 Skip to main content
Skip to main content

Key takeaways:
- LLM‑based systems bring new security challenges 一 like prompt injection, model manipulation, and unsafe agent behavior 一 that traditional testing methods can’t fully address.
- Effective LLM penetration testing uncovers AI‑specific vulnerabilities early, reducing both operational and compliance risks.
- Aligning assessments with legal and regulatory frameworks like MITRE ATLAS, NIST AI RMF, OWASP LLM Top 10, and the EU AI Act ensures your product meets modern compliance and security expectations.
- Applying a shift‑left approach helps teams strengthen architecture, streamline development, and prevent costly issues before deployment.
- With a structured pentesting framework and an experienced partner like Apriorit, software providers can confidently build, validate, and protect LLM‑powered applications.
AI solutions can become a gateway for cybercriminals, who may bypass built-in security mechanisms by cleverly constructing requests containing prompt injection.
However, proper LLM security is achievable.
The key is to understand that LLM-powered solutions require a different approach to security than traditional systems.
In this article, we:
- Discuss how LLM security assessment and penetration testing help teams build reliable, trustworthy AI products
- Highlight key compliance and threat modeling considerations
- Share a structured, step‑by‑step approach to evaluating modern LLM architectures, explaining how agent‑level and RAG‑specific risks should be tested in practice
This text will be helpful for CTOs and AI project leaders who want to protect their products from evolving attack risks and are considering introducing a solid LLM security framework enhanced with pentesting.
Looking to enhance your smart solution’s security?
Make sure to catch and fix all vulnerabilities before deployment. Apriorit’s professionals will conduct rigorous security assessments and pentesting to check your LLM’s defences.
Contents:
- Why do LLMs need a special security approach?
- What business benefits does LLM pentesting bring?
- What guidelines and compliance requirements shape LLM pentesting?
- How to assess LLM security: Apriorit’s framework for planning and executing pentesting
- 1. Define the scope of work and plan testing
- 2. Analyze the LLM system architecture
- 3. Conduct threat modelling
- 4. Choose key attack techniques
- 5. Execute testing
- 6. Run post-test analysis and suggest remediation measures
- How can Apriorit help with LLM penetration testing?
Why do LLMs need a special security approach?
Traditional software systems are based on deterministic logic. This means predictable code execution and vulnerabilities that are related to code errors like buffer overflow and SQL injection.
But adding an LLM component makes the system probabilistic, data-driven, and an opaque black box. Such systems may have unique attack vectors that can’t be fully eliminated with a patch, as in classic software.
Let’s briefly explore the main differences between traditional and LLM-based systems:
- Behavior. Unlike deterministic systems that have predictable inputs and outputs, LLM systems are probabilistic, meaning that outputs depend on statistical patterns in data. Therefore, your team might face risks related to unpredictability, as a model could generate malicious content even without an explicit vulnerability in the code.
- Code and data sources. In building AI solutions, developers use much more third-party code and data than they do when building traditional systems. This significantly increases the risk of attacks on data, such as data poisoning and model extraction.
- Transparency. The black box principle makes it difficult to explain why a model produces a certain output, unlike in traditional systems where developers can audit code relatively easily. Therefore, it’s harder to detect bias, backdoors, and data leaks in LLM systems.
- Attack surface. In traditional systems, developers mostly take care of code, APIs, and security configurations. In LLM systems, they also have to pay attention to prompts, plugins, retrieval-augmented generation (RAG), and multiple agents, which brings new attack risks like prompt injection and jailbreaking.
- Vulnerability fixes. While traditional systems mostly require code patches, improving LLMs may not be 100% effective even with costly fine-tuning, guardrails, and filters. The biggest security implication is that some risks like prompt injection are intrinsic to the nature of LLMs and can’t be completely eliminated.
So, if conventional protection measures are not enough to fully safeguard your LLM product, what’s to be done?
The key to LLM protection is extensive security assessment and penetration testing throughout your product’s software development lifecycle (SDLC).
Due to the black-box nature and rapidly rising security threats, AI protection demands advanced and comprehensive strategies such as secure SDLC principles. With the shift-left security approach, LLM protection is not just an add-on to a certain stage but is built in from the very beginning.
Oleksandr, Test Engineer at Apriorit
In the next section, we explore how LLM pentesting improves your product’s protection during and after development.
