 Skip to main content
Skip to main content

Android is considered one of the most frequently attacked platforms. While it isn’t possible to implement quantum encryption in every app, you should consider applying some level of data ciphering. There are dozens of ways to encrypt data, from simple hashing to digital signatures with a combination of several algorithms. In this article, our Apriorit expert reviews the pros and cons of seven methods of encryption in Android applications and shows how to implement them.
Contents:
Why is encryption important?
Contractor predicts that in 2019, mobile platforms will be the largest cybersecurity threat vector. According to Norton Android and iOS security comparison, Android has three times more known vulnerabilities than iOS. Therefore, adding cryptographic algorithms is vital for ensuring data security in your application and mitigating attacks.
In this article, we’ll review the seven most popular encryption methods for Android:
- symmetric encryption
- asymmetric encryption
- hashing
- digital signature
- end-to-end encryption
- elliptic-curve cryptography
- HMAC
The choice of encryption method depends on your project’s needs. Some algorithms, like symmetric encryption and hashing, are fast and easy to implement but provide you with limited protection. Others, like digital signature and asymmetric encryption, take a lot of time to process data but ensure its security.
Let’s take a close look at these methods.
Planning to build an Android application?
Let Apriorit’s experts in mobile development help you create a protected solution, using the best encryption methods.
Symmetric encryption
Symmetric encryption is based on the Advanced Encryption Standard (AES). The AES algorithm is a symmetric block cipher that can encrypt (encipher) and decrypt (decipher) information. It uses only one secret key to encrypt plain data, and uses 128-, 192-, and 256-bit keys to process 128-bit data locks. This algorithm receives data and encrypts it using a password. The same password is used to decipher the data with a decryption algorithm (or the same encryption algorithm, in some cases).
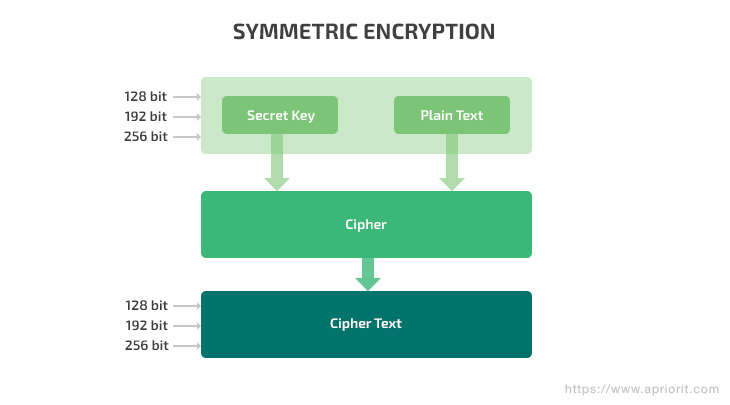
Symmetric encryption is fast and easy to implement. However, it causes certain security issues.
If your application uses symmetric encryption, you should pay attention to creating and securing keys. Keys should be complicated and well-protected so that hackers can’t obtain them using credential stuffing or brute-forcing. You should consider a safe method for distributing keys and storing keys and keeping them out of the wrong hands. Keys shouldn’t be transmitted in plain text over the network or written on a sticky note and attached to the monitor.
Despite its limitations, symmetric encryption is widespread because it’s fast and solid. It’s used in WhatsApp, Firefox, and early versions of Microsoft Outlook. File encrypting ransomware also uses this method. Attackers encrypt files on victims’ computers using symmetric encryption. Decrypting data is possible only with the key, so attackers extort money from victims in exchange for the decryption key.
Let’s see how symmetric encryption can be implemented in an Android application:
public class Aes256Class {
private SecretKey secretKey;
public Aes256Class() {
try {
KeyGenerator keyGenerator = KeyGenerator.getInstance("AES");
keyGenerator.init(256);
secretKey = keyGenerator.generateKey();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
}
public byte[] makeAes(byte[] rawMessage, int cipherMode) {
try {
Cipher cipher = Cipher.getInstance("AES");
cipher.init(cipherMode, this.secretKey);
byte[] output = cipher.doFinal(rawMessage);
return output;
} catch (Exception e) {
e.printStackTrace();
return null;
}
}
}We initialized the keyGenerator object in the Aes256Class() constructor. It’s set to a key size of 256 bits. Then, using the generateKey() function, a random key with the specified size (256 bits) is generated.
