detecting an object’s activity that’s deep in time.
An RNN can make use of the time-order relationship between sensor readings, so these models are recommended for recognizing short object motions with a natural order. In contrast, CNN models are better at learning deep features contained in recursive patterns, so they can be applied for detecting long-term repetitive motions.
Long short-term memory (LSTM) is an improved version of RNN that can not only regress and classify object locations and categories but also associate features to represent each output object. For instance, an LSTM model combined with deep reinforcement learning can be successfully applied for multi-object tracking in video. LSTM can also associate objects from different frames and provides great results in detecting moving objects in online video streams.
Deep neural networks
Background subtraction based on deep neural network (DNN) models has demonstrated excellent results in extracting moving objects from dynamic backgrounds. This approach can automatically learn background features and outperform conventional background modeling based on handcraft features.
In addition, DNN models can be used for detecting anomalous events in videos, such as robberies, fights, and accidents. This can be achieved by analyzing a moving object’s features by their velocity, orientation, entropy, and interest points.
Generative adversarial networks
Generative adversarial network (GAN) models have been applied to solve optical flow limitations to detection near motion boundaries in a semi-supervised manner. This approach can predict optical flow by leveraging both labeled and unlabeled data in a semi-supervised learning framework. A GAN can distinguish flow warp errors by comparing the ground truth flow and the estimated flow. This significantly improves the accuracy of flow estimation around motion boundaries.
Deep learning vs traditional methods
Considering what we’ve just discussed, it’s obvious that neural networks cope with moving object detection challenges better than traditional algorithms. Let’s explain why.
- Deep learning performs better at video processing tasks by computing on more powerful resources: GPUs instead of CPUs.
- CNNs and improved models thereof have deeper architectures that ensure exponentially greater expressive capabilities.
- Deep learning allows for combining several related tasks; for instance, Fast-RCNN can both detect moving objects and perform localization at the same time.
- CNNs and improved neural networks have a great capacity to learn, which allows them to recast object detection challenges as high-dimensional data transformation problems and solve them.
- Thanks to its hierarchical multi-stage structure, a deep learning model can reveal hidden factors of input data by applying multilevel nonlinear mappings.
- CNN models work better for tasks that include not only detection of moving objects but also classification and selection of regions of interest.
Conclusion
Detecting moving objects in video streams is a promising yet challenging task for modern developers. Object detection in a video can be applied in many contexts — from surveillance systems to self-driving cars — to gather and analyze information and then make decisions based on it.
In this article, we’ve underlined the challenges of detecting moving objects in video and have shown the limitations of existing detection methods. Fortunately, neural networks provide us with many possibilities to improve the accuracy of moving object detection, as they provide access to greater computational resources.
Whatever software project you have in mind, Apriorit’s engineers are ready to help you turn your ideas into real-life, functioning products. Our expert AI & ML development teams have vast experience developing advanced solutions and functionalities for various purposes and industries.
Need help creating video processing functionality?
Achieve accurate moving object detection in video and improve your solution’s overall performance with Apriroit’s first-class AI & ML engineers.
Have a question?
Ask our expert!
R&D Delivery Manager