Looking to deliver a vulnerability-free LLM-powered product?
Strengthen your defenses with our AI penetration testing services. Let’s uncover weaknesses, fix security issues, and enhance your project protection.
What business benefits does LLM pentesting bring?
Solid protection of LLM-based solutions is essential.
A breach in your product’s cybersecurity may lead to severe financial impact, reputational damage, and operational disruptions.
LLMs now power multiple SaaS tools and development platforms. And, of course, they’re at the heart of chatbots of varying complexity. However, 78% of businesses experienced chatbot security incidents in 2024–2025, showing us that we must keep enhancing their protection. On the bright side, secure chatbots cut operational costs by 34% 一 one more reason to focus on safeguarding your LLMs.
Olya Kolomoets, R&D Delivery Manager at Apriorit
Penetration testing for LLMs is a vital part of a well-structured security assessment and helps organizations of different sizes (and across industries) to gain control over risks early. With strong defences, your team can significantly reduce remediation costs and ensure your AI application remains safe, reliable, and compliant as it evolves.
Let’s see what business advantages you can realistically expect:
- Identification of AI‑specific vulnerabilities and threats. LLM pentesting uncovers threats that traditional testing misses: prompt injection vulnerabilities, adversarial inputs, RAG poisoning, and model extraction attempts. Meanwhile, cyber criminals are constantly experimenting with new LLM‑specific exploits like multilingual prompt attacks, jailbreak chains, and embedding‑space manipulation. Regular pentesting helps development teams stay ahead of attackers by introducing security updates proactively.
- Stronger data protection and compliance readiness. AI pentesting helps identify privacy risks, unsafe data exposure paths, and compliance gaps related to the GDPR, HIPAA, and other AI-related frameworks (NIST AI RMF, ISO 42001, EU AI Act, etc.). This directly reduces the risk of legal penalties, protects against unintentional data leakage, and keeps product development aligned with legal and regulatory demands.
- Proof of security assurance for stakeholders, investors, and clients. Many enterprises now require security validation for any integrated AI system when considering partnership, procurement, or enterprise deployment. An independent LLM pentest can serve as evidence that a product has undergone AI‑specific cybersecurity assessment and enhancement.
- Reduced operational and financial risk. Unsecured AI components can lead to workflow disruption, service downtime, or manipulated outputs that break business logic. By validating robustness against model manipulation or API misuse, LLM pentesting minimizes the probability of operational failures and costly incidents.
- Protection of brand reputation and customer trust. Unexpected or harmful AI outputs can quickly damage a brand’s image. LLM pentesting identifies weaknesses that might cause offensive content generation, misalignment with safety policies, or behavior manipulation.
- Improved architecture and development practices. When used as part of the shift-left security approach, LLM pentesting provides insights into architectural weaknesses. For example, it can help detect unsafe RAG pipelines, insecure prompt construction flows, weak guardrail implementation, and misuse of tools or agents.
Before we showcase a framework for assessing LLM security, let’s discuss relevant frameworks, standards, and laws.
Read also
Applying MITM Tools for Penetration Testing and Cybersecurity Enhancement
Understand how man-in-the-middle testing tools help security teams uncover weaknesses in network communication. Discover practical techniques for identifying vulnerabilities and improving protection against interception attacks.

What guidelines and compliance requirements shape LLM pentesting?
A critical component of maintaining the operational integrity of AI solutions is continuous monitoring of both established and newly identified vulnerabilities. You can find those vulnerabilities (along with compliance requirements) in AI- and cybersecurity-related laws, standards, and frameworks.
At Apriorit, these are our primary references for identifying threats to your AI products:
1. MITRE Adversarial Threat Landscape for Artificial-Intelligence Systems (ATLAS) is a dynamic framework for cataloguing AI-related threats. It informs approaches to analysis and implementation of security assessment and penetration testing strategies. MITRE ATLAS offers an approach organized by tactics and attack and defense methods.