The source byte array and the operation mode of the Cipher class object are passed to the makeAes function:
Cipher.ENCRYPT_MODE or Cipher.DECRYPT_MODE.
In the class with the main function, we can call the methods described above in this way:
public static void main(String[] args) {
Aes256Class aes256 = new Aes256Class();
String targetString = "Hello";
byte[] encryptedString = makeAes(targetString.getBytes(), Cipher.ENCRYPT_MODE);
Log.d("Encoded string: ", new String(encryptedString));
byte[] decodedString = makeAes(encryptedString, Cipher.DECRYPT_MODE);
Log.d("Decoded string: ", new String(decryptedString));
}As a result, we get the following code:
Encoded string: a�F=4�Q2�d����
Decoded string: HelloHere are key pros and cons of symmetric encryption:
| Pros | Cons |
|
|
Read also
Does Encryption Protect Data Against Man-in-the-Middle Attacks?
Secure your project against common attacks. Find out how encryption can help you protect data from MITM attacks by exploring our practical example.

Asymmetric encryption
Asymmetric encryption, or public key encryption, is a type of encryption algorithm that uses a pair of keys: open (or public) and closed (or private). The public key is commonly known to everyone in the network, while the private key is stored on the server or on other key owner’s side and must be kept secret. Asymmetric encryption is often based on the RSA-2048 algorithm. RSA keys are currently recommended to be at least 2048 bits long.
For this type of encryption, user names are often conditional, since a message encrypted with one of the keys can only be decrypted using the second key. In other words, the keys are equivalent.
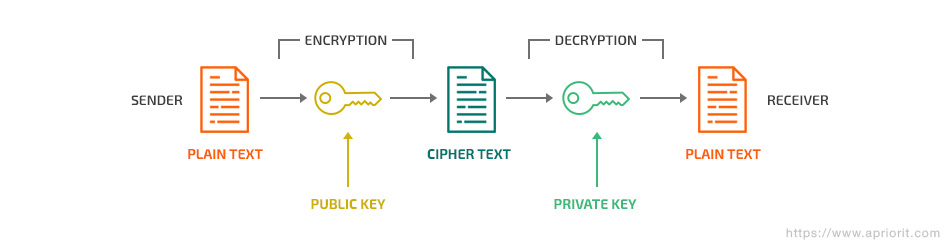
This type of Android encryption algorithm allows you to freely distribute the public key over the network, since without the private key it’s impossible to decrypt the original text. Thanks to the Secure Sockets Layer (SSL) protocol, it’s easy to establish a secure connection with users since the private key (the password) is stored only on the server side. If an insecure connection warning appears on a website with the HTTPS prefix, it means that this website uses asymmetric encryption and it’s possible that its private key was leaked to the public and might have been compromised by attackers. Therefore, the connection may not be secure.
Combination of symmetrical and asymmetrical encryption is widely used for protecting websites. Every time you access an HTTPS website (even this one), your browser receives a public key for the site certificate. It uses this key to obtain a key for symmetric algorithm, and encrypt the data you send.
This technology is used for blockchain transactions and smart contract encryption. It’s also used by Facebook Android application.
