 Skip to main content
Skip to main content
Key takeaways:
- Nearly 90% of organizations use artificial intelligence (AI), but only 6% see significant bottom-line results.
- Organizations seeing the best results use AI to augment their data analytics lifecycle.
- To enhance your big data analytics with AI, start narrow and then scale: assess readiness, validate with focused pilots, productionize, and iterate.
- Data quality is the most common barrier. No matter how advanced your model is, it won’t compensate for fragmented, inconsistent, or inaccessible data.
- To avoid costly rework after discovering a security or compliance issue later in the SDLC, plan for proper access controls, audit trails, and monitoring from the start.
Most organizations have already started using AI for data analysis. Far fewer have figured out how to make it work at scale.
Data quality problems, integration complexity, talent shortages, and lack of clear governance rules create friction that no algorithm can eliminate on its own.
If you are a CTO or an engineering leader challenged with modernizing your big data analytics workflows or platforms, this article is for you. We analyze AI’s real role in data analytics, including cases where AI adds the most value across the analytics lifecycle. You’ll also get a practical roadmap for building secure and efficient AI-driven analytics pipelines coupled with a breakdown of key challenges your team is likely to face along the way.
Contents:
- The state of AI in big data analytics
- Use cases for AI in big data analytics
- Where AI fits in the data analytics lifecycle
- A practical roadmap for building AI-driven data analytics pipelines
- Tools and technologies for AI-powered data analytics
- AI adoption challenges for big data projects (and how to address them)
- Get the most out of your data with Apriorit
The state of AI in big data analytics
The technology seems to be maturing faster than organizations can absorb it.
Enterprises embrace AI for day-to-day operations. McKinsey’s 2025 State of AI survey shows that 88% of organizations now use AI in at least one business function, up 10% from a year earlier. Yet only 6% of respondents report seeing a bottom-line contribution of 5% or more from AI adoption.
The analytics function itself is undergoing a structural shift. Traditional dashboards — once the primary interface between business users and enterprise data — are reaching their limits. Organizations accumulate thousands of unused or stale dashboards that are used once and abandoned.
Yet Gartner predicts that by 2027, 75% of new analytics content will rely on generative AI (GenAI) for enhanced contextual intelligence. This will allow analysts to move beyond simply visualizing data and enable so-called “perceptive analytics.” Powered by GenAI, such analytics systems will actively monitor conditions, detect anomalies, and recommend further actions.
And the interface is gradually shifting from pull, where a user has to request a specific report, to push, where the AI system proactively surfaces relevant insights. This change is already visible in how organizations interact with their data platforms today.
AI agents — systems capable of planning and executing multi-step workflows autonomously — represent the next step in the evolution of data analytics. McKinsey’s 2025 State of AI survey found that 62% of organizations were already experimenting with agents, though most deployments remained confined to one or two functions, typically IT and knowledge management.
Enterprises are more careful with this technology. As Gartner’s data shows, in 2025, less than 5% of enterprises used task-specific AI agents. But this number is expected to grow fast, reaching 40% by the end of 2026.
So, why do enterprises pursue AI for big data analytics?
And, more importantly, why should you?
On the surface, we see that the general benefits of AI in data analytics are no different from what this technology offers across other domains:
- It detects unobvious patterns, correlations, and anomalies that humans and traditional statistical methods often miss
- It automates repetitive low-value work that once consumed the majority of analysts’ time
The most important change AI brings to analytics is, in fact, who can access data insights.
Over half of analytics and AI leaders surveyed by Gartner say they are already using AI tools for automated insights and natural language queries.
This means that complex big data analytics is now accessible to regular business users.
Instead of writing SQL or navigating complex dashboards, users can ask questions in plain language and receive comprehensive reports directly within their existing workflows, whether via email, chat, or a specific business application.
Thus, it comes as no surprise that technical leaders are trying to understand where and how to use AI for data analytics.
Want to build a scalable solution for growing data volumes?
Let Apriorit help you turn complex data streams into actionable insights that support confident business decisions.
