 Skip to main content
Skip to main content
Almost 40% of internet traffic is generated by bots according to the Bad Bot Report 2019 by GlobalDots. Bots comment on the news, buy out tickets to popular events, collect emails and scrape private data, and send billions of spam messages. Technologies based on the Turing test help to stop them by telling humans and bots apart. CAPTCHA is one of the most widespread Turing test implementations. CAPTCHAs are supposed to prevent bots from messing around with websites. But do they really work?
In this article, we examine different types of CAPTCHAs, analyze the pros and cons of using this technology, and show you how to integrate reCAPTCHA v2 and v3 on your website.
This text will be useful for web developers and everyone who wants to study CAPTCHA or look at some practical examples of a simple and reliable way to detect and limit abusive traffic.
Contents:
- What is CAPTCHA?
- Pros and cons of using CAPTCHA
- 6 common use cases for implementing CAPTCHA
- How does reCAPTCHA work?
- How to integrate reCAPTCHA to a website?
- Registering web app domain for reCAPTCHA v2 and v3
- reCAPTCHA 2: front-end integration and back-end validation
- reCAPTCHA 3: front-end integration and back-end validation
- Conclusion
What is CAPTCHA?
A CAPTCHA, or “completely automated public Turing test to tell computers and humans apart,” is a type of challenge–response test used to determine whether a user is a human or a bot.
Before providing access to a website or service, a CAPTCHA displays a series of pictures, a text, or a checkbox and waits for the user’s response. With tests based on text recognition and questions, a CAPTCHA can also read the text aloud for users with visual impairments.
Access is granted if a user provides the correct answer. For a human, it takes 10 seconds on average to recognize distorted CAPTCHA symbols, but for an ordinary spam bot it’s almost impossible.
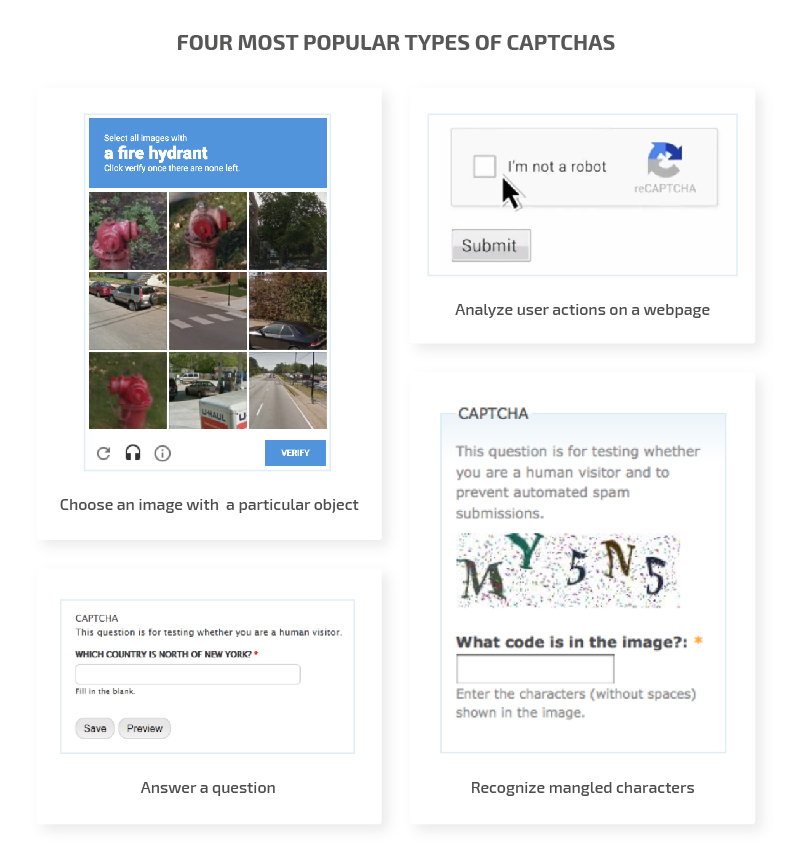
CAPTCHAs can detect bots with four types of tests:
- Ask the user to choose an image with a particular object
- Ask the user to recognize mangled characters
- Ask the user to answer a question
- Analyze the user’s actions on a webpage
Despite being implemented on thousands of websites, the effectiveness of CAPTCHA is still a matter of debate. Let’s take a look at its key advantages and disadvantages.
