 Skip to main content
Skip to main content
Building a microservice-based architecture helps you deliver a scalable, flexible, and agile solution. However, this approach complicates development, as you have to set up the connections between all modules and databases.
We already discussed the importance of using Python dependency management tools to effectively manage and coordinate dependencies of each service in a microservices architecture. This time, we tackle another challenge: ensuring proper communications between microservices. Some transactions have to interact with databases within different microservices, and you need to make sure such transactions work flawlessly.
Also, you need to be able to roll back any changes that may lead to an error. By doing this, you can prevent crashes and outages that can happen when a transaction is partially finished to an unknown overall state. If an issue occurs, you can’t know exactly how far along the process was before the transaction was interrupted and what information was already changed.
In this article, we explore the atomicity of database transactions in microservices. We also describe two ways of keeping transactions atomic and provide an example application. This article will be helpful for Python developers who plan to create a microservice-based application.
Contents:
The challenge of keeping microservice transactions atomic
When working with databases, it’s crucial to make sure that database operations satisfy ACID properties. ACID — which stands for atomicity, consistency, isolation, and durability — is a set of properties for database transactions that ensure data validity despite possible errors, power outages, and other troubles.
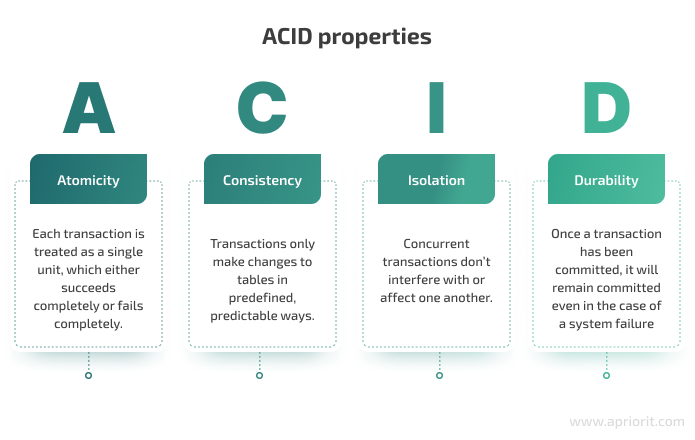
In this article, we focus on challenges of atomicity in microservices.
In database systems, atomicity is a transaction property that means all steps in the transaction must be successful. If even one step fails, then all previously completed steps should be rolled back. Therefore, an operation is considered atomic if it either happens completely or doesn’t happen at all.
Ensuring ACID principles in a monolithic solution is pretty straightforward because such an architecture allows for creating a local transaction in a database, and this transaction interacts with lots of tables within the database. However, in a microservice-based solution, transactions might have to interact with multiple databases within different services. Such transactions are distributed, and it takes some effort to keep them atomic.
The key atomicity problem in microservices is that a transaction can consist of multiple local transactions handled by different microservices. So if one of the local transactions fails, you have to find a way to roll back the successful transactions that were previously completed.
It’s easiest to explore technical nuances using practical examples. In the following section, we develop an architecture for a microservice-based application. We also define a type of transaction that’s challenging to keep atomic and offer two methods to do so.
Planning to launch a microservice-based project?
Ensure a thoughtful architecture for your solution by delegating development tasks to Apriorit’s experts. Make your software scalable, flexible, and agile.
Addressing atomicity issues based on the example of an e-commerce application
Let’s create a simple application that consists of several microservices. Say we want to build a back end for an e-commerce application. In order to function, this online shop needs functionality for managing products, users, and orders.
Now, we need to distribute responsibilities between microservices according to the defined functionalities. To isolate microservices from each other, we’ll create a separate database for each microservice. Note that in real life, creating separate databases is too complicated and time-consuming, so it’s essential to use the shared database pattern.
