 Skip to main content
Skip to main content

Features that recognize emotions can elevate your cybersecurity software, significantly expanding its capabilities and improving its competitiveness. A popular example is emotion recognition in images and videos for analyzing facial expressions and body language. Some companies use this functionality to ensure security at the workplace, detect deepfakes, and more.
Moreover, the latest advancements in artificial intelligence (AI) can help your solution identify human emotions in voice recordings. Businesses now see the potential to use speech emotion recognition (SER) to enhance the customer experience, personalize marketing activities, and even conduct insightful market research. However, you can also use this technology for cybersecurity purposes.
In this article, you’ll find a brief and clear description of how SER works along with its two major applications for cybersecurity solutions: enhancing biometrics to prevent identity theft and detecting fraud. We also discuss common concerns and nuances of SER implementation that are worth knowing. This article will be helpful for project leaders looking to enhance their existing cybersecurity software with AI functionality.
Contents:
What is speech emotion recognition?
Emotion detection is a promising vector of AI technology development that’s worth attention from businesses. According to a FutureWise analysis, the market for emotion recognition and detection was worth $31.62 billion in 2023 and is expected to grow to $142.64 billion by 2031.
Along with facial, gesture, posture, and voice detection, speech emotion recognition can be used in marketing, entertainment, and even medical emergencies. Another industry to uncover the potential of AI-powered speech emotion recognition is cybersecurity. But before we start unveiling the nuances of using SER for digital security purposes, let’s briefly define terminology.
What is speech emotion recognition?
Speech emotion recognition, or SER, is a set of methodologies that process and classify speech signals to detect embedded emotions. SER technology uses advanced algorithms, including machine learning (ML), to detect and interpret the underlying emotional content in human speech.
The results of speech processing depend on SER software configurations. Most commonly, the goal of such solutions will be to determine the emotional state of a speaker: happy, angry, sad, fearful, and so on. But some applications might also detect speech patterns like pitch and rhythm.
Where can businesses use speech emotion recognition?
Businesses can apply SER technology to virtual assistants and advanced chatbots to make them more personalized and empathetic. Such solutions can be used in marketing, retail, and healthcare.
Another application of SER systems is evaluating call center agents’ performance. SER software can detect and recognize customer emotions, providing companies with information on call center efficiency. Then, the company can decide whether there’s a need to arrange additional training for improving customer service.
Another promising way of applying SER is using this technology for cybersecurity purposes. In this article, we focus on the cybersecurity potential of speech emotion detection and recognition. But before we discuss how you can leverage SER to enhance prevention of fraud and identity theft, let’s take a look at how this technology works.
Need help with AI functionality?
Easily bring your IT project to the next level by delegating all of your engineering challenges to Apriorit’s tech gurus.
How speech emotion recognition works
Different solutions for emotion recognition from speech may operate differently. However, there are three general steps most AI-powered SER software shares:
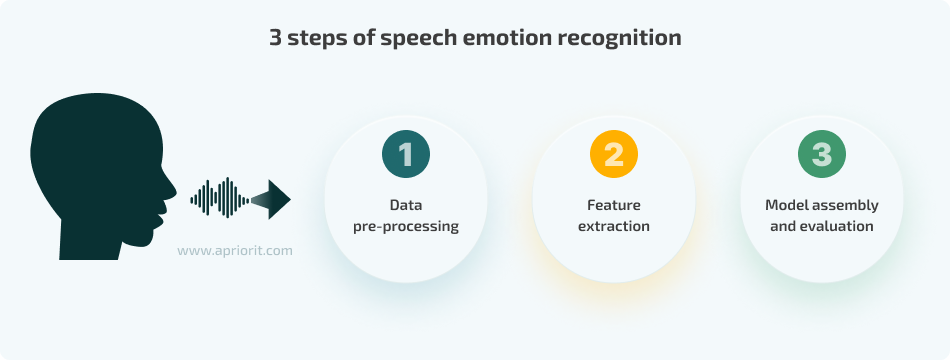
1. Data pre-processing is about preparing the recorded speech for analysis. One of the main goals of SER software is to detect audio fragments for processing and make sure they are of appropriate quality. This step might include different processes like:
- Sampling ー converting the raw audio signal into a digital signal
- Framing ー partitioning input speech signals into fixed-length segments
- Windowing ー mitigating the effects of possible spectral leakages
- Noise and silence removal ー isolating the speech from other parts of recordings
- Fourier transforms ー transferring the raw audio wave from the time domain to the time-frequency domain to gain frequency information
- Wavelet transforms ー decomposing the signal into high-frequency and low-frequency components for better time and frequency resolutions
- Data augmentation ー introducing changes to samples in order to collect enough audio data or address data imbalances in different emotion classes
2. Feature extraction involves obtaining characteristics from speech signals that indicate the emotional content of speech. During this step, software also removes redundant and unnecessary features, enhancing the model’s accuracy. Audio features are often categorized in one of two ways:
- Traditional (hand-crafted), such as prosodic, spectral, and acoustic features. They show intensity, pitch, spectral balance, formant frequency, etc.
- Advanced features that aim to unveil a richer array of emotional information embedded within the speech, including deep features and features based on Empirical Mode Decomposition and Teager–Kaiser energy operator techniques.
3. Model assembly and evaluation (also called emotion classification) refers to designing the SER model architecture and selecting ML algorithms. This step usually comprises:
- Choosing an ML model architecture and algorithms. One option is a single-classifier architecture made from only one Support Vector Machine (SVM) or Convolutional Neural Network(CNN) algorithm. Another commonly used option is ensemble models that are developed based on a particular combination of multiple algorithms, such as a Convolutional Recurrent Neural Network (CRNN) that is assembled from CNN and RNN.
- Designing the SER model. During this process, developers assemble the chosen algorithms and build a speech emotion recognition model.
- Evaluating the model. Finally, engineers validate the final performance of the created SER model using relevant evaluation criteria.
With a general understanding of how SER works, let’s move to discussing how it can be applied in cybersecurity.
Related project
Building AI Text Processing Modules for a Content Management Platform
Discover the details of a successful, real-life project that enhanced a client’s platform with advanced content processing capabilities powered by artificial intelligence. Explore how Apriorit introduced new functionality to help our client gain a competitive advantage in their niche and improve the user experience.

