 Skip to main content
Skip to main content


What is cloud computing? It’s the practice of storing, managing, and processing large amounts of data on remote servers and data centers, usually over the internet. However, cloud technologies have their drawbacks: in particular, increased latency of information processing. So when it comes to time-critical applications, there’s a need for a faster and more flexible solution. Edge computing is a response to this challenge.
In this article, we focus on what edge computing is and compare cloud computing vs edge computing. We talk about the benefits of moving data processing to the edge of the network. We also take a closer look at the main challenges edge computing faces today and whether it is able to replace cloud computing.
Contents:
Edge computing vs cloud computing
When talking about edge vs cloud computing, the focus is on where data processing takes place. Currently, the majority of existing Internet of Things (IoT) systems perform all of their computations in the cloud using massive centralized servers. As a result, low-level end devices, as well as gateway devices that have somewhat more storage and processing resources, are used mostly for aggregating data and performing low-level processing.
Edge computing offers a completely different approach: it moves most of these processes – from computing to data storage to networking – away from the centralized data center and closer to the end user. According to a study by IDC, by 2026, worldwide spending on edge computing is expected to reach nearly $317 billion. Researchers claim that edge computing has already gone mainstream, with new edge computing offerings emerging one after another.
Want to power your product with edge computing?
Leverage Apriorit engineers’ expertise to implement this cutting-edge technology securely and cost-efficiently.
Why is cloud computing not enough?
With the amount of data we currently process, cloud computing isn’t the best choice for latency-intolerant and computation-intensive applications. When you compute and analyze all data in the cloud, you inevitably face two problems: increased latency and wasted resources of decentralized data centers, cloudlets, and mobile edge nodes located at the edge of the network.
This is especially obvious in IoT: the number of intelligent devices is growing rapidly. Here are some predictions of how fast this industry will grow in the future:
- Statista predicts that by 2030, the number of connected devices will reach 29 billion, compared to only 15.1 billion in 2020. Additionally, by 2030, 75% of all devices are forecast to be IoT.
- Juniper Research estimates that the number of connected devices will grow to 83 billion by 2024.
The main problem is that all of these devices generate huge amounts of data but don’t process it. Instead, they send all this information to the cloud, which leads to overloading of both data centers and networks. Increased latency is a great challenge for IoT and mobile virtual reality products.
Performing computations closer to the data source can help lower the general dependence of your service or app on the cloud and make data processing faster.
Read also
Cloud Computing: A New Vector for Cyber Attacks
Learn about the key vulnerabilities of cloud computing and get practical advice on ensuring your cloud-based solution’s security.