Use cases for AI in big data analytics
AI-powered analytics features are now becoming baseline capabilities embedded directly in data platforms. The most common AI use cases in data analytics include:
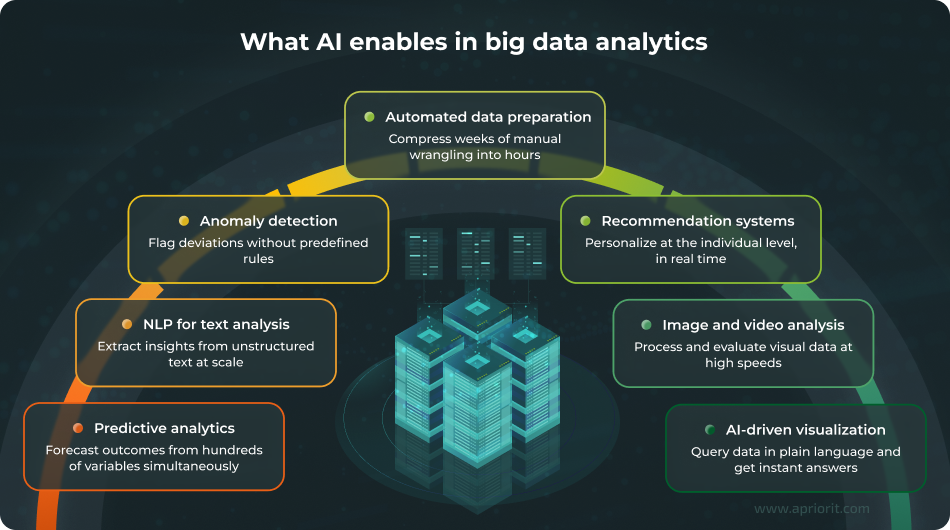
Predictive analytics — Traditional forecasting relied on historical averages and basic trend analysis. AI-powered predictive models process hundreds of variables simultaneously, surfacing otherwise undetectable non-linear relationships and interactions.
AI enables continuous predictions that update as new data arrives. In practice, this means healthcare systems can better predict patient readmission risk before discharge, while financial institutions can score credit applications in milliseconds rather than days.
Natural language processing for text analysis — Unstructured text like customer reviews, support tickets, contracts, and emails used to sit in archives, where they were invisible to most analysts. The most common way to get similar data in a structured way was to run a costly, time-consuming survey with a highly limited scope, often involving only hundreds or thousands of respondents.
With NLP, modern models can process millions of records of unstructured data to extract sentiment, classify topics, and identify entities at scale. This gives organizations the power to anticipate and address issues such as legal risks and formal complaints before they occur.
Anomaly detection — Rule-based alerts catch known problems. But what about problems no one was expecting?
When enhanced with AI, data analytics systems can clearly distinguish deviations from the norm and flag suspicious events or processes. This functionality is widely adopted for detecting fraudulent activities in finance, equipment degradation in manufacturing, and adversarial behaviors in cybersecurity.
Automated data preparation — Prior to AI adoption, data scientists had to spend 60–80% of their time cleaning and preparing unstructured data before any analysis could begin. AI automates much of this work by standardizing formats, resolving entity matches, filling gaps, and flagging quality issues.
While allowing for compressing weeks of manual data processing into hours of supervised automation, this doesn’t fully eliminate the need for human judgment. Quality control and decision-making still require human expertise and a deeper understanding of business and industry context than current AI systems possess.
Recommendation systems — Granular personalization at scale was hard to achieve before ML. Previously, most recommendations were based on major factors like age, gender, and geolocation.
With AI in play, recommendation engines can offer more precise personalization, suggesting products and services based on user behavior, individual preferences, and real-time contextual data.
Image and video analysis — Computer vision extends analytics beyond structured data into previously off-limits territory. If it can be “seen” by an AI model, it can now be analyzed.
Capabilities of AI models range from classifying images and detecting separate objects to reading and processing large documents and analyzing video feeds. More importantly, these models can analyze visual data at scale while maintaining high accuracy.