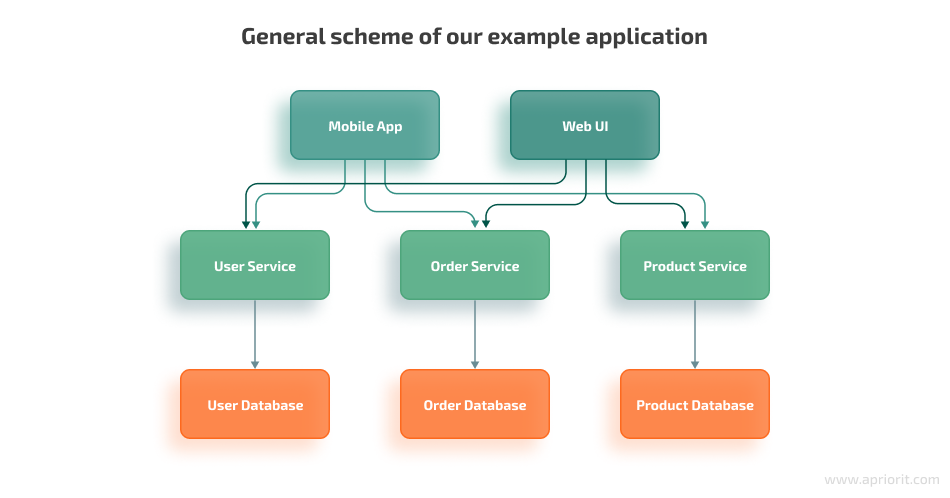
Let’s also define the functionalities for every service:
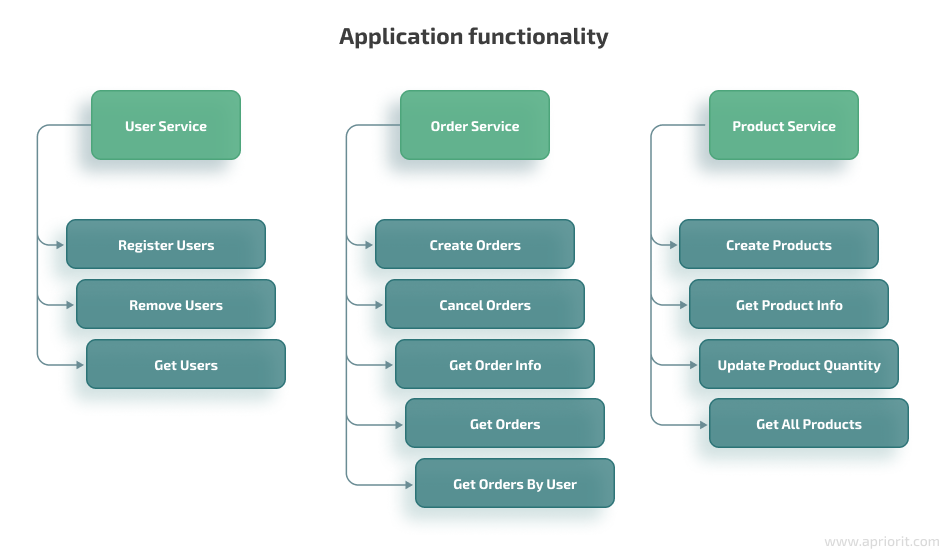
Each database of each microservice will contain only one table:

This way, the orders table depends on the data stored in the users and products tables. To implement transactions, we can’t just add two external keys in the products table, as we would do for a solution with a monolithic architecture.
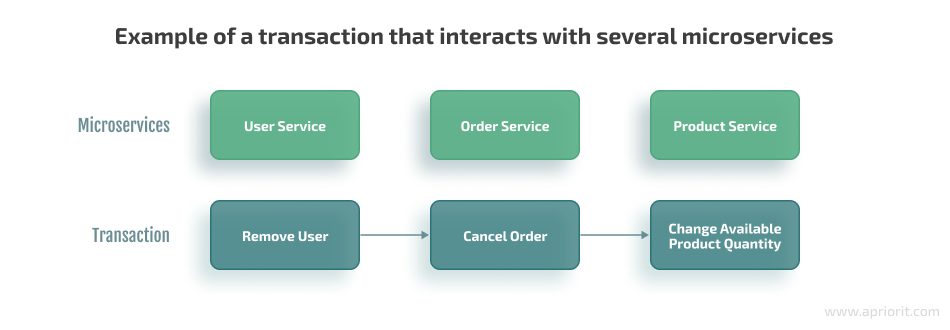
In our case, issues can appear only in two types of transactions:
- Canceling an order because such a transaction has to interact with tables in the Order and Product microservices
- Removing a user because this transaction has to interact with tables in all three microservices
All other transactions, such as adding a new user or updating the number of products, are handled within one microservice.
