 Skip to main content
Skip to main content
Recovering something that was considered lost for good sounds impossible. Yet that’s what data carving does. This technique is widely used for recovering deleted files and restoring valuable information from corrupted drives.
In this article, we explain what file carving is, focusing on logical data recovery. We also provide a step-by-step example of data carving and file recovery so you can try out this technique yourself.
Contents:
Recovering lost data
Recovering lost or damaged data is hard. There are many potential risks and issues you should be ready to deal with. Data recovery may be partial or even impossible if the data was corrupted due to the malfunctioning of the target device.
Even if the data is intact, recovering it in full may still be impossible if you have no information on the drive’s specifications. Or if a flash drive controller’s settings were reset, the drive simply won’t know what the size of a particular memory sector was or how many sectors the drive had.
Lost or deleted data can be recovered from a corrupted drive in two ways: physically or logically. In this article, we’ll focus on the logical acquisition of data, in which the image of a physical drive is analyzed with special tools, and the needed data is extracted from it.
Disk structure and data recovery
Knowledge of a disk’s structure is a must for successfully recovering data from a disk image. A drive usually has several partitions — regions that can be managed separately and are treated by the system as distinct logical disks. Usually, these partitions are created, resized, or deleted when installing an operating system.
The system stores all information about the location and size of each partition in a partition table. This partitioning information gives you an understanding of the amount of data in the drive image that should be treated as a single filesystem.
A filesystem is responsible for storing data in a structured way so that each file can easily be identified and retrieved. Each filesystem has its own rules for organizing partition space to store different objects (files, folders, symbolic links, etc.).
Filesystem metadata may also contain the deleted file’s name and information about the folder this file was stored in. If this information is unavailable, the file is called an orphan.

To get the number of partitions on a drive, a recovery tool should know which partitioning system this drive uses. Then for each partition, the carver needs to determine if that partition was formatted and if so with which type of filesystem.
Next, the recovery tool needs to obtain information about the filesystem itself. Depending on the particular filesystem structure, the tool needs to get the filesystem metadata to know where exactly the files were situated and where the starting clusters are. And if the data for a file isn’t stored as a contiguous chunk, the recovery tool should have information about all the clusters it occupies.
Once you have all the above-mentioned information, it’s possible to recover data from the filesystem’s memory. However, if there’s no filesystem metadata available, the only way to recover a file is to extract it from unallocated memory using data carving.
Efficiently manage and secure your data!
Implement solutions that improve data integrity, security, and accessibility by entrusting technical tasks to Apriorit data management experts.
Recovering files with data carving
What is data carving? Data carving or file carving is a forensic method used for reassembling files in unallocated space. Data carving allows for detecting and recovering files and other objects based on filesystem contents rather than a filesystem’s metadata and file structure.
How does data carving work? Data carving interacts with two types of unallocated drive spaces:
- Unused disk space — Space that was left empty when a new partition was created on a drive.
- Reused disk space — Empty space within a new partition that was previously used by another partition.
While the system treats both of these types of spaces as free space, partitions of the second type may still contain some file data even though there’s no metadata that can be used to find file locations. In this case, data carving is the only way to effectively recover data.
The data carving technique can be used in two scenarios:
- To recover lost or damaged files due to missing or corrupt directory entries. The possibility of fully recovering such files depends on the significance of directory entry corruption. In some cases, lost files can be recovered only fragmentarily.
- To recover deleted files. The ability to recover deleted files depends on two factors:
- Whether the filesystem contains information on the clusters where the files were stored
- Whether these clusters were overwritten with other files
For the sake of performance, the filesystem doesn’t wipe out a deleted file right away. Instead, it marks the clusters occupied by that file as free space. Therefore, data from the deleted file remains on the drive until it gets overwritten with the data of another file.
Most filesystems, including FAT, NTFS, EXT, and HFS, store files such that a particular file begins at the start of a cluster, and a cluster starts at the beginning of a physical sector, which is the minimum storage unit on a physical drive. The only exception to this rule is Advanced Format Drives working in 512-byte compatibility mode.
There are many data carving tools that can be used for file recovery, including:
Later in this article, we’ll illustrate the process of data carving using CGSecurity Photorec, which is part of the TestDisk project.
When trying to recover data, file carving tools usually look for file headers — the first few bytes of a file. In addition to headers, they can also search for:
- file sizes derived from the header
- fixed or maximum file sizes (for specific file formats)
- file footers (the last few bytes of a file).