How to apply speech emotion recognition in cybersecurity: use cases
Advanced emotion recognition solutions have already found several applications in security. Such comprehensive software often includes several types of emotion recognition ー physiological signals, text semantics, and visual features recognition ー in addition to SER capabilities to improve the accuracy of emotion detection.
Some security organizations already use systems that analyze people’s emotions on video records. Although such solutions aim to identify and indicate the source of a potential threat, some examples of emotion recognition usage can be concerning, while violating privacy rights. For example, in China, police leverage software processing data from CCTV cameras that record faces, voices, body temperature, and movements of people coming into view.
You can also apply voice emotion recognition in IoT-powered automotive software to prevent accidents when detecting tiredness in a driver’s voice. Such onboard systems can also record the frequency of blinking and yawning along with driving patterns, notifying a driver if their patterns drastically change.
In cybersecurity, AI speech emotion recognition is just starting to gain momentum. However, we already can outline two promising use cases:
Enhance biometrics to prevent identity theft
Biometrics are a common part of multi-factor authentication (MFA) features used to secure sensitive data and intellectual property. MFA helps organizations make sure only authorized people can access corporate networks and software accounts. A user’s voice can also be used for biometric-based MFA: for example, to prevent identity theft.
Criminals can come up with various ways to overcome voice-protected cybersecurity defenses. For instance, they could use AI algorithms to create fake speech recordings (or even a digital twin) if they manage to obtain any sample of a victim’s speech. As a matter of fact, synthetic voice creation is on the rise, especially with OpenAI improving their Voice Engine model that generates audio based on real voice references. Or malicious actors can even threaten a victim, forcing them to log in to the system while they’re watching.
AI-powered speech emotion recognition is one way to help your solution detect attempts at identity theft. For example, you can leverage SER functionality to enhance deepfake detection. This will allow your solution to recognize fraud at the audio level in addition to the video level. Using audio spoofing detection systems would be efficient because audio deepfake techniques can’t correctly synthesize natural emotional behavior of a real person.
Detect fraud and prevent security incidents
Voice recognition is popular among businesses within various industries like insurance, finance, and banking. According to a report by AiteNovarica, 23% of surveyed insurance companies had already deployed AI voice recognition and 18% were in the process of doing so by the end of 2022. A common use case of this technology is to create voice assistants. Apart from automating business processes and improving the customer experience, such solutions promise to enhance fraud detection.
Enhancing virtual voice assistants with SER can help insurers and banks identify individuals with potentially fraudulent intentions. ML algorithms powered with both SER and semantic analysis capabilities can detect speech characteristics and signs of specific emotions that might be a sign of malicious intent. Once an SER feature flags a potential risk, responsible employees can perform an additional check.
Another helpful application of SER for fraud prevention is detecting negative emotions. If a person sounds stressed, it might indicate that they are under threat or intend to act maliciously. Moreover, researchers have already started creating and testing tools to analyze voices to detect stress in real time. This means you can make your solution quickly detect possible issues and start additional verification processes or notify security officers.
Read also
AI and ML for Fraud Detection: Top Use Cases, Approaches, and Technologies
Prevent cybersecurity incidents by using artificial intelligence and machine learning to their fullest! Explore how these technologies can help you enhance fraud detection capabilities.

What are the limitations of speech emotion recognition
Although implementing SER in your product can help improve authentication processes and detect fraud, you also need to be ready to address some limitations. Note that some of the concerns we discuss below don’t have an efficient solution yet, so we can’t provide detailed advice on solving them all.