What is edge computing?
So, what is edge computing, and how does it differ from cloud computing? The main difference between edge and cloud computing stems from the fact that edge computing paradigms offer a more decentralized architecture, with most data processing happening on the very devices that generate data. Instead of one centralized processing point, edge computing uses a mesh network of smaller data centers that can store and process data locally at the “edge” of the network.
There are two forms of edge computing:
- Cloud edge, when the public cloud is extended to several point-of-presence (PoP) locations
- Device edge, when a custom software stack emulating cloud services runs on existing hardware
The main difference between these two forms is in their deployment and pricing models. Since cloud edge is just an extended form of the traditional cloud model, the cloud provider is responsible for the entire infrastructure.
The device edge lives on the customer’s hardware, making it possible to perform near real-time processing of requests.
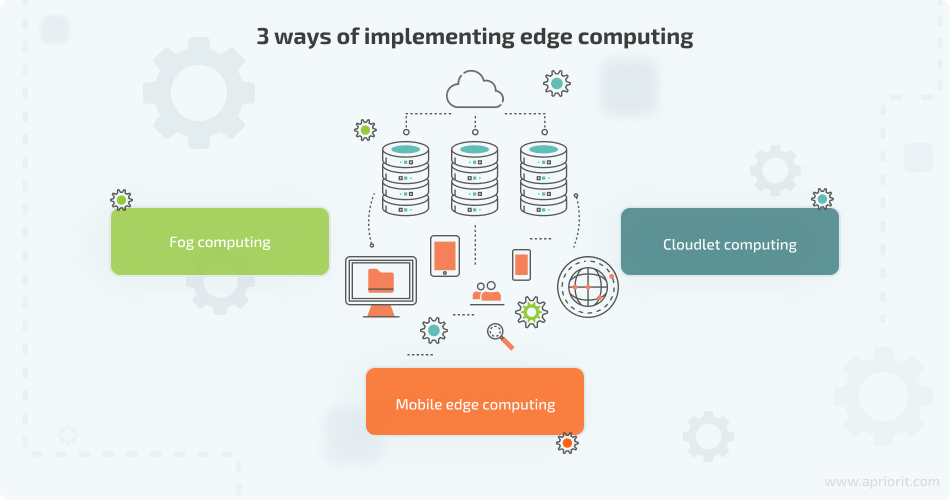
There are three ways of implementing edge computing:
- Fog computing – a decentralized computing infrastructure in which all data, storage, and computing applications are distributed in the most efficient way between the cloud and end devices
- Mobile edge computing (MEC) – an architecture that brings computational and storage capacities of the cloud closer to the edge of the mobile network
- Cloudlet computing – an infrastructure that uses smaller data centers to offload central data centers and bring the cloud closer to end users
Edge computing opens new possibilities for IoT applications that rely on machine learning, boosting the speed of performance for language processing, facial recognition, obstacle avoidance, and other tasks. Plus, it helps take some of the load off the main data center and network, reducing the total amount of centralized processing.
In what areas can you use edge computing?
According to the IDC study, enterprises and the public sector’s biggest investments in edge computing are related to production asset management, autonomic operations, omnichannel operations, and augmented customer service agents. The edge computing use cases that are expected to grow the fastest between 2021 and 2026 are emergency response, 360-degree educational video viewing, and film production.
Below, we give several edge computing examples and list areas where it appears reasonable to move computational processes to the network edge.

- Smart homes and cities. With a constantly growing number of sensors, smart cities cannot rely only on cloud computing. Processing and analyzing information closer to the source may help reduce latency in smart cities and for community services that require fast responses, such as law enforcement and medical teams.
- Smart transportation. Edge computing allows you to send all information locally, processing and sending to the cloud only the most important data. This technology is already used for improving the quality of both commercial and public intelligent transportation systems. It also helps increase the safety and efficiency of travel by feeding local information patterns into larger and more widely accessible network systems.
- Media production. Edge computing is utilized in media production, including film production, for optimizing the real-time processing of high-resolution video footage, enhancing the efficiency of post-production workflows. Edge computing minimizes latency and facilitates seamless collaboration among production teams. This results in accelerated rendering times and smoother collaboration, ultimately improving the overall speed and quality of the content creation process.
- Retail operations. Edge computing in retail is used for inventory management, in-store analytics, and omnichannel operations that allow businesses to improve the customer experience and increase operational efficiency.
- Drones and remotely operated vehicles. When a self-driving car must react to the data it collects, even the smallest delay can lead to a potentially dangerous situation. Moving computation closer to the data source significantly reduces latency and improves quality of service.
- Virtual education. Edge computing enhances educational experiences through seamless streaming and interaction with 360-degree educational videos. This is particularly relevant in virtual learning environments, such as educating NASA pilots with realistic flight simulations, surgical training for practicing complex procedures, or industrial technician training for machinery operation.
- Healthcare operations. Edge computing is applied in healthcare for tasks such as remote patient monitoring, real-time data analysis, and emergency patient care.
Many industry giants are moving away from the cloud and closer to the edge, including such companies as Microsoft, Amazon, Dell, and Google. At the same time, several startups such as Vapor IO are trying to build new networks of distributed data centers.
Main pros and cons of edge computing
Of course, moving computation away from the cloud has its benefits and drawbacks. Below, we list the most relevant pros and cons of using an edge computing approach for business.

