 Skip to main content
Skip to main content

Like humans, artificial intelligence (AI) solutions aren’t always fair and free from prejudice. Reflecting the preferences and preconceptions of their creators, AI models become biased and produce incorrect predictions, often causing problems and business losses for end users.
In this article, we look closer at the phenomenon of AI bias. We determine what AI bias is, how it makes its way into your AI-based solutions, what effects it can possibly have on your projects, and how you can get rid of it. This article will be helpful for developers working on AI-based solutions and everyone who wants to know more about the importance of fairness in AI.
Contents:
- What is bias in artificial intelligence?
- How bias makes its way into AI solutions
- Common types of bias in AI solutions
- Context dependencies
- Facing the problem of biased AI systems
- What’s the main danger of AI bias?
- Dealing with the problem of bias in AI solutions
- Is there a way to make your AI solution unbiased?
- Recommendations on eliminating AI bias
- Conclusion
What is bias in artificial intelligence?
The output of artificial intelligence (AI) systems is highly dependent on the quality and objectivity of the data sets used for training their algorithms and models. When data is not diverse or is incomplete, there’s a chance of bias.

Colloquially speaking, bias can be seen as prejudice or unfairness towards someone or something. However, when we talk about bias in artificial intelligence, we mean the situation when an algorithm or model systematically makes the same mistakes and produces prejudiced conclusions due to errors and faulty assumptions in the machine learning process.
AI bias is strongly driven by human judgments: the creators of a machine learning (ML) model choose a particular algorithm, specific datasets, model construction practices, and so on. Each of these choices depends on human aspects and reflects the mindset of the machine learning model developer and, therefore, opens possibilities for introducing some of the developer’s biases.
Here’s a quick test you can run yourself to see how bias works: try searching for images of hands using just the word hands. The first dozen images shown to you by Google will most likely be of white people only. But if you try searching for black hands instead, Google won’t just show you the hands of people of a certain race: there will also be pictures of a white hand reaching towards a black hand or hands that are dirty from work.
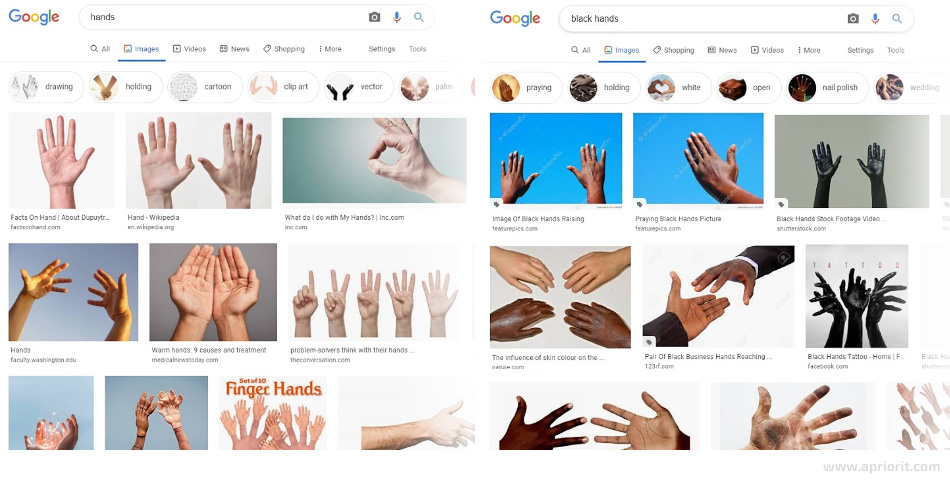
This is how bias distorts AI — it reflects the mindset of a certain person, group of people, or even society.
It’s noteworthy that bias is not only an ethical issue: unfair and prejudiced conclusions create business risks and prevent AI models from successfully accomplishing the goals they were created for. But how does bias get into AI models and algorithms? You’ll find the answer in the next section.
Bring your AI vision to life with Apriorit
Apriorit’s team is ready to design and build the perfect AI solution for your unique business challenges.