Let’s consider a few examples of how your team can use ATLAS for LLM security:
MITRE ATLAS relevance for LLMs
| Tactic | Techniques | Vulnerabilities/risks | Mitigation examples | Pentest examples |
|---|---|---|---|---|
| Reconnaissance | Searching for public ML artifacts (AML.T0002), Detection of LLM hallucinations (AML.T0037) | Disclosure of model details that can lead to targeted exploits | Controlling access to public repositories | Testing an LLM for bias or weaknesses through public APIs |
| Resource development | Obtaining public ML artifacts (AML.T0000), Preparing ML attack capabilities (AML.T0012) | Compromised tools or datasets containing backdoors | Supply chain verification | Providing infected data for LLM fine-tuning |
| Execution | LLM prompt injection (AML.T0051), Command interpreter abuse (AML.T0018) | Malicious queries that change model behavior | Prompt filtering | Direct/indirect injections causing dangerous LLM responses |
| ML attack preparation | Creating adversarial data (AML.T0024), Training data poisoning (AML.T0014) | Preparing exploits such as poisoned samples | Data validation | Preparing attacks on LLM training sets |
| Exfiltration | Exfiltration via ML inference API (AML.T0029), Data leak through LLM (AML.T0059) | Unauthorized data extraction | Output redaction | Testing prompts encouraging LLM to disclose confidential information |
| Privilege escalation | Excessive autonomy (AML.T0050), Escalation via LLM plugin (AML.T0011) | Autonomous actions leading to privilege escalation | Principle of least privilege | LLM calling unrestricted APIs |
| ML model access | Valid ML accounts (AML.T0035) | Unauthorized model use | Multi-factor authentication | Access to private LLMs |
2. NIST AI Risk Management Framework is one of the most authoritative voluntary frameworks for managing AI risks. For LLMs, the AI Risk Management Framework emphasizes trust risks such as bias, confidential data leaks, adversarial attacks, and disinformation. The playbook offers practical steps for testing GenAI and high-risk LLM security.
3. OWASP Top 10 for Large Language Model Applications is probably the most well-known open-source initiative for understanding and reducing security issues in the application and implementation of generative AI.
OWASP Top 10 for LLM applications describes well-known types of threats that should be considered when implementing LLMs and is updated each year.
4. ISO/IEC. We recommend paying attention to the following standards:
- ISO/IEC 42001:2023 Artificial Intelligence Management System (AIMS) requires continuous improvement and auditing, integrating pentesting into the Plan-Do-Check-Act (PDCA) cycle. It also helps create repeatable test plans, including validation of third-party models and documentation for certification audits.
- ISO/IEC 23894:2023 Guidance on AI Risk Management focuses on a continuous pentesting approach. It also emphasizes mitigation options that help prioritize fixes after vulnerability detection and offers evaluation methodologies — from qualitative (expert review) to quantitative (attack simulation).
- ISO/IEC 42005:2025 AI System Impact Assessment requires systematic testing for social harm (e.g., disinformation through manipulated results), extending classic pentesting to ethical red teaming.
5. The EU Artificial Intelligence Act applies to all products placed on the EU market. For general-purpose AI models, it requires a conformity assessment, including:
- Cybersecurity testing (covering model theft and harmful outputs)
- Public benchmarks and upstream/downstream risk assessment
- Mandatory technical documentation
With these vital details about AI-related frameworks, standards, and laws, let’s move to a practical example of how to strengthen your product’s defenses.
Related project
Developing a GDPR-Compliant AI-Powered LMS for Pharma Employee Training
Discover how our engineers developed an AI-driven learning management system that streamlined pharmaceutical training processes and improved how employees access and interact with training materials.

How to assess LLM security: Apriorit’s framework for planning and executing pentesting
To show you the security assessment process step by step, we’ll consider a basic LLM application architecture.
Here’s a modern LLM application architecture with RAG, focusing on efficiency, responsible AI, and monitoring.