In practice, this can look like insurers using photos from car accidents to assess damage or manufacturers enhancing their quality control systems to identify potential defects on assembly lines.
AI-driven data visualization — Dashboards used to require analysts to anticipate which views users would most likely need. And if users wanted a different cut of the data, they had to submit a request and wait for it to be processed.
AI-powered visualization tools flip this model. These days, most interactions with large databases no longer require advanced SQL skills. When properly trained, an AI system can also suggest related metrics, highlight anomalies, or explain what’s driving the numbers on a particular dashboard.
Yet efficient use of AI in big data analytics requires more than choosing the right algorithms. You need to figure out exactly where AI can add the most value for your business.
Where AI fits in the data analytics lifecycle
Most data analytics teams follow a more or less standard lifecycle: ingest data, store it, prepare it for analysis, build models or run queries, deploy insights to production, and monitor everything to ensure it keeps working.
AI impacts almost every stage of this cycle, creating or enhancing a number of analytics capabilities. Let’s take a closer look.
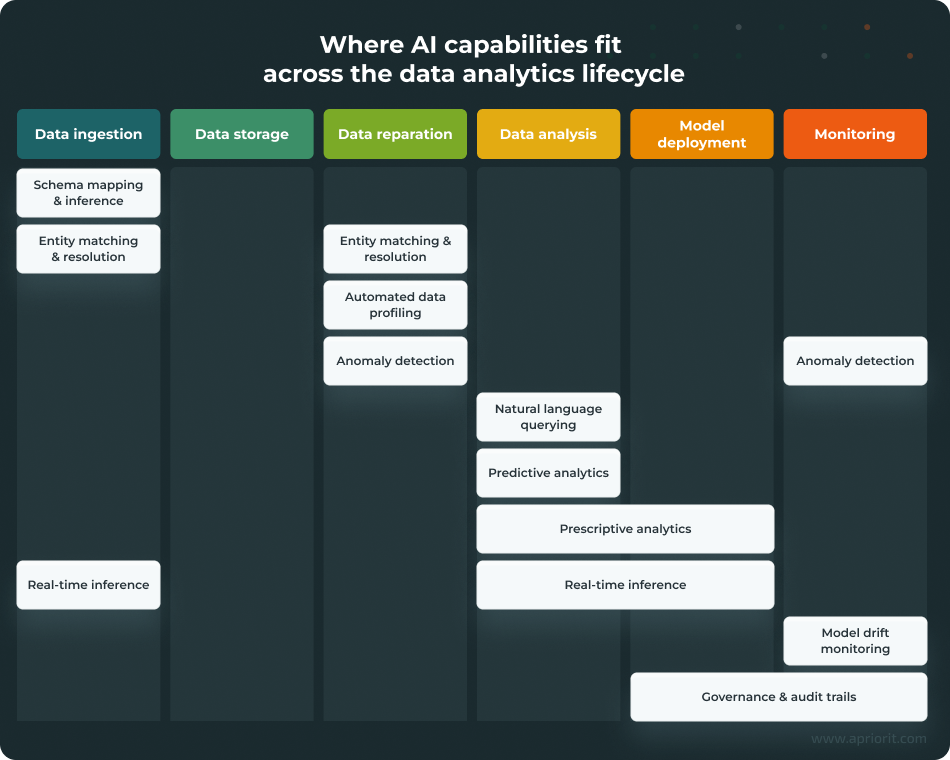
Data ingestion and integration capabilities
Two capabilities matter most at the point where data enters your environment:
- Schema mapping and inference
- Entity matching and resolution
Schema mapping previously required manual configuration for every new data source. ML models can now infer mappings automatically based on column names, data types, and sample values. They’re not perfect and can make mistakes, but they can handle obvious cases pretty well and flag ambiguities for human review.
Entity matching helps handle cases when rule-based matching quickly breaks down — for example, when a customer appears as John Smith in one system and J. Smith in another. With ML-powered entity matching and resolution, probabilistic matching models weigh multiple signals:
- Name similarity
- Address overlap
- Behavioral patterns
They then use all this data to resolve entities with far higher accuracy than deterministic rules.