Let’s explore in detail how to solve an atomicity problem in microservices and create transactions for removing a user that work flawlessly. To do this, we also have to cancel unexecuted orders of a user we remove, so we’ll tackle both issues sequentially.
What exactly is the problem with removing a user?
Besides the actual removal of the user, we also have to cancel the user’s orders and update the number of available products in the catalog according to the ACID principle. If we remove a user but don’t update the number of products, we will need to first roll back the user removal in order to fix that mistake. And this means rolling back changes across different databases in different isolated microservices.
The transaction shouldn’t change data only partially. If something goes wrong at any stage, we must revert all changes made by the transaction. In a monolithic architecture, we can simply tell the database to remove dependent records in other tables in a cascading order. In a microservice-based architecture, we have several databases, so we need to come up with another solution.
There are several ways to implement atomic operations between microservices. A few popular ones are:
- Using HTTP
- Creating a task queue
- Implementing a remote procedure call
From our experience, the HTTP method is perfect for ensuring simple interactions when we need to help one microservice contact another. But when we want one microservice to send the same information to several other microservices simultaneously, it’s more convenient to use task and message queues.
Let’s explore the first two methods in detail, starting with HTTP.
Below, we describe the general concepts for both methods and list the steps we take to ensure atomicity of transactions. You can check the code of the application we developed in Apriorit’s GitHub repository.
Read also
How to Accelerate Microservices Development: A Practical Guide to Applying Code Generation
Discover a helpful method of speeding up the process of creating a microservice-based solution. Find out a practical example of quickly connecting gRPC microservices to GraphQL and developing two simple services using proto3 syntax.

Method 1: Ensuring transaction atomicity using HTTP
HTTP is a widely used data transfer protocol based on a client-server structure. The client creates a request and sends it to the server, which processes this request, generates a response, and sends it back to the client. This technology is mostly used for interactions between the server and the end user, but it can also be used for interactions between microservices.
For our application, we’re going to use available API endpoints to implement chain communications between microservices and remove records from tables. We are going to save changes in local databases only if we receive a confirmation of the HTTP request’s successful execution. Otherwise, we’ll roll back all the changes.
Let’s explore the algorithm in detail:
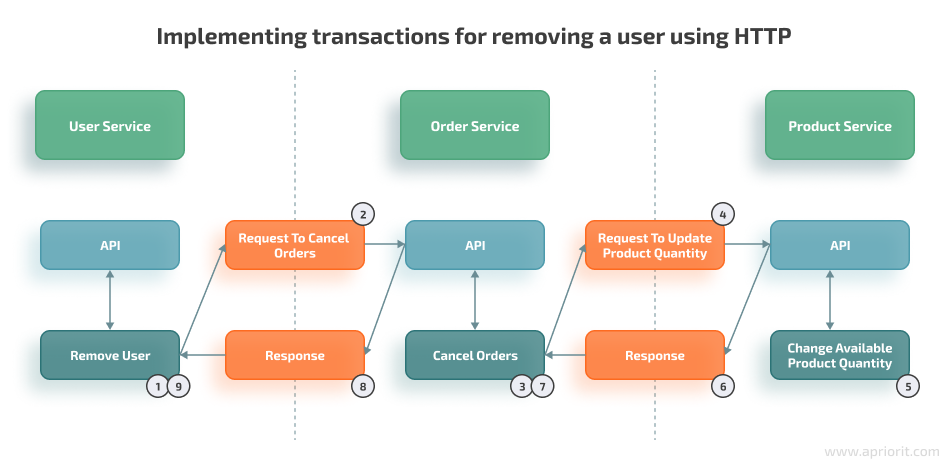
Here’s an explanation of each step of the algorithm:
- Remove a user without saving changes.