Benefits of edge computing
Edge computing brings multiple benefits to businesses that utilize IoT devices in their operations. Let’s look at the advantages of edge computing over cloud computing for your software ecosystem.
Decreased latency is the most important benefit of performing computation at the network edge. Reducing latency is especially important for applications requiring an immediate response. As a result of edge computing, connected applications become more responsive and robust.
Network and data overload prevention is achieved by processing data at the point of origin. Instead of making a device-cloud-device data round trip, you can lift the burden from both data centers and networks. Loading becomes more scalable with respect to the number of endpoints as computing resources grow proportionally. Avoiding round trips to and from the cloud or a centralized data center is especially important for applications that use machine learning or computer vision.
Increased redundancy and availability for businesses are provided by the inherent properties of edge computing. When computation is performed at the edge, any possible disruption can be limited to one point in the network instead of the entire system, as is the case with cloud computing.
Cost-efficient management and connectivity are provided by prioritizing data. When you send only significant information instead of raw streams of sensor data and send it only short distances, it saves a lot of computing resources and allows for more efficient network management.
Drawbacks of edge computing
Limited data processing capacity makes it challenging to store and process huge sets of information since all computation takes place on edge nodes that have their limitations. This is especially true for real-time data processing, which becomes less efficient as the number of devices grows. Your developers should strike a careful balance between decreasing the number of legacy nodes and edge nodes in your system.
Also, since edge nodes’ capabilities are limited, there may be additional limitations on what software is compatible. Therefore, it’s preferable to use less resource-intensive, lightweight databases and software for edge computing.
Lack of standardization in edge computing can pose a challenge for developers. Unlike the cloud, where programs are compiled for specific target platforms using a single programming language, edge computing involves diverse platforms with varying runtimes.
Additionally, lack of a standardized naming mechanism adds complexity. Traditional systems like Uniform Resource Identifier (URI) and Domain Name System (DNS) prove insufficient in a dynamic edge network. Instead, developers must grapple with different network and communication protocols, opting for emerging naming mechanisms like MobilityFirst and Named Data Networking (NDN) as alternatives to the conventional DNS. This absence of standardization in programming and naming hinders the seamless integration of applications across the diverse edge computing landscape.
Challenging optimization can occur in edge networks due to a large number of layers that have different computational capabilities. This makes it harder for developers to allocate workloads and optimize the system.
Difficulty in splitting computing tasks among nodes can also make it hard to create an intelligent connection scheduling policy. To do it correctly, developers need to assess a node’s capacity to perform required computations without sacrificing its productivity. So, optimization in edge computing requires fine-tuning and specific expertise from your team.
Privacy and security can be compromised in edge computing due to end devices being more vulnerable to attacks than a centralized data center. Later in this article, we look closer at this particular problem.
Read also
Multi-Cloud Computing: Pros and Cons for Enterprise
Learn when it’s best to go with multiple cloud services instead of one and the best practices to use for this model.

Requirements for implementing edge computing
There are several requirements for ensuring quality implementation of the edge computing model:

Below, we take a closer look at each of these requirements.
Scalability
Edge computing needs to be able to provide steady performance even if the number of end devices and applications increases significantly. This can be achieved by adding new points of service and therefore expanding edge computing geographically, or by adding new service nodes to an existing network. You can also use cloud interplay and make your edge computing model work as an independent mini-cloud.
Reliability
Reliability is one of the main problems you need to think of when moving computation to the network edge. Reliable edge computing ensures failover mechanisms for different cases, from failure of an individual node to failure of the entire edge network and service platform to lack of network coverage.
You need to implement protocols similar to packet pathfinding in order to ensure that you can find available services in the event of a failure. Additionally, significant information, such as client session data stored on edge devices, needs to be consistently backed up so it can be recovered in case of device or network failure. Plus, in contrast to cloud computing, you can’t immediately add new nodes to existing edge computing infrastructure.
However, you can increase the reliability of your edge computing model by implementing the three following techniques:
- Rescheduling failed tasks
- Creating checkpoints by periodically saving the state of user services and end devices
- Replicating edge servers and mini data centers in multiple geographical locations
Resource management
Creating an efficient resource management model is another crucial issue posed by the edge computing paradigm. Edge computing requires adopting multi-level resource management techniques that can be applied at the edge network level as well as in coordination with remote cloud providers and edge networks.
Such technologies as network function virtualization (NFV) and software-defined networking (SDN) may be helpful in easing the monitoring and management of edge resources.
Interoperability
One of the main requirements for an efficient edge computing model is to provide interoperability among various edge devices. Therefore, edge computing needs to define standards of interoperability for both applications and data exchange between users. Standard protocols that apply to all devices within the network also need to be devised.
Security
Security in edge computing has two aspects:
- Isolating data paths and memory
- Ensuring protection of edge devices against malicious users
While cloud computing ensures data isolation by using virtualized devices, edge computing needs to define sandboxes for user applications in order to monitor resource use and ensure the isolation of sensitive data. Network function virtualization appears to be one possible solution. This concept can be applied to network nodes to ensure the protection of user domains. However, since NFV is still a relatively new technology, many network vendors are still working on establishing standards to ensure interoperability.
Let’s talk more about the security risks in edge computing and ways to mitigate them.
Edge computing security concerns
When it comes to edge computing and information security, there are two completely opposite points of view. On the one hand, storing, processing, and analyzing sensitive information close to the source rather than sending it over the network may help improve data protection. On the other hand, there is the possibility of end devices being even more vulnerable to attacks than a network of centralized data centers.
As a result, when building an edge computing solution, you need to pay special attention to ensuring the protection of the entire system. Access control, data encryption, and virtual private network tunneling may be of help.
The major challenge with developing a reliable lightweight security solution is the diversity of edge computing environments.

In general, there are three major security challenges associated with edge computing:
- Creating an efficient authentication mechanism – giving access to edge computing services only to authorized end devices is crucial for preventing the entry of potentially malicious nodes. The problem is that standard solutions applicable in the cloud can’t be used at the network edge because of the significant difference in end devices’ power, storage, and processing capabilities. As a result, you need to implement lightweight security and privacy solutions.
- Protecting against cyber attacks – an edge computing environment is vulnerable to different types of malicious attacks such as spoofing, intrusions, and Denial-of-Service (DoS). Implementing proper security measures like robust encryption protocols, intrusion detection systems, and firewalls is essential for the protection of network capabilities.
- Ensuring end users’ privacy – since sensitive data may be collected by edge nodes, there’s a need to ensure the protection of such data. Also, user habits can be revealed to an adversary by analyzing the usage patterns of edge services. To address potential privacy concerns, we recommend implementing differential privacy that can safeguard sensitive user data collected by edge nodes. Additionally, you can use encryption, intrusion detection systems, and firewalls to ensure the security of your network capabilities.
Read also
Cloud-Based Testing: Benefits, Challenges, Types, and Tips
Get expert advice on cloud-based testing to ensure the maximum efficiency and security of your product.

Conclusion
While some believe that edge computing can replace cloud computing altogether, these two approaches are complementary rather than substitutes. When used in conjunction, cloud, and edge computing architectures allow businesses to store and process data more effectively.
Furthermore, many businesses are already using a hybrid architecture to improve performance and customer satisfaction. Cloud computing remains one of the best ways to safely back up and store large sets of information. It also can be effectively used for performing less time-sensitive data processing. For operations requiring faster data processing, performing computations on distributed data centers or devices themselves appears to be the best solution.
The Apriorit team can pick the right solution based on the differences between edge computing and cloud computing, or suggest a hybrid approach if it suits your business needs. Our specialists have extensive experience building efficient and secure infrastructures that are easy to maintain and scale.
Need to build a robust cloud infrastructure?
Get a team of top-level experts to design a scalable and productive device network ecosystem for your business!
Have a question?
Ask our expert!
VP of Innovation and Technology, Canada Branch Director