Data quality and preparation capabilities
At this stage, AI is mostly used for data profiling and anomaly detection.
Automated profiling tools can save analysts’ time by scanning large datasets, surfacing quality issues — missing values, outliers, format inconsistencies, duplicate records — and flagging potential issues for human review.
Beyond one-time profiling, AI models can detect anomalies by learning what normal looks like for a given dataset and alerting teams when new data deviates from established patterns.
Typically, anomaly detection appears at the data preparation stage. However, it can also reappear later in the lifecycle, even after the model is in production, when there’s a need to monitor its inputs and outputs.
Data analysis and BI capabilities
Large language models (LLMs) enable natural language querying, which is necessary to translate user intent from plain language into SQL or other structured queries your database can understand. After processing these queries, LLMs also format the results so they’re easy for business users to understand.
The analytics team will most likely still need to work with SQL queries as well, specifically for high-precision tasks and in strictly regulated fields. In such cases, it’s crucial to exclude the risk of incorrect or fabricated outputs generated by LLMs and make sure that all database queries are transparent and auditable.
Another important capability of LLMs is predictive analytics. Rather than waiting for someone to ask the right question, AI models can continuously scan data and flag anomalies, trends, and correlations that require human attention.
Prescriptive analytics goes even further. It uses AI models to determine the necessary next steps based on previously surfaced proactive insights.
Read also
AI for Demand Forecasting: Benefits, Use Cases, and Implementation Tips
See how you can anticipate trends, balance supply and demand, and make proactive, data-backed decisions with AI.

Operational capabilities
To perform properly in production, AI models require well-established, stable infrastructure. Operational capabilities such as real-time inference, model drift monitoring, and governance are integral to this infrastructure.
This is the part where combining AI and big data analytics directly affects operations.
Real-time inference spans multiple lifecycle stages: data ingestion, analysis, and model deployment. As a result, development teams often have to deal with additional architectural complexity and be highly selective about the use cases they enable real-time inference for.
Continuous model drift monitoring ensures the model’s performance doesn’t degrade when the data it was initially trained on no longer reflects reality. This often requires tracking prediction accuracy against actual outcomes, watching input data distributions for unexpected shifts, and setting up alerts when performance degrades beyond acceptable thresholds.
Last but not least, every AI-powered system needs special governance.
Regulatory requirements across industries and regions increasingly demand that AI-enhanced systems be transparent and exhibit some level of explainability. This requirement applies to everything from model design to training data selection and security to output generation.
We’ll cover these operational aspects in greater detail in the adoption challenges section. For now, let’s see how you can plan the practical implementation of these capabilities.
Read also
Data Analytics in the Automotive Industry: Use Cases, Trends, and Challenges
Explore practical ways to apply data analytics in automotive projects to boost efficiency, reduce downtime, and gain a competitive advantage.

A practical roadmap for building AI-driven data analytics pipelines
There’s no universal playbook for AI implementation in data analytics. Every organization starts with its own parameters for data maturity, technical capabilities, and business priorities. Yet the underlying workflow remains pretty much the same and consists of three main stages.
Stage 1: Assess your starting point
Before selecting tools or building models, you need an honest inventory of where you stand across three major domains:
- Data readiness
- Infrastructure readiness
- Cybersecurity posture
Let’s take a closer look.
Organizations assessing their data readiness often discover that their data is highly fragmented and scattered across CRM systems, ERP platforms, spreadsheets, and databases that don’t communicate with one another.
So, the first thing to do is to answer these questions:
- Where does your data actually live?
- How much of it is accessible, documented, and trustworthy?
Have your team create a data quality scorecard that rates each source on completeness, accuracy, consistency, and timeliness. This will help you prevent expensive data-related surprises later.
At the infrastructure level, most existing systems can’t support AI-powered workloads by default. You need to evaluate your current storage and compute capacities and how you’ll expand them before planning to enhance your system with AI features.