- Send an HTTP request for canceling user orders.
- Cancel user orders without saving changes.
- Send an HTTP request for increasing the number of available products.
- Increase the number of available products and save the changes for this step.
- If step 5 was executed successfully, we receive the “OK” status. Otherwise, we receive an error.
- If we receive “OK,” then save changes made in step 3. If we receive an error, roll back orders removal (step 3) and receive an error that orders can’t be canceled.
- If step 7 was executed successfully, we receive the “OK” status, meaning that orders were successfully canceled and we can finish the user removal process. Otherwise, we receive an error.
- If we receive an error, we roll back user removal (step 1) and receive an error that the user can’t be removed. Otherwise, we save changes made during step 1.
Thus, if there’s an error during any step of the transaction, we roll back the changes in local databases introduced in previous steps.
This HTTP approach has the following benefits:
- Ensuring requests and replies is easy
- No need to use an intermediate broker
However, there are also some drawbacks:
- This approach usually only supports requests and replies. Other interaction patterns like notifications, request and async responses, publish and subscribe, and publish and async responses aren’t supported.
- The client and the service must be available for the duration of the interaction.
Now, let’s explore a second way to implement the same transactions.
Related project
Building a Microservices SaaS Solution for Property Management
Uncover the challenging project of replacing the monolithic platform with a microservice-based platform. Read on to explore the details of how Apriorit’s development efforts helped our client increase the flexibility of their platform’s architecture and simplify the process of adding new features to it.
Method 2: Ensuring transaction atomicity using task queues
Let’s define the key terms we use in this section before moving to our example:
A message queue is a form of asynchronous service-to-service communication that’s often used in serverless and microservices architectures to store messages until they’re processed and deleted. Basically, a message queue is a mechanism for sharing information between processes, threads, and systems.
A task queue is more complicated than a message queue, as it’s a service designed for asynchronous work. A task queue receives tasks with related data, runs them, and delivers the results, telling us whether tasks were completed.
To implement a task queue, we’ll need a message broker and storage to store the results of accomplished tasks.
A message broker is similar to the postal service: when you put a letter in a mailbox, you can be sure the mail carrier will eventually deliver your letter to the receiver. In our case, a message broker acts as both the mailbox and mail carrier. The only difference is that a message broker doesn’t work with paper. Instead, it receives, stores, and sends messages as binary blocks of data.
To describe the process of message exchange, we use the following terms:
- Queue — a message buffer
- Producer — a program that sends messages to the queue
- Consumer — a program that receives messages from the queue
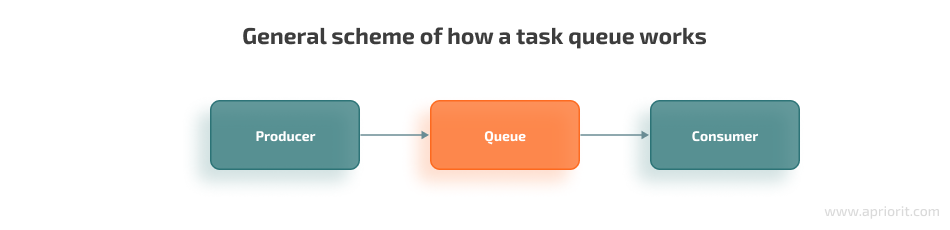
Usually, message brokers offer a variety of tools for ensuring different types of interactions between producers and consumers. Also, there are various low-level frameworks like Pika and high-level ones like Celery that make using brokers more convenient.