Pros and cons of using CAPTCHA
The key advantage of using CAPTCHA is that it can detect abusive traffic with relatively little effort. With millions of bots lurking around the internet, it’s impossible to analyze interactions with real users without protection measures. Meanwhile, CAPTCHA helps to filter out illegitimate traffic and distinguish bots from humans. Developers can use lots of free and easy-to-integrate CAPTCHA services to protect their websites.
CAPTCHAs are intuitive to any internet user because they’re widespread on popular sites. Therefore, people aren’t alarmed by a request to enter some text from an image, and you don’t need to add an explanation on how to use a CAPTCHA.
However, the effectiveness of CAPTCHAs is now being questioned. While protecting us from simple bots, CAPTCHAs are useless against machine learning and artificial intelligence algorithms. In fact, these algorithms are even better at solving CAPTCHAs than humans are.
In 2016, Google used one of its machine learning algorithms to test the most distorted images of reCAPTCHA — a Google service that detects abusive traffic based on CAPTCHA solving and user behavior analysis. The test showed an alarming result: while humans recognized 33% of images, the algorithm successfully deciphered 99.8%.
The second disadvantage of CAPTCHAs is user irritation. There are several reasons CAPTCHAs may displease users:
- In order to make CAPTCHAs more challenging for bots to solve, the tests have come to use more and more distorted images — up to the point when a human can’t read the text.
- Users with impaired vision, dyslexia, and other conditions may have difficulties solving CAPTCHAs. Besides, in many cases, audio voicing of a CAPTCHA is as hard to decipher as the image.
- Some web developers protect each user interaction with a CAPTCHA, which is annoying for users.

Examples of unreadable CAPTCHAs
New versions of CAPTCHA that separate humans from bots by analyzing user behavior also raise privacy concerns. For example, Google developers working on reCAPTCHA don’t disclose the parameters of their tests. Otherwise, bot creators would be able to study the algorithm and use this knowledge to reconfigure bots and bypass the check. That means nobody knows how exactly the invisible reCAPTCHA works and whether it collects any private information of internet users.

Despite these issues, there are still lots of cases when CAPTCHAs help to limit abusive traffic. Let’s take a look at some of them.
6 common use cases for implementing CAPTCHAs
A CAPTCHA can secure any user interaction with a website. Some websites, like Dark Reading, even require a user to solve a CAPTCHA simply to access the website.
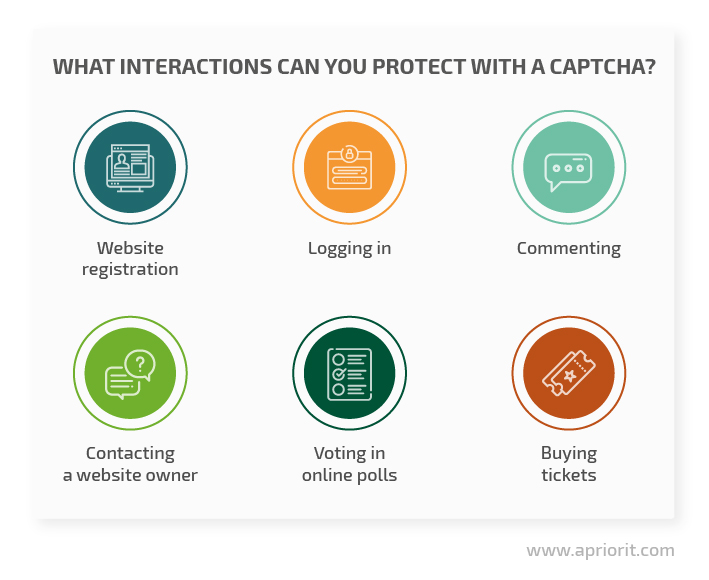
Here are six examples of user interactions that can be effectively protected with a CAPTCHA:
1. Website registration
Bots can create fake accounts on mail services, social networks, or any other websites and use those accounts for spam or any other malicious activities. A CAPTCHA verifies that a user registering on a service is a human. Also, validation at this point improves website usability, as there’s no need to test registered users again when using the website.
2. Login confirmation
To bypass a CAPTCHA at registration, some bots try to hack user accounts by performing a dictionary attack. This is a type of brute-force attack when bots guess a password by trying every word in the dictionary. To prevent a bot from iterating through the entire dictionary, you can require it to solve a CAPTCHA after a certain number of unsuccessful login attempts.
3. Commenting
Lots of blogs and forums allow both guests and registered users to comment on posts. But there are programs that write fake comments to improve the search rankings of websites or promote a certain point of view. Using a CAPTCHA helps to reduce the number of fake comments and therefore ensure the reputation and ratings of a website.