If there’s no information on the clusters with the needed files or the partition’s filesystem, the partition is treated as one big chunk of unstructured data. In this case, data carving tools search for magic numbers — file signatures that correspond to a particular file format.
It’s noteworthy that data carving works best for recovering files of types that don’t change their size throughout their lifecycle, such as image, audio, and video files. Files that are smaller than the cluster size may be found by the file format signature and recovered completely. If a file occupies several clusters, the success of data recovery depends on the degree of filesystem fragmentation. Whenever a filesystem doesn’t have enough contiguous free space to write a file to, it splits the file into small fragments and places them in available free space. This is why the bigger the file, the lower the chance of recovering it completely.

Meanwhile, let’s talk about the most common challenges you may face when trying to recover a lost or damaged file with data carving.
Read also
Data Management Based on SQL Server: On-Premises vs Cloud Database
Navigate the decision between on-premises and cloud SQL Server deployments with confidence. Apriorit professionals share their experience with both approaches, showing the pros and cons of each one so you can make an informed decision about your software.

Data carving challenges
The most common data carving challenges are related to a lack of information on the size of the file that needs to be recovered. Here are three of the most frequent scenarios:
- The precise size of a file is unknown
- The file size needs to be calculated from different header fields
- File size information is unavailable because of the file format
Before recovering a file, a carving tool needs to determine where exactly it starts within the analyzed space. This process is pretty straightforward: the carver algorithm processes the code sector by sector, looking for file type indicators. Then it decides if a certain fragment looks like the beginning of a file of some known format. However, to properly extract the file, the carving tool also needs to know the exact size of the file. It must also know how to do basic parsing of the file header for each file format and determine the original file size.
Often, a file header contains explicit information on a file’s size. However, in some cases, the file size should be calculated from multiple header fields. And in the worst case scenario, the file format may be designed to be used for streaming and therefore won’t contain any information about the size of the file.
The most widespread file format that doesn’t contain information about the file size in its header is JPEG. Additionally, in most file formats, there is a footer that a carving tool can use as a marker of the file end. However, with JPEG files, there are no such footers at all.
As a result, carving tools have to invent alternative ways for detecting the size of JPEG files. For example, CGSecurity Photorec uses modified JPEG parser code to detect the end of the image to be restored. As long as the JPEG parser reads the data and doesn’t fail with an error, the data is considered to be part of the file.
One more size-related challenge is a limitation you should remember. Most data carving tools have a strict limit for the maximum size of a recovered file. While this prevents carvers from producing massive files, it can also make the recovery of extra large files impossible. So make sure to check the file size limitations of the tools you intend to use, especially if you plan to recover large pieces of data.
Now let’s see how data carving works in practice and take a look at a brief step-by-step illustration of this process.
A practical example of data carving
To demonstrate the way file carving works, we’ll try to recover drive information from a publically available source and describe our actions step by step. For this illustration, we’ll use the following tools and resources:
- A test image from the NIST website as the source for our example
- AccessData FTK Imager for converting data from the Encase format to a raw drive image
- CGSecurity Photorec for carving data from unallocated space
- A hex editor
Note: Photorec is part of the TestDisk project, so you need to download the whole Testdisk package to access it.
We used the 4Dell Latitude CPi drive image in the Encase format from the NIST website as our source data for carving. Therefore, you need to download two files: 4Dell Latitude CPi.E01 and 4Dell Latitude CPi.E02.
1. Converting the drive image
Since carving is only done to raw data, we need to convert our drive image from Encase to the raw disk(dd) format. To do so, we use the AccessData FTK Imager tool.
Open 4Dell Latitude CPi.E01 in FTK Imager by selecting File – Add Evidence Item – Image File.
Once you’ve opened the image, select the partition item in the Evidence Tree. Then choose the Export Disk Image… option in the context menu.
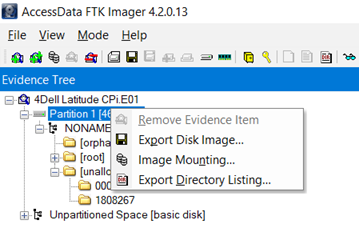
Next, add an image destination (Raw (dd)) and skip the case information dialog box. Then select the image destination folder and the file name. Set image fragment size = 0, since we want a single file, and press Finish.