- Legal concerns. A great challenge in AI development is to make sure your systems don’t break the law. Thus, your legal department has to monitor international, federal, and local legislation to check whether your software works and processes data in compliance with relevant laws and regulations. For example, explore requirements of the GDPR and the EU Artificial Intelligence Act.
- Cultural differences. Different cultural and ethnic groups express emotions in different ways. For example, some people try hiding their emotions and controlling the loudness and tone of their voice, considering it impolite to show emotions in public. In some cultures, lowering your voice is considered to be a sign of strong emotions, while in other cultures it’s acceptable for casual talk. Thus, cultural differences introduce additional risks for false positive and false negative results in SER solutions.
- Psychological differences. Even people from the same culture and region express emotions in different ways. The way individuals show emotions can depend on their temper, upbringing, education, age, and social status. In simple words, similar indicators can mean calmness for one person and anger for another.
- Security and privacy concerns. Your users are likely to be afraid that someone might misuse recordings of their speech. Some smart speaker voice assistants like those from Amazon Echo and Google Home already raise privacy concerns due to their access to speech. To address such challenges, your team must carefully plan the data processing workflow, ensure robust data security measures, and establish continuous oversight of gathered data.
- Ethical concerns and bias risks. Wide use of SER features comes with privacy concerns and ethical implications. If emotion recognition systems are used in enterprises, they can cause stress and burnout among employees. Apart from that, like most AI-driven technologies, SER technologies can’t always guarantee accurate results, as there’s a risk of bias. Common reasons behind these issues are datasets of insufficient quality, poorly developed AI models, and insufficient testing.
- Audio-related limitations. Some recordings can be too loud or too quiet, have too many noises, or contain silence. Because of these obstructions, the AI model might not be able to accurately detect and recognize emotions. Note that training an AI model to work correctly with low-quality recordings takes time, and perfect results are not guaranteed. Also, some unique challenges might arise, like differentiating the voices of identical twins.
Related project
Building an AI-based Healthcare Solution
A healthcare provider improved doctor–patient interactions and increased diagnostic accuracy with the help of an advanced medical system developed by Apriorit. Explore how we achieved 90% precision in detecting and measuring objects during medical video processing.

How Apriorit can help you implement SER in your software
Here are only a few of the multiple tasks we can assist you with when developing speech emotion recognition functionality or a standalone custom SER solution:
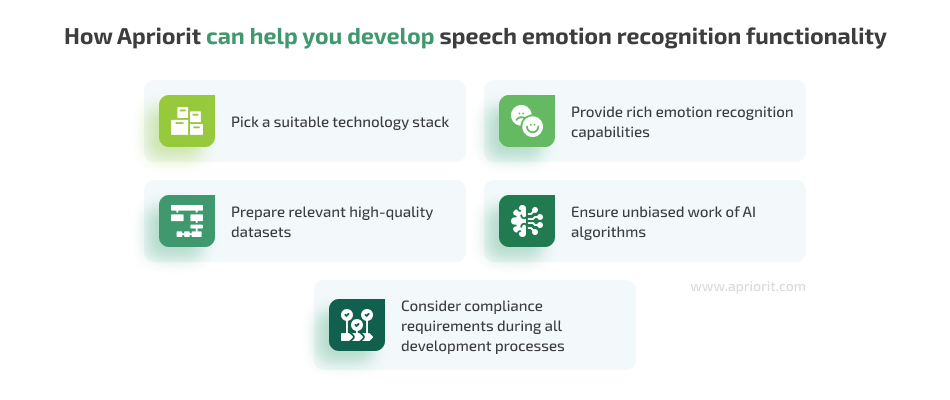
- Choose the most suitable technology stack. Apriorit developers have rich experience building solutions for speaker recognition and speech emotion recognition using machine learning algorithms and deep neural networks. We know what tools and models to use for different types of software to build robust speech recognition functionality that will meet your project requirements and business needs.
- Build a complex emotion recognition solution. Apart from SER, we can enhance your software with functionality for recognizing emotions in images and video.
- Prepare relevant datasets. We will help prepare quality datasets for training and testing ML models to increase the accuracy of your final solution. Our AI engineers continually research and apply efficient methods to mitigate issues of insufficient or poor-quality data.
- Ensure unbiased work of your software. With vast experience delivering AI-driven solutions, we know how to help you achieve fairness in the way your product operates.
- Help your solution comply with requirements. Whatever industry your project operates in, Apriorit’s development team will make sure that its functionality, data storage and processing, and security measures meet requirements of the GDPR, HIPAA, PCI DSS, or other regulations, laws, and standards.
Conclusion
Speech emotion recognition is a promising technology for enhancing cybersecurity solutions. We are already seeing its capabilities for detecting and preventing fraud and identity theft. And since SER is still evolving, we can expect more helpful use cases to appear in the future.
However, developing and implementing SER in your software might be tricky. You need a strong engineering team capable of mitigating challenges and pitfalls on the way to proper audio processing, noise reduction, emotion detection, and emotion recognition.
At Apriorit, we have dedicated teams with vast experience in cybersecurity projects as well as in AI and ML development. Our engineers are ready to assist you with tasks and assignments of any complexity.
Ready to kickstart your next AI project?
Get a solution that aligns with user expectations and your business needs. Leverage the experience and expertise of Apriorit’s artificial intelligence and cybersecurity developers.
Have a question?
Ask our expert!
R&D Delivery Manager