Asymmetric encryption can be implemented this way:
// Generate key pair for 2048-bit RSA encryption and decryption
Key publicKey = null;
Key privateKey = null;
try {
KeyPairGenerator kpg = KeyPairGenerator.getInstance("RSA");
kpg.initialize(2048);
KeyPair kp = kpg.genKeyPair();
publicKey = kp.getPublic();
privateKey = kp.getPrivate();
} catch (Exception e) {
Log.e("Crypto", "RSA key pair error");
}
// Encode the original data with the RSA private key
byte[] encodedBytes = null;
try {
Cipher c = Cipher.getInstance("RSA");
c.init(Cipher.ENCRYPT_MODE, privateKey);
encodedBytes = c.doFinal(targetString.getBytes());
} catch (Exception e) {
Log.e("Crypto", "RSA encryption error");
}
Log.d("Encoded string: ", new String(Base64.encodeToString(encodedBytes, Base64.DEFAULT)));
// Decode the encoded data with the RSA public key
byte[] decodedBytes = null;
try {
Cipher c = Cipher.getInstance("RSA");
c.init(Cipher.DECRYPT_MODE, publicKey);
decodedBytes = c.doFinal(encodedBytes);
} catch (Exception e) {
Log.e("Crypto", "RSA decryption error");
}
Log.d("Decoded string: ", new String(decodedBytes));The encrypted data looks like this:
Encoded string: YWHwinQjnyY+lETkmyJWCrH7VQPezfqu7kjs943TlZby8A6ij9vQea3hj6zyZWMmTETGhsmfvlqzTyf3F/RuR+6BUPSrc2VsoP05LlLiviqL6D/hPTbsbN+Ib/DKb4SieDJ9Cf0qkcRGkw9NKJk0DRgMABUBsxPhzhYPv791gaDKJuafZ9FtG55ocrIu9ImK53dhAavwAlkwQoL4voe651p4RrL+QtHAyK5g
qIPPCHKWKwhrgg+Y2dCex04udT4/BDCoFMmTvVtZk0TkVuEbvgzitxyyptxAB7/RCkFmqeFVqh17hSr1dEhXebmsx4R3WR8XIf12YdAuRzz5rn5AOg==
Decoded string: HelloLet’s consider some pros and cons of asymmetric encryption:
| Pros | Cons |
|
|
Related project
Cross-Platform Data Backup Solution Development: Windows, Android, macOS, iOS
Explore the details of implementing their solution for Android, iOS, macOS, and Windows. Find out how Apriorit helped our client to double the total number of users thanks to releasing all new versions of their data backup and recovery software.
Hashing
Hashing uses a mathematical algorithm to check the integrity of data. A hash function takes some information and displays a seemingly random string of symbols. This string always has the same length, only with a different character sequence. The ideal hash function creates unique values for each input. And the same input will always produce the same hash. Therefore, you can use hashing to check data integrity.
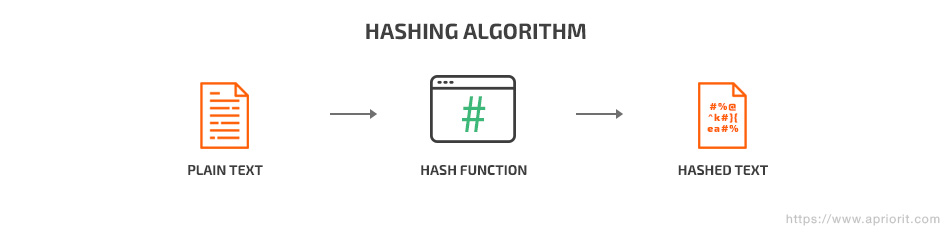
In Android applications, hashing is used to encrypt user passwords. A hashing algorithm makes it nearly impossible to obtain the original password out of the hash.
Let’s create a new line, hash it, and save the result in a variable:
String targetString = "Hello";
MessageDigest messageDigest = null;
byte[] digest = new byte[0];
try {
messageDigest = MessageDigest.getInstance("MD5");
messageDigest.reset();
messageDigest.update(st.getBytes());
digest = messageDigest.digest();
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
}
BigInteger bigInt = new BigInteger(1, digest);
String md5Hex = bigInt.toString(16);
while( md5Hex.length() < 32 ){
md5Hex = "0" + md5Hex;
}
Log.d("Encoded string: ", md5Hex);Here’s our “Hello” line after hashing:
Encoded string: 8b1a9953c4611296a827abf8c47804d7Hash functions have several strong and weak points:
| Pros | Cons |
|
|
Read also
5 Emerging Cybersecurity Trends for Software Development in 2024 to Futureproof Your Product
Discover how data encryption and other key protection methods can help you deliver secure and efficient software.