Another important aspect is data security. If your system processes sensitive data or personally identifiable information (PII), it’s crucial to plan how your AI system will work with that data. This includes limiting access to both the data and the model, enforcing appropriate encryption and anonymization workflows, securing integration points, or even deploying your model on-premises. Your team needs to understand the exposure surface and plan all this before they start building anything.
This phase typically takes eight to twelve weeks for midsize organizations, but may take even longer for enterprises with complex data estates.
Stage 2: Pilot and validate
Start with one or two narrowly scoped pilots designed to quickly validate and demonstrate the value of enhancing big data analytics with AI.
The ideal pilot should have:
- A clearly defined business problem it helps to solve
- Enough data of reasonable quality available
- Specific and measurable success criteria
Keep in mind that you can’t demonstrate improvement without knowing where you started, so make sure to establish baselines first. And keep your timelines tight. Pilots that drag on for six months lose momentum and executive attention.
I’ve seen teams and developers skip baselines to move faster and then spend months arguing about whether anything actually improved. That’s a much slower way to go.
Vadim Nevidomy, Head of AI at Apriorit
Aim to get the first results in 10 to 16 weeks. If a pilot can’t show meaningful progress within this timeframe, you may need to narrow its scope.
Stage 3: Productionize and iterate
Once you have validated your idea with a successful pilot, it’s time to move to production. This requires enhancing your system with several capabilities:
- Proper error handling
- Monitoring and alerting
- Fallback mechanisms
- Retraining workflows
You’ll also need to ensure proper pipeline security by protecting training data from unauthorized access, controlling who can modify models, encrypting data in transit and at rest, and maintaining audit trails for compliance. AI systems often process sensitive data and influence high-stakes decisions, and you need to treat their security accordingly.
To address aspects like model performance and fairness, data lineage, access controls, and incident response procedures, make sure to establish appropriate governance frameworks.
You should also monitor model behavior and input data distributions. Set up alerts to immediately learn if your model’s performance degrades beyond acceptable thresholds so that your team can retrain the model in a timely manner and thus eliminate potential model drift.
Building feedback loops will let your business users flag predictions that don’t match reality. This will help to ensure that your AI system keeps improving over time by learning from real-world cases.
While planning where and how to integrate AI into your data analytics system, your team will also need to choose the right tools and technologies. Let’s take a look at some common options.
Read also
How to Use Big Data in FinTech: Benefits, Challenges, Implementation
Strengthen your FinTech products by applying big data analytics to uncover hidden patterns, reduce operational risks, and enhance the customer experience.

Tools and technologies for AI-powered data analytics
Below, we go over some of the most common categories of tools and technologies that your team may need to work with while implementing your AI-powered data analytics system.
Big data platforms
Apache Spark remains the dominant framework for large-scale data processing, offering both batch and streaming capabilities with native ML libraries. Apache Kafka handles real-time data ingestion and event streaming, which are essential for cases where insights need to arrive in near real-time.
For latency-sensitive streaming workloads, Apache Flink offers an alternative to Spark Streaming — true event-by-event processing rather than micro-batching, which matters when milliseconds count.
For pipeline orchestration, Apache Airflow remains the standard for scheduling and managing complex data workflows. At the storage layer, open table formats such as Apache Iceberg and Apache Hudi enable lakehouse architectures that unify batch and streaming data. ClickHouse offers a column-oriented alternative optimized for fast analytical queries at scale.
Other tools worth considering include Apache Hadoop (HDFS) and Delta Lake.
These open-source foundations underpin most enterprise data architectures, whether self-managed or consumed as managed services through cloud providers.
Cloud data platforms
It’s getting harder to draw a clear line between a data platform and an AI platform. The major cloud providers now offer unified platforms that combine storage, compute, and AI capabilities in a single environment.
Google BigQuery, Snowflake, and Databricks Lakehouse have emerged as leading options, each with different architectural philosophies.
BigQuery and Snowflake separate storage and compute for flexible scaling. Databricks unifies data lakes and warehouses with tight Spark integration. All three now embed AI and ML features directly, from built-in ML model training to natural language querying.