How bias makes its way into AI solutions
Before you figure out how to fix the problem of bias in machine learning, you need to understand the ways it can enter your algorithms and models.
Any AI system is only as good as the data it’s trained with. And data is the key source of bias in any AI solution. However, biased data can be introduced at different stages of the machine learning process.
There are three key levels at which bias can be introduced:
- Dataset level — The data you use to train your model can be improperly pre-processed or reflect prejudices. For instance, your dataset may be unbalanced. If a dataset lacks information on one factor and contains too much data on an opposite factor, it creates preconditions for biased results (see the example below). Or your dataset may reflect prejudices that exist in your society and thus favor one group of factors or characteristics over another.
- Algorithm or model level — Developers choose not only what data to use for training an algorithm or model but also what parameters to consider when making predictions. Also, developers may choose an algorithm based on their personal assumptions and without considering the way machine learning tools work.
- AI goal level — Your AI model may become biased from the moment you determine its goal, long before you put any data into it. AI models are created for a specific purpose: loan services use AI to minimize the risk of financial losses, traders use AI to increase sales to their target audiences, and so on. The goal you build your AI model for can create preconditions that make it biased against a certain group, characteristic, or factor.
Let’s see how this works in practice.
Say you need to train a model to make it recognize cats and dogs in images. Your training dataset, however, only contains images of black dogs and white and red cats. So when challenged with an image of a white dog, your model will most likely classify it as a cat (see Figure 1). This is how dataset bias or measurement bias works.
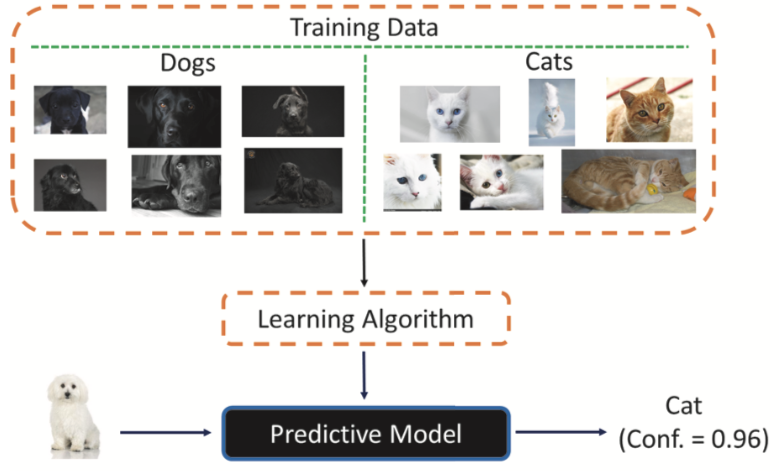
Figure 1. Illustration of dataset bias. Image credit: Tecs USP
Dataset bias is usually caused by incorrect labeling of the original data or lack of data diversity — when a specific characteristic or factor is underrepresented or overrepresented in the dataset.
Algorithms and models, on the other hand, can have built-in biases that reflect the preferences of their developers. For instance, a juridical AI-based tool called COMPAS was found to display racial prejudice and favor people of one race over another. The reason the algorithm was making incorrect predictions was not in the data itself but in the way humans taught the algorithm to interpret this data.
Finally, the main function and goal of an AI solution often serves as an additional cause of bias. For example, assume you’re building a solution that predicts the financial solvency of loan applicants. What factors will you use to determine the applicants whose loan requests will be approved?
The key challenge here is to carefully choose not only what parameters to add to your model but also how to train that model. In the loan example, you can build a model that’s inclined toward so-called type II errors, or false negatives. In order to minimize the risk of unrepaid loans, you may build a model that provides a significant number of false negatives and denies loans even to those who are able to repay.
Now let’s look at the most common types of AI bias.
Read also
AI Platform as a Service: Definition, Key Components, Vendors
Discover how AI PaaS solutions can streamline your product development by offering pre-built AI and ML tools. Our experts show how to efficiently integrate AI into your solutions and explore top AI PaaS vendors on the market.