Digital signature
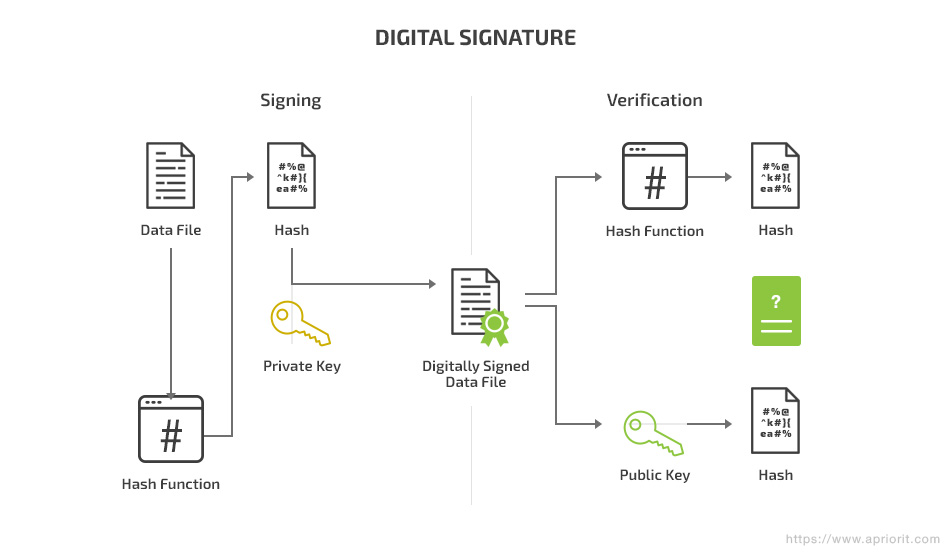
A digital signature algorithm is considered one of the best encryption algorithms for Android applications. It combines hashing and asymmetric encryption. Messages are hashed first and then encrypted with the sender’s private key.
The recipient uses the sender’s public key to extract the hash from the signature, then hashes the message again to compare the resulting hash with the extracted hash. If the public key really belongs to the sender and the decryption of the public key was successful, you can know the message actually came from the sender. The matching hashes indicate that the message wasn’t changed in any way during transit.
Digital signatures combine hashing and asymmetric encryption (as described above).
If you decide to implement a digital signature algorithm in your application, here are some things to consider:
| Pros | Cons |
|
|
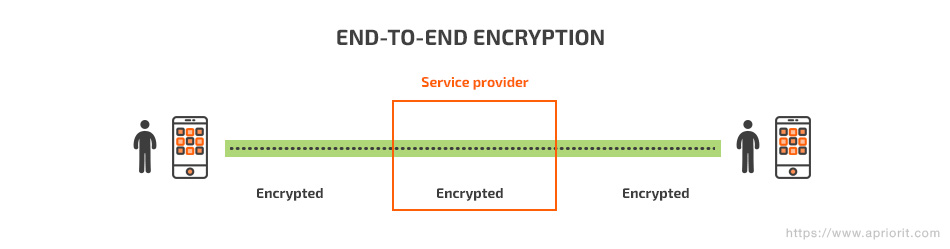
End-to-end encryption
The end-to-end encryption (E2EE) method implies that the communication between two endpoints (clients) is encrypted. It’s based on the RSA algorithm and resembles asymmetric encryption. The main feature of this method is that the server only transmits encrypted messages, with no chance to read or modify the dataflow between endpoints.
Analyzing open documentation, we can assume that Telegram encryption is based on E2EE. Its authenticated key distribution uses the classic Diffie-Hellman (DH) protocol. This protocol bridges asymmetric (RSA) and symmetric (AES) encryption, enabling exchange of encrypted messages by transferring only public keys via an open channel. To do this, the protocol generates session keys, which remain a shared secret between two users. A session key is generated based on the secret key of the sender and the public key of the recipient.
An E2EE implementation closely resembles asymmetric encryption.
E2EE has some considerable pros and cons:
| Pros | Cons |
|
|
Related project
Developing a Custom MDM Solution with Enhanced Data Security
Find out the success story of developing an enterprise mobile device management solution for securely managing Android tablets. Read on to discover how Apriorit’s work helped our client expand their services, maintaining the required level of data security.
Elliptic-curve cryptography
Elliptic-curve cryptography (ECC) uses public keys based on the algebraic structure of elliptic curves over finite fields.
In Android application development, ECC often uses Curve25519. This is an elliptic curve with a set of parameters selected specifically to provide higher encryption speed. Its algorithm resembles asymmetric encryption.
To generate a new pair of keys, we add any sequence of 32 random bytes to the algorithm. This will be our private key. Then, we use Curve25519 to generate 32 bytes of the public key. Finally, we exchange our public key with another endpoint and calculate a common key for data shared with this endpoint.