4. Contacting the website owner
Spammers seek out feedback forms that contain contact information posted in plain text and add those contacts to spam databases. Because of that, feedback from real users can be lost in hundreds of spam messages. Hiding contact information and feedback forms with a CAPTCHA allows a developer to improve website usability and protect the website’s owner from spam.
5. Voting in online polls
The results of open online polls cannot be trusted if votes can be submitted by bots. Yet such polls are a popular and easy way to hear the views of website users. Requiring users to solve a CAPTCHA before voting stops bots from tampering with poll results.
6. Buying tickets
Tickets for popular events are usually sold out within minutes not only because of fans but also because of resellers and bots. If a ticketing system requires a buyer to solve a CAPTCHA, there’s a high chance the ticket will be sold to a human instead of a bot.
These six use cases represent the actions most commonly protected by a CAPTCHA. However, you can protect any user interaction on a website with a CAPTCHA.
So far, we’ve defined when to use a CAPTCHA and what pitfalls you might face in doing so. Next, let’s find out how to implement reCAPTCHA.
How does reCAPTCHA work?
reCAPTCHA is a bot traffic detection algorithm originally designed at Carnegie Mellon University and now owned by Google. This free service became popular for several reasons:
- Simple integration
- Reliable protection against abusive traffic
- Ability to conduct tests with one click or no user actions at all
reCAPTCHA has three versions. reCAPTCHA v1 used parts of images from Google Books, Google Maps, and Google Street View and collected data to train Google object and text recognition algorithms. Today, it’s no longer available to developers. Instead, we can use reCAPTCHA v2 or v3.
reCAPTCHA v2 is the well-known “I’m not a robot” checkbox. It requires the user to click a checkbox indicating they’re not a robot. After checking the box, the algorithm usually allows users to continue with no additional checks. If the algorithm considers a user’s behavior suspicious, it challenges them to prove that they’re a human by recognizing objects in distorted pictures.
Here’s what this check looks like:

reCAPTCHA v3, presented in 2018, is the newest version of this algorithm. It’s designed to improve protection measures and minimize friction and user irritation. In fact, it’s invisible to an ordinary user.
Unlike other types of CAPTCHA, reCAPTCHA v3 is based on advanced risk analysis instead of a challenge-response test. It analyzes data on user behavior on a website and returns a score from 0.0 to 1.0 for each request, where 1.0 is very likely a good interaction and 0.0 is very likely a bot.
Website administrators can set various responses based on scores: log out users, ban them from the website, respond to their request with a 403 error, etc. reCAPTCHA works best when it has the most context possible about user interactions with a site, both legitimate and abusive. For this reason, it’s recommended to include reCAPTCHA verification on forms and actions as well as in the background of pages for analytics.
As we’ve mentioned, Google doesn’t disclose how and what types of user activity data it uses for this risk analysis algorithm, and that causes privacy concerns.
Now you know how reCAPTCHA v2 and v3 work. Let’s move to a tutorial on how to implement these algorithms.
How to integrate reCAPTCHA on a website
The whole process of integrating reCAPTCHA v2 and v3 can be split into three steps:
- Register the web app domain with Google
- Add Google reCAPTCHA to the front end of your application
- Implement backend validation for reCAPTCHA
Registering a web app domain for reCAPTCHA v2 and v3
The first step is the same for both versions of the algorithm: you need to register your website in the reCAPTCHA service and choose the version of reCAPTCHA you would like to use.
During website development, set the domain as localhost. You’ll be able to change it when you’re ready to deploy the site.
Choosing a custom port is not allowed, so your site should be running on port 80 or 443.
After successfully registering, you’ll be provided with two keys:
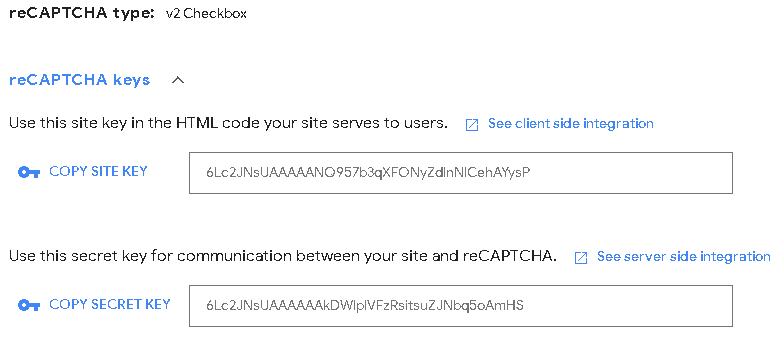
You’ll need these keys to integrate reCAPTCHA into your website: the site key, visible in the website HTML code, should be placed on the client side, and the secret key (or private key) should be placed on the back end for validating the site key.