Common types of bias in AI solutions
Knowing the type of bias you’re faced with is the first step to fixing it. There are two key groups of biases present in AI models:
- Statistical
- Human (cognitive)
Statistical bias occurs when you use unrepresentative data, meaning your dataset doesn’t reflect the real-world data you want your model to process. Remember our example with cats and dogs? That’s a textbook example of statistical bias. The dataset used for training lacked diversity and included a limited number of fur patterns.
With cognitive bias, things are a bit more complicated. Cognitive bias usually reflects misconceptions and prejudices that already exist in a society, and it may enter your solution through a biased classifier.
For the learning process, any AI system needs two components: a set of data (text, images, audio recordings, etc.) and a classifier to learn on that data. The AI system learns to understand and interpret data based on the classifier. But different people can see and interpret the same things in different ways based on their personal opinions and stereotypes.
You can test this concept with image search. Image classifiers, initially filled with data labeled by humans, are often prone to gender-related biases. Google image search, for example, displays mostly female nurses and teachers and male doctors and entrepreneurs.
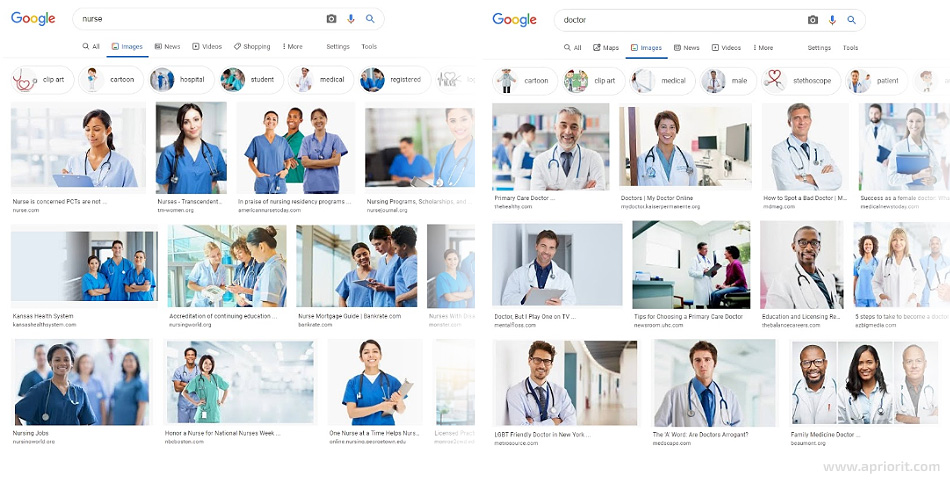
With natural language processing (NLP) solutions, an AI system learns from the way we talk about different things, thus copying the stereotypes and slang common to a specific region or demographic.
Context dependencies
Context also needs to be taken into account. The scheme below shows attributes commonly associated with bias.

However, the way these attributes are seen fully depends on the context. For example, for an insurance service, taking the age of an applicant into account is a standard procedure. At the same time, a solution that filters out job applicants of a certain age may be seen as ageist.
Therefore, rules of fairness should be determined for each use case before they are implemented into an AI model. Furthermore, using the same model for different use cases isn’t the best choice. Doing so may increase the level of bias since the same rules aren’t likely to be considered equally fair for different cases.
Are there any other challenges posed by biased AI models? What are the possible consequences of not fixing these systematic errors in your solution? We answer these questions in the next section.
Read also
Navigating AI Image Processing: Use Cases and Tools
Explore how AI can revolutionize your image processing tasks by automating workflows and improving accuracy. This article covers key use cases, essential tools, and common challenges of developing AI-based image-processing solutions.

Facing the problem of biased AI systems
Biased algorithms have already made their way into our daily lives. Even the biggest companies on the AI market aren’t immune to the threat of erroneous algorithms.