Curve25519 is used as the default key exchange in OpenSSH, I2P, Tor, Tox, Facebook Messenger, and even iOS.
Let’s see how Curve25519 is implemented:
// Create Alice's secret key from a big random number.
SecureRandom random = new SecureRandom();
byte[] alice_secret_key = ECDHCurve25519.generate_secret_key(random);
// Create Alice's public key.
byte[] alice_public_key = ECDHCurve25519.generate_public_key(alice_secret_key);
// Bob is also calculating a key pair.
byte[] bob_secret_key = ECDHCurve25519.generate_secret_key(random);
byte[] bob_public_key = ECDHCurve25519.generate_public_key(bob_secret_key);
// Assume that Alice and Bob have exchanged their public keys.
// Alice is calculating the shared secret.
byte[] alice_shared_secret = ECDHCurve25519.generate_shared_secret(
alice_secret_key, bob_public_key);
// Bob is also calculating the shared secret.
byte[] bob_shared_secret = ECDHCurve25519.generate_shared_secret(
bob_secret_key, alice_public_key);ECC has the following pros and cons:
| Pros | Cons |
| Faster than other encryption methods we’ve reviewed in this article. | Only cryptographically strong elliptic curves provide a sufficient level of security. |
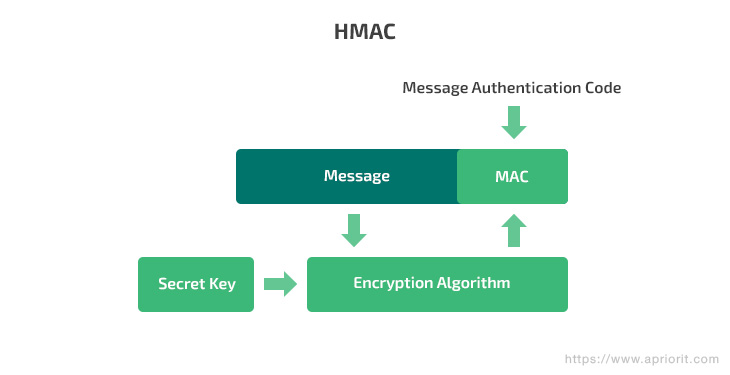
HMAC
A hash-based message authentication code (HMAC) is a type of message authentication code that combines hashing and a cryptographic private key. This key is known only to a server and an endpoint. The endpoint hashes data and sends it to the server. The server decrypts it using the private key and compares the hashed data with the original message.
HMAC often uses the SHA-256 algorithm, which is based on the SHA-2 hash function and is considered to be more secure than its predecessors such as the MD-5 and SHA-1 algorithms.
This authentication method is used for both encryption and authentication. Communication in Signal and WhatsApp is based on HMAC-SHA256.
HMAC-SHA256 is implemented this way:
public static String encode(String key, String data) throws Exception {
Mac sha256_HMAC = Mac.getInstance("HmacSHA256");
SecretKeySpec secret_key = new SecretKeySpec(key.getBytes("UTF-8"), "HmacSHA256");
sha256_HMAC.init(secret_key);
return Hex.encodeHexString(sha256_HMAC.doFinal(data.getBytes("UTF-8")));
}Let’s consider some pros and cons of HMAC:
| Pros | Cons |
|
|
Conclusion
In this article, we’ve reviewed seven Android encryption methods that are used in applications such as Telegram, Signal, and WhatsApp. Some of them are fast to implement and use; others take time but provide more secure ciphering. Though RSA (one of the simplest and fastest encryption algorithms for Android apps) is considered easy to crack, developers of instant messengers haven’t abandoned this encryption method. Instead, they enhance it by combining it with other algorithms.
For example, some developers use RSA, but change the key for almost every message. Only the developers know which cipher will be used next. Also, additional methods of verification are implemented, such as visual comparison by conversation participants of symbols displayed on the screen. In any case, the topic is very extensive, and there’s no one right encryption method. You need to select an encryption method depending on your task.
At Apriorit, we have professional engineering teams with strong expertise in cybersecurity, mobile development, and data processing technologies ready to help you overcome any technical challenges.
Have a complex encryption project in mind?
Challenge our mobile development team with your tricky technical tasks, and we’ll help you deliver a secure and reliable mobile solution.
Have a question?
Ask our expert!
Director of Global Markets Development