In our case of removing a user, we’ll need to ensure the message exchange between microservices with the opportunity to receive the execution status and result from the consumer. For such a task, we’re going to use Celery, since it will help us quickly and easily create task queues. Here’s how we do it:
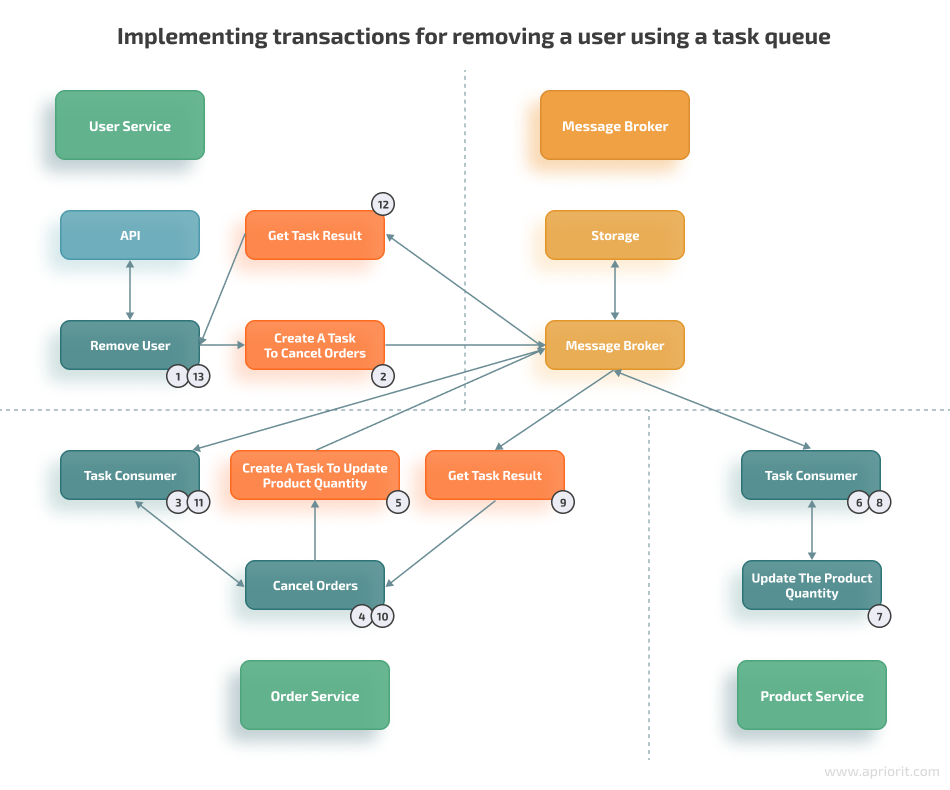
Here’s the explanation of each step:
- Remove a user without saving changes.
- Create a task for canceling user orders.
- A task consumer receives the task.
- Cancel user orders without saving changes.
- Create a task for increasing the number of available products.
- A task consumer receives the task.
- Increase the number of available products and save the changes.
- If step 7 was executed successfully, receive the “OK” status. Otherwise, receive an error.
- Receive the results of the task for increasing the number of available products.
- If the task wasn’t completed successfully, roll back the order removal and receive an error.
- If step 10 was executed successfully, receive the “OK” status. Otherwise, receive an error.
- Receive the results of the task for canceling user orders.
- If we receive an error, roll back the client removal and receive an error. Otherwise, save changes.
This approach has the following benefits:
- Better availability of services thanks to lose runtime coupling achieved by decoupling the message sender from the consumer
- Message broker buffers messages until the consumer is able to process them
- Support for a variety of communication patterns including request and reply, notifications, request and async response, publish and subscribe, publish and async response, etc.
The main drawback of using task queues is that it adds complexity to the message broker, which must be highly available.
So just like with the HTTP method, we managed to achieve atomicity in our database transactions using task queues. You can find the full code for this application example on Apriorit’s GitHub page.
Conclusion
Ensuring atomic interservice communications in microservice databases is vital to make your software work efficiently and achieve a proper user experience. To do this, make sure to implement ACID properties in your solution. Also, consider exploring our extended guide on accelerating microservices development using code generation.
How to keep your database transactions atomic depends on the type, size, and other specifics of your solution. At Apriorit, we have hands-on experience building microservice-based software and creating efficient transactions. Our dedicated development teams are ready to assist with building an efficient and reliable product.
Ready to deliver top-notch software?
Start using microservices and Python to the fullest and deliver a reliable solution with the help of Apriorit professional developers!
Have a question?
Ask our expert!
VP of Engineering