Vector databases have become essential infrastructure for AI-powered analytics — particularly for RAG architectures and semantic search. Pinecone and Weaviate offer purpose-built managed options, while pgvector extends PostgreSQL for teams that prefer to keep embeddings alongside relational data.
ML frameworks
TensorFlow and PyTorch are two of the best-known deep learning frameworks.
For transformer models and LLMs, the Hugging Face ecosystem has become a de facto standard. It offers pre-trained models, fine-tuning workflows, and model hosting and is often the fastest path from prototype to production, especially for NLP-heavy analytics use cases.
For teams working within the Python ecosystem, scikit-learn remains the go-to for classical ML tasks that don’t require neural networks, such as classification, regression, and clustering.
Spark MLlib offers distributed ML for organizations already invested in Spark infrastructure, which is useful for training models on datasets that are too large for single-machine processing.
AI-driven BI and analytics tools
Traditional BI platforms like Tableau and Power BI have added AI features for natural language queries, automated insights, and anomaly detection. Microsoft’s Copilot integration with Power BI and Salesforce’s Tableau GPT represent the current push to embed generative AI directly into analytics workflows.
A newer generation of tools is represented by solutions like ThoughtSpot and Pyramid Analytics. They take a slightly different approach, positioning AI as core architecture rather than an add-on layer. These platforms emphasize conversational interfaces and autonomous insight generation over traditional dashboard building.
Real-time analytics services
For use cases that heavily depend on data processing speed, real-time ingestion and analysis are crucial.
AWS Kinesis and Amazon Redshift Streaming handle real-time ingestion and analytics within the AWS ecosystem. Google Cloud Dataflow provides unified batch and stream processing. Azure Stream Analytics offers similar capabilities for Microsoft-centric environments.
These services are integral to systems that require high-speed insight generation with limited latency, such as fraud detection, operational monitoring, and IoT analytics.
Which of these tools and technologies to combine for your particular project is a decision that depends on multiple factors: your existing infrastructure, the skills and competencies of your team, data volumes you have to process, as well as latency requirements and budget constraints you have to meet.
And this is only one of the many challenges your team will need to handle — and may need professional assistance with — while working on your AI-powered analytics system.
Want high‑impact insights from complex data?
Make the data you have work for your business! Let Apriorit experts help you design powerful big data pipelines and enhance your analytics workflows with AI.
AI adoption challenges for big data projects (+ Apriorit expert tips on how to address them)
Understanding how AI and big data work together is the easy part. Actually implementing AI-enhanced analytics across messy enterprise environments with legacy systems and siloed data is where most organizations and data analytics products struggle.
Let’s see the most common barriers to AI adoption in big data projects and discuss practical approaches for addressing each.
Data quality and availability
Data is often the biggest constraint for AI-powered analytics.
AI models are only as good as the data they’re trained on. This isn’t a new insight, but the scale of the problem often surprises organizations when they move from proof of concept to production.
Most corporate data remains unstructured, unlabeled, and inaccessible for analysis. While AI can help unlock this data to some extent, it still can’t compensate for missing governance foundations or fragmented data architectures. Furthermore, AI systems may actually amplify some errors rather than simply reflect them.
How to address this:
Invest in the quality of your training data and start with data profiling and observability before building the actual model. Define clear quality metrics: completeness, consistency, timeliness, and accuracy. Then instrument your pipelines to continuously monitor these metrics.
Integration complexity
Most environments where AI-powered analytics need to operate involve a mix of legacy systems, cloud platforms, and specialized tools that weren’t designed to work seamlessly together. This fragmentation creates data silos that undermine AI initiatives from the start.
Whether you’re implementing AI capabilities internally or building them into a product, if the data lives across disconnected systems, your model can’t operate at its full potential.
How to address this:
Integrate modern data platforms that can unify disparate sources and establish clear APIs and data contracts between systems. Prioritize use cases with manageable integration requirements before tackling cross-enterprise initiatives.
Read also
Challenges in AI Adoption and Key Strategies for Managing Risks
Build a sustainable AI strategy by addressing governance, talent, and infrastructure gaps that often hinder enterprise-scale deployment.