Here are some of the most famous examples of algorithm bias:
LinkedIn’s search — LinkedIn had an issue with gender-related bias. The first users searching for high-paying jobs on this platform were males, so LinkedIn’s algorithms ended up showing offers for high-paying jobs to men more frequently than women.
Amazon’s hiring algorithms — Amazon developed its own hiring tool, but later they abandoned it because of gender-related bias. Amazon’s algorithms were trained on CVs submitted to the company over the last decade. As in many tech companies, the number of female applicants was much lower than the number of male applicants, so the algorithm determined the male gender as one of the factors for approving a candidate.
Word2vec algorithms — Word embedding, a set of techniques used for teaching a machine to understand human language, is commonly performed with the help of AI. Unfortunately, bias can make its way in here, too. The Word2vec algorithms used Google news as a training dataset, so the way they solve word embedding challenges is full of stereotypes and misconceptions. For instance, the algorithm sees the term homemaker as a female alternative to the term computer programmer.
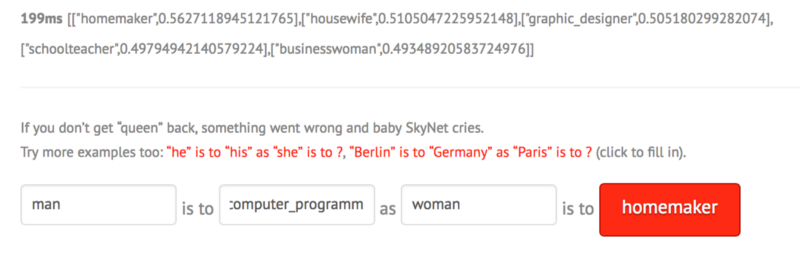
Image credit: Experfy
Microsoft chatbots — When the first self-learning chatbots were presented, some people taught these basic AI systems slang phrases and mean words just for fun. Trying to moderate the work of intelligent chatbots, developers create more and more complex rules. However, the more parameters and attributes are included in the algorithm, the higher the risk of bias or of censorship occurring without context. For example, Microsoft’s latest chatbot, Zo, was criticized for extreme censorship of any content related to politics, certain races, and other controversial topics. The Zo chatbot was shut down in 2019.
As you can see, even the slightest inaccuracy in an AI algorithm can lead to its making faulty predictions.
Read also
How to Develop Smart Chatbots Using Python: Examples of Developing AI- and ML-Driven Chatbots
Learn how to enhance user communication through smart chatbot solutions. In this article, our developers share practical examples and expert insights on creating AI-driven chatbots to automate customer support and optimize business processes.

What’s the main danger of AI bias?
AI models and algorithms are incapable of getting rid of bias on their own. Furthermore, they can amplify bias that’s already present in their datasets and algorithms as well as add new errors when self-learning.

Here’s how this works in practice: Imagine you have a 75% accurate image classification algorithm that predicts whether an image is of a dog or a cat. To train this algorithm and improve its accuracy, you use a biased dataset where 80% of animals pictured indoors are cats. In this case, the algorithm can increase its accuracy to 80% just by predicting that every animal pictured indoors is a cat. But this may also increase the bias in this algorithm. The same works for gender stereotypes.
The lower the accuracy of the algorithm, the more likely it is that it will try to improve itself by taking advantage of biases in the training data. And the higher the level of bias, the higher the risk of unfair AI predictions.
To be more specific, we can separate at least three common scenarios of unfairness in AI:
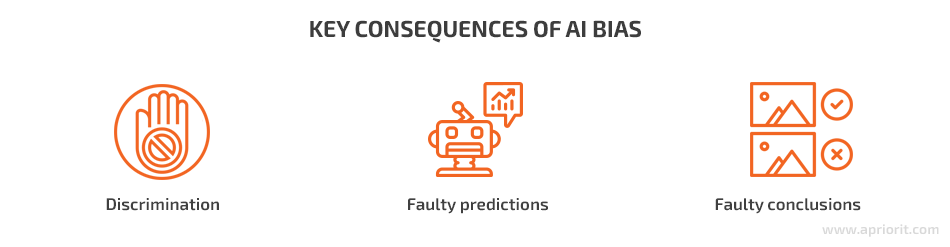
- Discrimination — Based on different attributes such as gender, age, or race, an AI system may discriminatе against certain groups of people. Think back to the LinkedIn example, where high-paying jobs were displayed mostly to male users.