Once the conversion is complete, there will be a 4.7 GB file representing the raw data extracted from a real drive. Offset 0 in this file represents sector 0 of the drive, and then the data goes sector by sector as it was stored originally.
The received drive image is an NTFS partition, the sector size is 512 bytes, and the NTFS cluster size is also 512 bytes.
Read also
How to Ensure SaaS Data Security with Curated Database Design
Protect your SaaS product with an effective and secure database design. Explore our valuable insights on the role of database structure in securing SaaS applications against rising cybersecurity threats.

2. Extracting data
Once we have all the data in a raw drive format, we can start the carving process. Using CGSecurity Photorec, we’ll extract data from the unallocated space of this image.
First, run qphotorec_win.exe and select the raw disk image as the media to recover from.
Then set the following options:
- file system type to FAT/NTFS/HFS+/ReiserFS/…
- search type to Free: Scan for file from unallocated space only
Now specify the folder in which to store the recovered files and press Search.
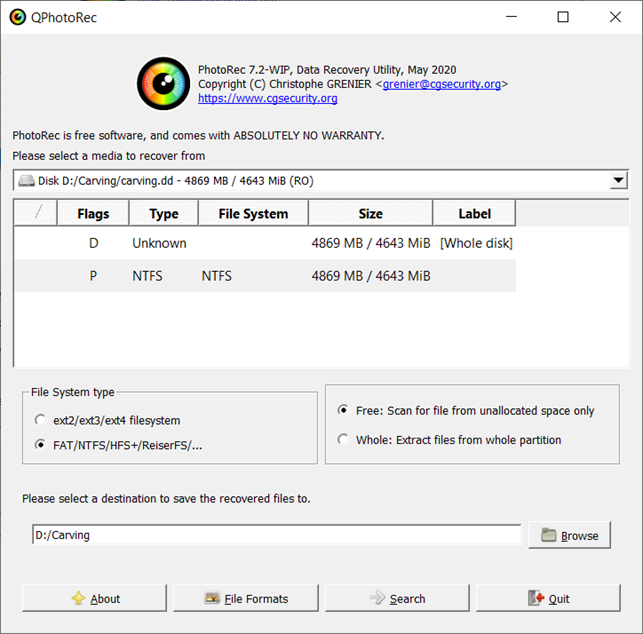
Files recovered from the unallocated space during data carving will be placed in the specified output directory. Photorec should be able to recover about 1010 files of various types from the source image we’ve used.
3. Validating the results
To make sure that recovered files were extracted from the unallocated space, we can search the drive image for a file’s content and then use FTK Imager to check which part of the partition each file belongs to.
For example, Photorec was able to partially recover a BMP file called f1289157.bmp (7 KB):

As you can see, only the bottom lines of the image are intact; all the other pixels are ruined.
Photorec names recovered files by the number of the sector where they were found, so f1289157.bmp means that the file can be found at sector 1289157.
If we open the drive image in the hex editor and go to the offset 1289157 * 512 (sector size) = 660048384 = 0x27578A00, we’ll find this file’s content:
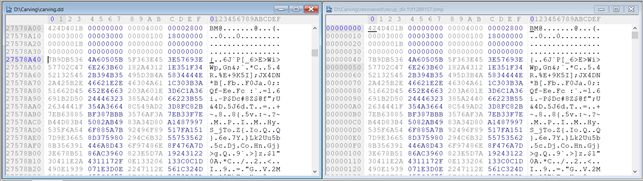
As described earlier, the BMP file’s data starts right at the beginning of the sector.
Next, let’s see what FTK Imager says about sector 1289157:
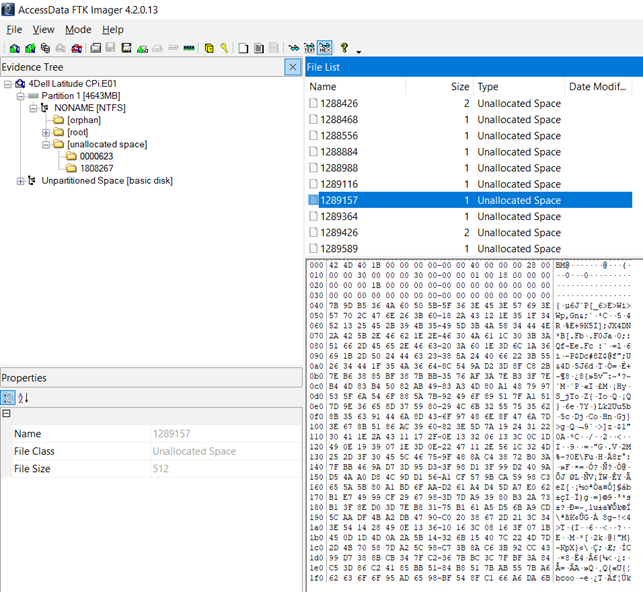
As you can see, it’s unallocated space within the partition.