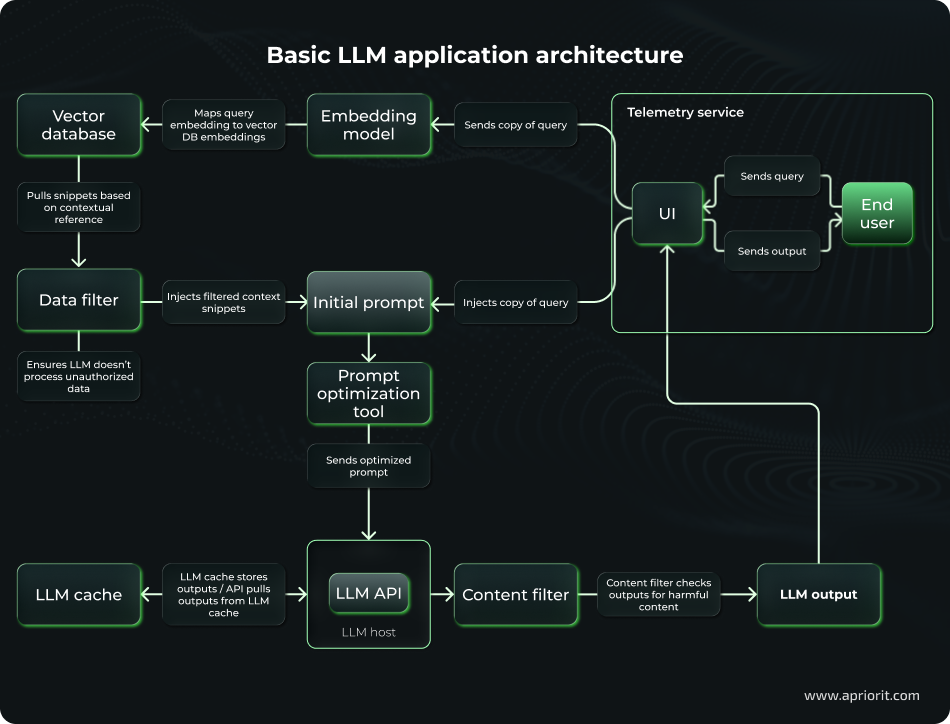
Components of our illustrative LLM solution relate to the following categories:
- User input processing: Converting a query to an embedding, searching for and extracting relevant data fragments from the vector database, passing snippets through a data filter, and injecting them into an initial prompt
- Input enrichment and prompt construction: Filtering context, injecting the original query into an initial prompt, optimizing the prompt, and sending it to the LLM host
- Preparing outputs: Checking cache for stored outputs and extracting them, passing an output through a content filter and scanning it for harmful or offensive content, sending the filtered response back to the user via UI
- Telemetry services: Collecting logs like queries, embeddings, and outputs for monitoring, analytics, and anomaly detection
At Apriorit, we either receive such a diagram from the customer or design it ourselves during the project discovery stage based on the client’s business goals and technical requirements.
With our test LLM architecture in mind, let’s see how to assess its security and plan pentesting.
1. Define the scope of work and plan testing
A structured discovery phase helps your team see the big picture before rushing into development so you don’t waste months building the wrong thing.
At Apriorit, we typically start by analyzing requirements from provided documentation and conducting open-source intelligence. We also communicate with stakeholders to align on essential details:
- Discuss rules of engagement (RoE): black vs white box, allowed testing techniques and tools, measures to protect the environment from harmful testing results.
- Prioritize functionalities by their product impact.
- Approve limits such as request volumes to prevent high costs for denial-of-service simulations.
- Document exceptions like third-party services whose functionality is not directly controlled by a customer.
- Coordinate time frames and expectations for each testing stage.
The key project discovery processes for our test LLM architecture will be the following:
- Create a map of the LLM system’s architectural and functional components, such as model endpoints, vector or RAG repositories, agents, tools, plugins, user interfaces, etc. In our example, we already have the LLM architecture map.
- Identify vulnerability vectors: data flows, APIs, logs, and memory stores.
- Define business context details: sensitive data, compliance requirements (GDPR, HIPAA, etc.), degree of risk according to the Common Vulnerability Scoring System (CVSS).
- Assign baseline scores for potential risks.
- Draw profiles of likely attackers: malicious insiders, external hackers, competitors, etc.
- Set measurable success criteria KPIs (for example, success rate of detected vulnerabilities or component coverage).
- Define functionality to be tested. In our LLM solution, we’ll choose the LLM core (query processing via prompt and LLM host), integrations (API, vector DB, content filter), and deployment environments (dev/QA for white-box and stage/prod for black-box testing).
- Align project requirements with necessary compliance requirements, international standards, and globally recognized security systems like NIST AI RMF for risk mapping, ISO 42001 for governance, and the EU AI Act for GPAI transparency.
- Estimate budget and allocate resources. For example, set a limit of 10,000 tokens for simulations. As for a QA team, for our solution we will include two penetration testing specialists and one AI expert.