It’s best not to use the secret key on the front end because if you do, users could obtain it. For example, if you turned off verification of the reCAPTCHA origin and someone got the secret key for your reCAPTCHA, they could integrate your reCAPTCHA into their own website and you wouldn’t receive clear statistics on user interactions with your website.
reCAPTCHA 2: frontend integration and backend validation
Client-side implementation of reCAPTCHA v2 is simple. First, you have to add the source script for reCAPTCHA to the front end of your website:
<script src="https://www.google.com/recaptcha/api.js" async defer></script> Then add the reCAPTCHA block itself:
<div class="g-recaptcha" data-sitekey="YOUR_SITE_KEY"></div>After a user clicks the checkbox, you’ll be provided with a token. You can retrieve it by calling either grecaptcha.getResponse(); or $('#recaptcha-token').value.
The first call is preferable because it’s best to utilize the API provided by the official library rather than writing your own solutions. Custom calls may become invalid after Google updates the reCAPTCHA library.
The token you obtain should be sent to the back end to perform validation. With that, reCAPTCHA v2 is integrated into the front end.
Now you can implement the back end for reCAPTCHA v2. Here’s an example written in C#:
private const string GoogleApiUrl = "https://www.google.com/recaptcha/api/siteverify?secret={0}&response={1}";
private bool Validate(string token, string secretKey)
{
var uri = string.Format(GoogleApiUrl, secretKey, token);
var req = WebRequest.Create(uri) as HttpWebRequest;
using (WebResponse response = req.GetResponse())
using (StreamReader stream = new StreamReader(response.GetResponseStream()))
{
JObject jObjectResponse = JObject.Parse(stream.ReadToEnd());
var dto = jObjectResponse.ToObject<googleresponsedto>();
return dto.IsSuccess;
}
}
public class GoogleResponseDTO
{
[JsonProperty("success")]
public bool IsSuccess { get; set; }
[JsonProperty("score")]
public double? Score { get; set; }
}
[HttpPost]
public IActionResult ValidateV2(string token)
{
var res = Validate(token, _config.GetValue<string>("CAPTCHA_SECRET_KEY"));
return Json(new { Success = res });
}If the reCAPTCHA v2 implementation is successful, you’ll receive the following response from Google:
{
"success", // true|false success flag
"challenge_ts", // timestamp when the challenge was loaded
"hostname", // string - hostname of the site at which reCAPTCHA was solved
"error-codes": [...] // optional property in case of errors
}After that, reCAPTCHA will start filtering abusive traffic and collecting statistics on user interactions.
reCAPTCHA 3: frontend integration and backend validation
The client-side implementation of reCAPTCHA v3 is simpler and requires fewer actions from a developer. First, you need to add this script to your website’s front end:
<script src="https://www.google.com/recaptcha/api.js?render=YOUR_OPEN_SECRET_KEY" async defer></script>Then add this code to check a particular user activity:
grecaptcha.execute('YOUR_OPEN_SECRET_KEY', { action: 'homepage' }).then(function (token) {
$.ajax({
async: false,
method: 'POST',
url: 'Captcha/Home/ValidateV3',
data: { token: token }
}).done((res) => {
if (res.Success === true) {
// ...
}
});
});After that, interaction with the front end is over.
Backend validation of reCAPTCHA v3 is almost the same as with reCAPTCHA v2. The only difference lies in Google’s response: for reCAPTCHA v3, it also contains a score parameter. So the response from Google looks like this:
{
"success", // true|false success flag
"score" // number - the score for this request from 0.0 to 1.0
"action" // string - name of the action for this request
"challenge_ts", // timestamp when the challenge was loaded
"hostname", // string - hostname of the site where CAPTCHA was solved
"error-codes": [...] // optional property in case of errors
}If you see this response, you’ve implemented reCAPTCHA v3 correctly. You can also check out our implementation on the Apriorit GitHub page.
Conclusion
Using a CAPTCHA is a popular way to protect a website from abusive traffic. Despite being simple, familiar, and relatively effective, however, CAPTCHAs have some major disadvantages: they irritate users, don’t protect from machine learning and artificial intelligence algorithms, and may even violate user privacy.
reCAPTCHA is one of the most advanced CAPTCHA implementations. At Apriorit, we have an expert web development team that knows everything about building and protecting websites. Challenge them with your new project!
Have a question?
Ask our expert!
VP of Engineering