Now let’s figure out why only part of the image was recovered and how Photorec determined the size of this BMP file.
Related project
Improving a SaaS Cybersecurity Platform with Competitive Features and Quality Maintenance
Discover how Apriorit enhanced a global SaaS-based cybersecurity platform by implementing competitive features and ensuring quality maintenance. With our help, the client managed to improve feature sets, achieve system stability, and boost user experience.

File recovery specifics
Photorec determined that the size of the recovered file is 6976 bytes by extracting this size from the header data:
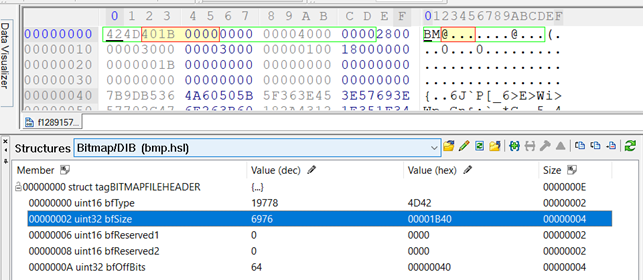
So Photorec assumed that there should be 13 more sectors with the file’s content and extracted the available data. And if we look at the next unallocated sector, we can see that it contains the same data as the recovered BMP file at offset 512 (0x200).
According to FTK Imager, the next unallocated sector is 1289364:
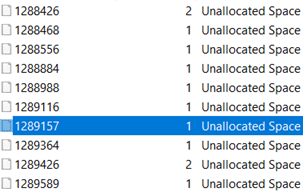
Let’s compare the contents of this sector to the contents of the recovered BMP file in a hex editor:
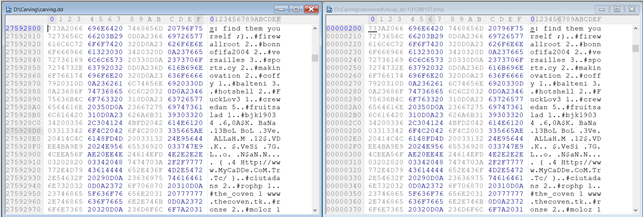
Indeed, the second sector in our recovered BMP file is 1289364.
Apparently, Photorec expected that the recovered BMP file would continue from the next unallocated sector. But the data extracted from that sector appears to be part of some text file instead. As a result, invalid data was added to the recovered file.
Where is the original content of the second sector that belonged to the recovered BMP file?
Most likely it’s been overwritten by a new file. Initially, the recovered BMP file was occupying 14 sectors, from 1289157 to 1289171. Then this file was deleted and the operating system marked its sectors as free space. The contents of the BMP file were intact up until the operating system decided to write a new file over the free sectors. Thus, sectors 1289158 through 1289363 were overwritten with new data. And sector 1289157, which contains the BMP header and several lines of the image, was the only sector that remained unchanged.
As for these several intact lines at the bottom of the image, the reason they were recovered successfully hides in the peculiarities of the BMP format. BMP images are encoded backwards, from bottom to top. Therefore, the first sector of a BMP file contains the file header and several bottom lines of image pixels.
Conclusion
Data carving is an effective technique for recovering deleted information from unallocated memory space. Depending on the state of the analyzed drive and the availability of filesystem metadata, file carving can enable full or partial recovery of deleted files. Yet carving is impossible if the unallocated space where the file was previously situated has already been overwritten with a new file. Successful carving is dependent on the format of the recovered files and requires having information such as the file header, topper, or size.
At Apriorit, we have a team of excellent data management professionals. Our specialists can effectively restore data that was considered lost. If you need to build a custom data backup solution that will prevent you from losing valuable data ever again, get in touch with us to start discussing your next project right away.
Ready to transform your data management approach?
Effectively manage and protect your enterprise data by involving Apriroit’s top engineers in your next project!
Have a question?
Ask our expert!
Program Manager