- Finalize the scope of work. At this stage, our team explicitly documents the boundaries and depth of testing based on budget, time constraints, and expected deliverables. We also define out-of-scope tasks, clarifying which components and attack surfaces won’t be tested. As a result, we present a clear, structured testing approach with realistic estimates and well‑defined limitations.
2. Analyze the LLM system architecture
The goal of this stage is to collect as many details about your system as possible:
1. Determine how model access is implemented:
- Via a cloud API (OpenAI GPT-4o, Anthropic Claude, Grok API, or Gemini)
- Via on-premises/self-hosted models like Llama-3, Mistral, or local Ollama/vLLM
2. Assess authentication and network controls:
- API keys, OAuth, RBAC
- Firewalls, VPC
3. Check for exposed endpoints, such as RESTful or gRPC.
4. Assess RAG components:
- Analyze vector DB type and data sources like corporate documents, internal APIs, or web crawling results.
- Determine if there is hybrid retrieval (keyword + semantic) or a reranking stage.
5. Analyze the prompt engineering pipeline:
- Break down the initial system prompt and find out whether it contains strict guardrails, role-playing instructions, or few-shot examples.
- Analyze the prompt optimization tool. For example, it could be an LLM-based compressor like LLMLingua, rule-based truncation, or a structured output enforcer.
6. Assess memory and persistent context:
- Analyze the LLM cache type (for example, exact match, semantic cache), TTL, and eviction policy.
- Explore how chat history works and whether session context is stored. Check whether the full history is injected into each prompt or a summarization is used.
- Analyze long-term memory: check whether there are separate memory stores, such as DynamoDB or Redis for user-specific facts.
7. Check existing protection mechanisms:
- Analyze the data filter: filtering logic, RBAC, attribute-based access, PII detection, etc.
- Determine the content filter type: on-device like LlamaGuard, external API like OpenAI Moderation, Azure Content Safety, etc.
- Check categories (hate, sexual, violence, self-harm) and thresholds used by the content filter.
8. Explore additional components and integrations:
- Find out what data the telemetry service records: raw inputs, embeddings, outputs, metadata, etc.
- Check client-side validation and determine whether input sanitization is used on the front end (web app, mobile, Slack/Teams bot, etc.).
- Analyze rate limiting, abuse detection, authentication, and authorization mechanisms.
3. Conduct threat modelling
Now, it’s time to build a risk management model based on previously collected requirements and data.
For our example, let’s use a hybrid approach combining:
- The STRIDE (Spoofing, Tampering, Repudiation, Information disclosure, Denial of service, Elevation of privilege) threat model for identifying cybersecurity threats
- LLM-specific threats from OWASP LLM Top 10
- MITRE ATLAS framework
- NIST AI RMF framework
Key actions to take for our example LLM solution:
1. Refine the data flow diagram with trust boundaries: External -> UI -> App layer -> Data layer -> LLM provider
2. Identify assets: Data in vector DB, initial prompt, embeddings/snippets, LLM outputs, API keys, telemetry logs
3. Run STRIDE analysis on each block and flow.
4. Map OWASP LLM Top 10 Link key risks to diagram:
- LLM01 Prompt Injection for UI and prompt construction
- LLM02 Sensitive Info Disclosure for data filter
- LLM03 Data Poisoning for vector DB
- LLM05 Improper Output Handling for content filter
- LLM04 Supply Chain for external LLM and embedding API
5. Create a risk matrix with high, medium, and low priorities, using CVSS and DREAD score calculators.
6. Conduct gap analysis for mitigations to assess the effectiveness of existing controls and identify gaps.
At this point, your pentesting team should have:
- A finalized threat table (Component -> Threat -> Risk score -> Mitigations -> Recommendations)
- A prioritized list for pentesting
Read also
LLM Chatbot Evaluation: Apriorit’s Testing Approach (with Examples of Test Cases)
Discover practical approaches to testing LLM-powered chatbots and ensuring reliable performance. Explore methods that help you identify weaknesses and improve the quality of AI-driven conversational systems.

4. Choose key attack techniques
Our goal at this stage is to select specific, realistic, and effective attack techniques adapted to the LLM’s architectural components. We have to select those that cover as many high-risk threats as possible yet remain within rules of engagement.
Here are the main activities for penetration testing and AI specialists to do:
- Take top threats from the risk matrix.