- Incorrect predictions — A biased AI solution can make incorrect predictions and exclude a certain part of content or people that otherwise would have been included in the analysis. Incorrect predictions are often (but not necessarily) the result of discrimination. In the case of a loan service, AI may wrongfully filter out all applicants who live in an area with a high rate of default.
- Incorrect conclusions — The use of biased data introduces another serious danger — the possibility of misinterpreting input data and getting incorrect results of analysis. For instance, if an AI solution lacks relevant data, it may incorrectly analyze information from a patient’s medical history and make the wrong diagnosis.
The most important question here is whether there’s a way to reduce the level of bias in your AI solution. Let’s find out.
Dealing with the problem of bias in AI solutions
There are differing opinions on whether AI bias can be fixed. Some claim that since the key source of bias is data, all you need to do is not use biased datasets. Others suggest that eliminating bias from your algorithms requires a bit more time and effort.
Here are the key reasons why AI bias can be challenging to get rid of:
- Unknown source — One of the main challenges of reducing the level of bias is that you usually don’t know where and when it will enter your AI system. Most of today’s datasets aren’t as primitive as the one we described in our example with cats and dogs. They contain thousands of data points, and bias can be hidden in disproportionalities within the dataset as well as in incorrect labeling.
- Lack of context — When developers train an AI model or algorithm, they can’t foresee all possible situations and scenarios that it will have to work with in the future. As a result, an algorithm that is free from bias in one use case may turn out to be completely biased and unusable for a different use case.
- Testing flaws — Developers are supposed to test newly created models and algorithms for accuracy. The problem is that AI models are usually tested with data from the same dataset they were trained on. Which means that the tests will contain the same biases as the training data.
- Mutilation of analysis results — Perhaps the biggest challenge of eliminating AI bias is the need to keep a balance between the relevance of data and absence of bias. For instance, excluding all race-related data from a training dataset may lead to results that don’t correlate with the real situation in your target audience.
So how can you possibly fix your AI solution? One of the best options is to aim for fairness and diversity in the data you use.
Related project
Developing an Advanced AI Language Tutor for an Educational Service
Explore our success story of building an advanced language tutor for our client. Apriorit experts Integrated natural conversation capabilities and mistake correction, creating an AI-powered chatbot that enhances interactive learning and scales effectively.

Is there a way to make your AI solution unbiased?
There are two factors to pay special attention to when building an AI solution:
- Fairness
- Transparency

Fairness is essentially a social construct that developers can use to judge whether an algorithm is biased. Curiously, there’s no single definition of fairness when it comes to AI algorithms. A group of researchers from the University of Massachusetts determined 20 different variations of fairness [PDF] used in modern AI solutions.
The tricky thing is that when you choose one approach to defining fairness, you’re automatically violating some aspects of a different approach. Therefore, no AI solution can be completely fair and bias-free.
It’s also important for AI algorithms to be transparent, meaning that you need to clearly understand how and why an algorithm makes a certain decision. You need to ensure that you have a clear understanding of what your AI is doing and can explain the model you’re using. Otherwise, you’ll have to deal with the so-called black box problem, when you don’t have a clear view of the steps your AI model takes when solving a problem and you can’t explain why it made a decision.
Some governments are even trying to come up with a set of recommendations for eliminating bias from AI-based decision-making systems. One example is the Algorithmic Accountability Act of 2019 in the US. This act obligates companies that use AI-based decision-making solutions to perform “impact assessments” on their algorithms. In particular, companies have to look for and fix any issues with accuracy, bias, fairness, discrimination, privacy, and security.