Real-time constraints
AI projects with real-time requirements introduce cost and latency constraints that don’t exist in batch analytics.
Unlike batch processing, which runs on a schedule, real-time inference runs continuously. The operational costs of keeping models running 24/7 are a major factor driving the overall growth of the AI inference market. These costs are compounded by expensive hardware and the high computational, memory, and latency requirements of AI models.
Latency, in itself, is a challenge for AI-powered analytics systems. Real-time AI inference requires end-to-end response times measured in milliseconds, and achieving this processing speed often requires rethinking your entire infrastructure architecture.
How to address this:
It’s important to understand your actual latency requirements, as not every real-time use case requires a response time under 10–15 milliseconds. Centralizing processing in cloud data centers introduces network latency that can make real-time use cases impractical. So you should consider hybrid architectures where some inference happens at the edge and some in centralized infrastructure.
Product vendors who rely on real-time inference will also need to decide where to place inference — in their own infrastructure or in the customer’s.
Monitoring drift, bias, and model degradation
Models can inherit and amplify biases from training data and algorithms. And even if you work with a well-balanced dataset, the performance and accuracy of your model can start gradually degrading only days after deployment, even if the model continues to generate seemingly plausible outputs. There are several factors contributing to this, both at the data and concept levels.
Data drift occurs when changes affect the statistical distribution of a model’s input features. Typical examples are shifts in customer demographics, market conditions, and variations in upstream data pipelines.
Concept drift is more subtle, occurring when the relationship between inputs and outputs fundamentally changes, invalidating patterns the model has initially learned. In practice, this can look like a fraud detection system failing to detect a new threat, or a demand forecasting model trained before COVID-19 being unable to predict post-pandemic buying behaviors.
How to address this:
To efficiently prevent model drift and degradation, implement continuous tracking of model performance metrics, input data distributions, and prediction patterns. Set up automated alerts for when performance degrades beyond acceptable thresholds.
Also, make sure to establish clear retraining triggers for your models, be it a fixed schedule or specific triggers for when your monitoring system detects significant model drift.
Product vendors also need to build observability into their product architecture and consider how much visibility to give customers into model health and retraining cycles.
Security governance and compliance
Regulations like the GDPR, laws like the CCPA and HIPAA, and emerging AI-specific legal and regulatory frameworks create overlapping compliance requirements that vary by jurisdiction and industry.
The need to maintain a high level of transparency, auditability, and explainability directly affects what AI models your team can use and how they can use them. Data privacy and security requirements play a special role here, often limiting your team’s access to valuable training data.
For systems that use LLMs, particularly for natural language querying or automated insight generation, additional risks may come from hallucinations and prompt injection attacks. If a model hallucinates, its outputs will be factually wrong even if they sound plausible. Malicious inputs, in turn, can manipulate model behavior or compromise training data.
How to address this:
Make sure to properly document model provenance, training data sources, and known limitations. Implement human-in-the-loop processes for high-stakes decisions and establish clear ownership for AI ethics and compliance.
If you are a data analytics product vendor, make sure to turn governance into an actual product capability. Customers in finance, healthcare, and other regulated sectors will expect built-in audit trails, explainability features, and data lineage tracking.
Talent and skills gap
With the AI market on the rise, it’s challenging to quickly find the right talent, especially for a complex project. And with AI-powered data analytics, you need a team that has expertise in data management, algorithm training, MLOps, architecture design, cybersecurity, and more.
How to address this:
If your project allows for it, you can invest in raising in-house talent. If speed of delivery is among your major priorities, consider delegating your project — or at least the most complex tasks — to a team with niche expertise and relevant experience.
Read also
IT & Software Development Outsourcing in Eastern Europe: Business Guide for 2026
Reduce development costs while maintaining high quality by exploring outsourcing opportunities in Eastern Europe and building efficient, scalable teams.

Get the most out of your data with Apriorit
Building AI-driven analytics capabilities is rarely straightforward. You and your team may have doubts about what to modernize in your data infrastructure and how, from determining the most fitting use cases to integrating new AI capabilities without disrupting systems that already work.