- For each priority threat, select two to four proven testing techniques.
- Choose a set of tools and frameworks.
- Consider testing types (black/white/gray box) and limitations.
- Create an attack matrix.
- Define success criteria.
5. Execute testing
Now, we move to test execution, applying the chosen techniques and refining them if needed.
1. Prepare the environment:
- Deploy a prod-like environment in an isolated sandbox.
- Prepare test artifacts: accounts with different roles and dummy data for the vector DB, including controlled confidential snippets.
- Populate the vector DB with authorized, restricted, and compromised documents for testing indirect injection and poisoning.
2. Configure logging for as much data as possible:
- Raw queries
- Embeddings
- Retrieved snippets
- Full prompts: before and after optimization
- LLM inputs/outputs
- Filter decisions
- Telemetry events
3. Collect baseline behavior metrics to use them later for anomaly detection during attacks. Apply exploratory testing with the following benign queries to capture normal behavior:
- Typical latency indicators, token usage, rate limits, and cost quotas
- Data filter behavior: what content and patterns are blocked or sanitized
- Triggers that activate the content filter
- Model refusal patterns and hallucination rates
4. Run reconnaissance activities to collect as much information as possible before AI penetration testing:
- Attempt to extract the initial prompt
- Track flow through error messages, timing, and telemetry (if available)
- Enumerate API endpoints: LLM API, telemetry, etc.
- Analyze code of the prompt optimization tool and filters (if possible)
5. Run parameter and model exposure testing:
- Send repeated malicious queries to assess vulnerability to model extraction/inversion
- Test for training data leaks through membership inference
6. Conduct dependency and supply chain checks:
- Scan the embedding model, vector DB client, and LLM API SDK for CVEs in dependencies
- Check whether the solution is using compromised or backdoored models/datasets with Hugging Face’s RepoAudit tool or other tools
7. Apply automated fuzzing techniques:
- Generate hundreds/thousands of mutated payloads using Garak, PyRIT, and PromptInject to obtain injection patterns (direct, indirect through poisoned fragments), check obfuscation, and test for context bombing.
- Set an automated run through the full pipeline: UI/API -> Retrieval -> Prompt -> LLM -> Filter.
- Run automatic labelling: marker data leaks, filter bypasses, anomalous token use.
8. Conduct manual exploitation and red-team testing:
- Analyze the most promising candidates for further testing (detected during the fuzzing step) in detail.
- Design creative and multi-stage attacks.
- Run direct and indirect prompt injections.
- Try RAG context manipulation by search poisoning.
- Use data filter bypass methods like hypothetical scenarios, role-play escalation, and gradual escalation.
- Attempt cache poisoning by forcing malicious responses into shared caches, prompt caches, or RAG retrieval layers for multi-user impact.
- Try Chain-of-Thought and reasoning exploitation methods, which involve poisoning intermediate reasoning steps, goal hijacking, and forcing unsafe planning paths.
9. Execute attack scenarios, such as modeling a real attack as an external user through the UI and collecting data:
- Document artifacts that led to vulnerabilities: input query, retrieved data, optimized prompt, raw LLM output, final response, filter decision, telemetry data.
- Use obtained data to track silent failures (for example, when a model executes instructions without explicit confirmation) and unauthorized actions.
- Form a quantitative assessment using categories like bypass success rate (applicable to data and content filters), confidential marker leak rate, and token/cost anomalies (for DoS and bill attacks).
By now, your pentesting team should have:
- Logs and screenshots of successful exploits
- A table with key findings: Technique -> Component -> Payload -> Result -> Severity
- Proof-of-concept payloads for critical vulnerabilities
6. Run post-test analysis and suggest remediation measures
Finally, it’s time to summarize pentesting results. Here’s what your team should do at this point:
1. Aggregate all findings and prioritize them in accordance with CVSS by impact and likelihood of reproduction. Include clear metrics such as:
- Jailbreak/prompt injection success rate, which shows the percentage of successful security bypasses from initial prompt and data filter
- Leakage rate of confidential marker snippets through RAG
- Filter bypass rate that shows false negatives of the content filter
- Model confidence score, which decreases due to adversarial inputs
- Token/cost spikes during DoS-like attacks
2. Document each vulnerability, mentioning dependent artifacts such as:
- Malicious queries
- LLM responses, including the model’s state at intermediate filters
- Telemetry and API data that has been processed
3. Compile a final report that includes:
- The narrative ー a brief description of each vulnerability
- Technical details describing the team’s work with each vulnerability: what has been done, what has happened, why it matters
- Recommendations for fixing each detected vulnerability and/or reducing the discovered risks
4. Add a regression plan for confirming the implemented fixes.
5. Propose long-term measures such as:
- Anomaly monitoring
- Periodic reassessment
- Developer training in secure prompt engineering practices
This concludes our proposed framework, showing how requirements can be implemented in practice from planning and threat modelling to execution and post-test analysis.