In the UK, the Centre for Data Ethics and Innovation provides recommendations on resolving AI-related ethical issues. And Singapore is currently working on a Model AI Governance Framework meant to set basic standards and principles for AI technologies.
Recommendations on eliminating AI bias
To lower the risk of bias, you can build your AI solution with transparency, social responsibility, and fairness in mind. Here’s a set of basic recommendations for increasing the level of fairness in your AI solutions:
- Use high-quality and diverse data — Train your model on massive, high-quality datasets that include diverse data. While it might seem convenient to focus on your target audience or region when choosing a dataset, using too narrow a dataset may lead to unfairness in the final solution.
- Test your model with different datasets — Don’t use part of your training data as the only data source for testing your AI model. Instead, consider training and testing your model on one dataset, then training it on another dataset, and then, finally, testing your model on data from both datasets. In this way, you have a better chance of detecting and fixing possible biases inherited from the training data.
- Run cross-checks of your algorithms — Even if you use diverse and complete datasets, there’s still a risk of underrepresenting or overrepresenting a particular characteristic or factor. By cross-checking your algorithms, you can detect suspicious patterns and biases.
- Use AI monitoring algorithms — Deploy a separate AI policing algorithm that runs in the background and continuously checks your main solution for possible flaws and biases.
- Deploy ML algorithm evaluation tools — There are a number of tools you can use to evaluate your algorithms and models and check them for possible unfairness.
Below, we list of some of the tools and resources that might be helpful in combating AI bias:
- FairML is a toolset written in Python. Using FairML, you can audit your predictive machine learning models for bias and fairness. This tool quantifies the relative predictive dependence of an ML model by using four input ranking algorithms, thus assessing the model’s fairness.
- AI Fairness 360 is an open-source library by IBM that can help you detect, examine, and mitigate discrimination bias in your ML models. Currently, the library contains over 70 metrics of ML algorithm fairness and 10 state-of-the-art algorithms for mitigating AI bias.
- SHapley Additive exPlanations (SHAP) is an approach for explaining an ML model’s outputs by connecting game theory and local explanations. This approach unifies a set of seven methods for understanding and explaining decisions made by ML models, including such methods as LIME, DeepLIFT, and Tree Interpreter.
- The Algorithmic Justice League is a community that works on creating bias catalogues and audits existing ML algorithms. The organization also collects reports on coded biases detected in AI solutions.
Using these tools and libraries, you can analyze the algorithms implemented in your AI solution and make eliminating possible biases and unfairness a less challenging task.
Read also
Emotion Recognition in Images and Video: Challenges and Solutions
Discover how AI can interpret human emotions through facial expressions in images and video. This article explores the key challenges in emotion recognition technology and offers practical solutions for overcoming them.
Conclusion
AI and bias are closely related. A biased AI model systematically makes the same faulty predictions or judgements. Bias mostly occurs due to the use of biased data or algorithms. In the first case, the issue is in the quality of the data used for training, while in the second case, it’s more about the way this data is processed by the algorithm.
AI bias can originate from either statistical flaws or cognitive factors. The most common examples of bias introduced by humans are based on societal stereotypes and discrimination based on factors such as race, gender, and age.
With discrimination being one of the main dangers posed by machine learning bias, the key to fixing it is making the AI algorithms more transparent and fair. However, keep in mind that the definition of fairness may vary depending on the use case.
There’s no way to eliminate bias from an AI solution altogether. However, you can reduce the level of bias and improve the fairness of an AI model by using more diverse data, training your models on different sets of data, cross-checking your algorithms, implementing AI policing algorithms, and using special tools for auditing AI fairness.
As AI software development company, we have a team of experienced AI developers who can do everything from solving basic machine learning tasks to building complex AI solutions.
Unlock the full potential of AI for your business
Build cutting-edge AI solutions that drive results. Partner with Apriorit’s skilled developers to make it happen!
Have a question?
Ask our expert!
R&D Delivery Manager