Apriorit can help you tackle these challenges.
Our teams will strengthen your project with deep expertise in cybersecurity, artificial intelligence, and big data engineering — a combination that’s especially valuable when analytics pipelines handle sensitive data or feed into high-stakes decisions.
Here’s how we can help your project:
- Strategy and consulting. Our business analysts and AI engineers will help you identify which parts of your analytics lifecycle will benefit most from AI and build a realistic roadmap to get there.
- Data pipeline engineering. Apriorit’s data engineers will design and build scalable architectures that unify fragmented data sources, support real-time processing, and maintain data quality at scale.
- AI and ML development. Our experienced AI team will design and train your custom model for the tasks your business needs most. We’ll also help you integrate your new AI system into existing infrastructure while preserving its stability, security, and performance.
- Security architecture. Apriorit will ensure that your project has appropriate mechanisms to protect training data, secure inference endpoints, implement access controls, and ensure compliance with industry regulations. We follow secure SDLC principles in every project we work on, building security into every stage of the SDLC from the start.
We can work as an extension of your in-house team or take on the entire project for you. With several engagement models available, you can make our partnership work exactly the way that best suits your business.
Unsure how to start with AI?
Whether you’re evaluating how AI can enhance your big data analytics or struggling to move from proof of concept to production, reach out to discuss details with our experts!
FAQ
How does AI improve data quality at scale?
<p>The main constraint for maintaining high data quality at scale is the speed of data processing and analysis. AI helps eliminate this constraint by automating dataset scanning. This allows for fast discovery and flagging of data-related issues that human analysts would have spent weeks looking for.</p>
<p>Common examples of data issues you can find and solve with AI include:</p>
<ul><li>Missing values and incomplete records</li>
<li>Format inconsistencies across sources</li>
<li>Duplicate entries and entity conflicts</li>
<li>Outliers that signal upstream problems</li></ul>
<p>None of this eliminates the need for human judgment of edge cases. But it compresses the effort required to maintain quality across large, complex environments.</p>
Does AI analytics require massive data volumes?
<p>Not necessarily. The quality of your data matters more than the actual volume of your dataset.</p>
<p>Even with modest datasets, you can still use AI to enhance data analytics processes. To address a lack of relevant data, your team can use data augmentation, transfer learning, or few-shot learning techniques.</p>
<p>How much data you’ll need will depend on the particular use case. Anomaly detection and classification often work well with smaller datasets, while training custom large language models or recommendation engines typically requires substantially more data.</p>
<p>Reach out to us to discuss the parameters of a dataset that will be suitable for your project and ways Apriorit can help your team build it.</p>
What governance is needed to scale AI analytics in regulated industries?
<p>Sectors such as finance, healthcare, and insurance often face stricter requirements for explainability, auditability, and data handling. Before scaling AI analytics, you’ll typically need several foundations in place:</p>
<ul><li><b>Data lineage</b>. Your team needs to know where your data originates from and how it transforms through the pipeline.
<li><b>Access controls</b>. Your system needs role-based permissions that limit who can view, modify, or export sensitive data.</li>
<li><b>Model documentation</b>. Training data sources, known limitations, and validation results should all be properly documented.</li>
<li><b>Audit trails</b>. You need to properly store and manage all records of predictions, the inputs that produced them, and any human overrides.</li>
<li><b>Bias monitoring</b>. Your system must have detection mechanisms to identify when model outputs become biased and violate fairness requirements.</li></ul>
How can I modernize a legacy analytics system without a full rebuild?
<p>Incremental modernization typically works better than a rip-and-replace approach.</p>
<p>You can start by assessing which parts of your current stack create the most friction and address them first. Introduce AI to specific, high-value use cases rather than transforming everything at once. The most likely candidates are data integration, manual preprocessing, or inflexible reporting.</p>
<p>For example, you can add a modern data layer — a lakehouse or a unified platform — that ingests data from legacy sources while enabling new AI workloads. Existing dashboards and reports can stay in place, and your new predictive or automated capabilities can run alongside them.</p>