The next logical step for any team building or operating an LLM-based system is to either conduct a full security assessment before release or integrate such an assessment into development processes. Whatever option you choose, make sure to involve professionals with relevant experience in penetration testing, AI development, and cybersecurity.
How can Apriorit help with LLM penetration testing?
Being early AI adopters and having more than 20+ years of experience in cybersecurity, we combine our expertise to provide clients with impactful results.
Apriorit engineers help businesses:
- Protect existing solutions against attacks on AI systems that can’t be mitigated with traditional security measures
- Build products with custom-trained LLMs, ensuring protection at each stage of the project in accordance with secure SDLC principles
- Assess the cybersecurity posture of Gen AI and LLM systems, prioritizing the severity of each discovered vulnerability and offering ways to mitigate each issue
- Reduce risks of violating AI compliance and data protection regulations

Reach out to Apriorit for:
- Penetration testing 一 Engage our pentesting professionals to simulate external and internal attack scenarios, reveal critical vulnerabilities, and receive prioritized steps to improve resilience.
- Cybersecurity engineering 一 Partner with our team to assess vulnerabilities, implement effective security practices, and protect your AI-driven applications and sensitive data from modern attacks.
- LLM development 一 Collaborate with our engineers to design, develop, and integrate intelligent LLM solutions that automate workflows, improve user interactions, and support your business operations.
At Apriorit, we’re ready to help you not only build protected LLM-powered solutions but also professionally assess the security of existing products.
Want to detect threats before hackers do?
Rely on Apriorit’s penetration testing specialists to simulate attacks, expose weak spots across your LLM systems, and prioritize fixes that protect your business.
FAQ
What is AI penetration testing?
AI penetration testing is the process of evaluating AI- and LLM-based systems for security weaknesses, misuse paths, and adversarial vulnerabilities. It simulates real‑world attacks like data leakage attempts and agent/tool misuse to identify where an AI system can fail or be manipulated. The goal is to ensure that the system behaves safely and securely under both expected and hostile conditions.
How long does it take to conduct AI pentesting?
<p>LLM systems have a non-deterministic nature and layered complexity. This is why timelines and costs vary for each project. From Apriorit’s pentesting experience, we can outline several key scenarios:</p>
<ul class=apriorit-list-markers-green>
<li>A quick scan takes 3–7 working days and is suitable for early prototypes, pre-internal demos, and quick security checks. This pentesting strategy usually includes automated attack batteries on prompt injection and jailbreaking (~500–2,000 attacks), basic PII leakage and harmful content checks, and high-level architecture review.</li>
<li>A medium-depth assessment lasts 2–4 weeks. It’s best applied to production-ready chatbots, internal tools, and customer-facing assistants, and it typically involves manual and automated red teaming, RAG poisoning checks (if applicable), and basic plugin/embedding supply chain review.</li>
<li>Comprehensive red teaming may take 5–10 weeks. This is an appropriate option for high-risk industries as well as solutions with customer impact, elevated privileges, and sensitive data. Apart from activities from the medium-depth assessment, comprehensive red teaming includes intensive multi-turn simulations, agent behavior abuse, memory poisoning, cross-prompt leakage, full threat modeling, remediation validation rounds, and more.</li>
<li>Continuous or maintenance programs take 1–2 days per sprint and involve ongoing monitoring. They are applicable for mature AI product teams with frequent updates and include periodic deep dives (every 4–12 weeks), automated regression test suites in CI/CD, and post-model/prompt changes.</li>
</ul>
How can I prepare for LLM security testing?
<ul class=apriorit-list-markers-green>
<li>Define your main business goals. For example, you might need to comply with the GDPR, HIPAA, or emerging AI regulations like the EU AI Act.</li>
<li>Outline key constraints. You may have specific risk tolerance requirements and some off-limits areas like avoiding disruptions to live users or production environments.</li>
<li>Gather existing documentation. If your team already has high-level system architecture diagrams, lists of API endpoints, data flow maps, and results from prior security assessments (if any), these will accelerate the scoping phase. If not, the Apriorit team will create such documentation during initial project stages.</li>
</ul>
What items should I provide for LLM security assessment and pentesting?
<p>The exact list depends on your architecture and project requirements.</p>
<p>For existing LLM solutions, we usually request:</p>
<ul class=apriorit-list-markers-green>
<li>System access items like read-only logs, anonymized user interactions, API keys, a dedicated sandbox environment, or VPN access to a staging setup. These ensure safe testing without impacting production.</li>
<li>Datasets like sample input/output pairs from your LLM (e.g., anonymized query-response logs) to model baseline behavior. If available, share threat models, historical incident data, or fine-tuning datasets to guide targeted attacks.</li>
</ul>
What access rights should I provide for LLM security assessment and pentesting?
<p>Depending on the agreed testing framework and techniques, access levels will vary.</p>
<p>Note that:</p>
<ul class=apriorit-list-markers-green>
<li>Black-box testing requires minimal data,— often just a system name or a single endpoint. However, this type of testing involves a longer reconnaissance phase with external analysis.</li>
<li>White- or gray-box testing requires you to grant full or partial access to code, components, environments, etc. This helps reduce time for reconnaissance and enables deeper inspections of internal mechanics.</li>
</ul>
How can I track LLM security assessment progress?
<p>At Apriorit, we usually schedule a kickoff meeting with clients to decide on key work principles and how we will report project progress.</p>
<p>Here are three crucial things we discuss:</p>
<ul class=apriorit-list-markers-green>
<li>Communication protocols. We’ll agree on the regularity of check-ins during execution (for example, daily reports and/or weekly calls), escalation paths for critical findings, and reporting formats like OWASP-style risk ratings.</li>
<li>Scope boundaries and rules of engagement (RoE). We’ll align on whether we use white-box (full access) vs. black-box (no access) testing (or both). We’ll also discuss key success metrics, such as a number of vulnerabilities identified and exploit success rate.</li>
<li>Ethical guidelines. We’ll discuss details of handling sensitive data (for example, anonymization protocols), simulating attacks without real harm, and adherence to responsible disclosure practices.</li>
</ul>
What can go wrong or affect LLM pentesting results?
<p>Accurate LLM pentesting depends heavily on the conditions under which the model is tested, and several common pitfalls can distort results. From our experience, these are the seven most common risks to address during pre-testing for accurate outcomes:</p>
<ul class=apriorit-list-markers-green>
<li>Configuration mismatches between testing and production can create false negatives where vulnerabilities only appear in the live system.</li>
<li>A false sense of security when LLMs may initially resist straightforward attacks but still break under persistence. For example, a healthcare LLM might block direct PII requests but reveal sensitive data when engaged as a “helpful doctor.”</li>
<li>Gaps in component interactions, such as multi‑turn flows, agent tool‑chaining, or long‑context scenarios. Insufficient coverage of these seams leads to incomplete assessments.</li>
<li>Overreliance on outdated 2023–2024 jailbreak checklists misses high‑efficacy modern techniques such as unicode smuggling, policy puppetry, and vibe-based attacks.</li>
<li>Subjective severity assessments: disagreements on what counts as critical can cause post-delivery disputes. You can mitigate this issue by agreeing on a framework like CVSS for AI.</li>
<li>Even well‑tested systems may degrade after deployment due to model drift, guardrail updates, fine‑tuning changes, supply‑chain modifications, or the emergence of new exploit techniques. Without continuous red teaming and automated regression testing integrated into CI/CD pipelines, previously safe behavior can silently break.</li>
<li>Traditional LLM pentesting often overlooks risks introduced by agentic AI systems: goal hijacking, tool misuse, cascading multi‑agent failures, excessive autonomy, context/memory poisoning. To avoid blind spots, tests must include agentic red‑team scenarios aligned with frameworks like OWASP Top 10 for Agentic Applications (2026), using human‑in‑the‑loop validation, privilege containment, and realistic tool interaction simulations.</li>
</ul>


