 Skip to main content
Skip to main content

Custom remote repositories and remote helpers are two of the many useful extensions of the Git version control system (VCS). They allow developers to work on numerous new use cases for Git. But to get creative, developers have to understand how Git operates.
In this article, we overview Git’s internal logic and get acquainted with the set of internal Git utilities. We also discuss Git communication protocols and show you how to develop two simple remote helpers: one with a custom transport layer and one with custom transfer and storage logic.
This article will be useful for developers who are already familiar with Git and want to improve their knowledge of Git internals and their skills in developing custom remote helpers.
Contents:
What is a remote helper?
A remote helper is an application that helps Git implement custom communication logic with remote repositories (or simply remotes). Git runs the remote helper subprocess and communicates with it to operate a custom remote. It’s an alternative to standard communication protocols like SSH and HTTPS.
Here’s what the communication process looks like:
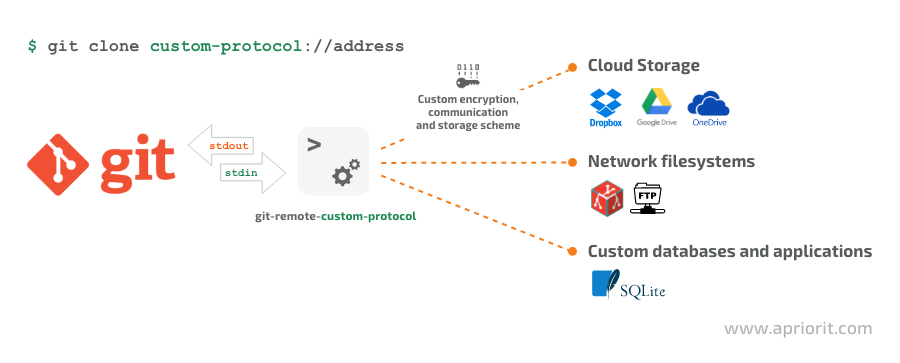
Figure 1. The process of communication between Git and custom remote storage using remote helpers
Remote helpers allow developers to implement various remote interaction scenarios with Git, including:
- integrating Git into cloud storage remotes
- performing end-to-end encryption while transferring repository objects
- storing a repository in an encrypted single-file storage (e.g. an SQLite database)
- interacting with other version control systems (e.g. a remote helper to interact with Mercurial repositories)
Before we start developing a remote helper, we need to study Git’s internal logic. We’ll need to know which objects Git uses to store a repository and which commands we can use to interact with the repository. In the next section, you’ll learn about Git objects and their types.
Git object database model
Git represents remote repositories locally in the form of an object model stored in the object database. The Git object database contains a set of objects with a certain type: blob, tree, commit, or tag. Objects are immutable and are identified with the hash of their contents (using a secure hash algorithm, or SHA-1). The Git object database has a file system representation in the Git directory — usually the .git folder in the repository’s root folder.

A blob object represents the contents of the file added under the current commit, except for the name and attributes of this file. They’re stored in tree objects.
A tree object resembles file system directories. This object stores a listing of directory entries. Each entry is represented with its object type (tree or blob), name, file access mode, and a reference to any corresponding tree or blob object. Tree objects may refer to other tree objects, forming a folder hierarchy.
A commit object points to the tree object in the working directory root. This object stores information about the author’s or committer’s identity along with the commit message. Subsequent commit objects refer to previous commit objects by their hashes to represent the commit history.
A tag object is created for annotated tags (-a option). This type of object refers to a particular commit object and stores information about the commit author, the timestamp, and tag message.
Here’s how these objects interact in a simple Git repository:
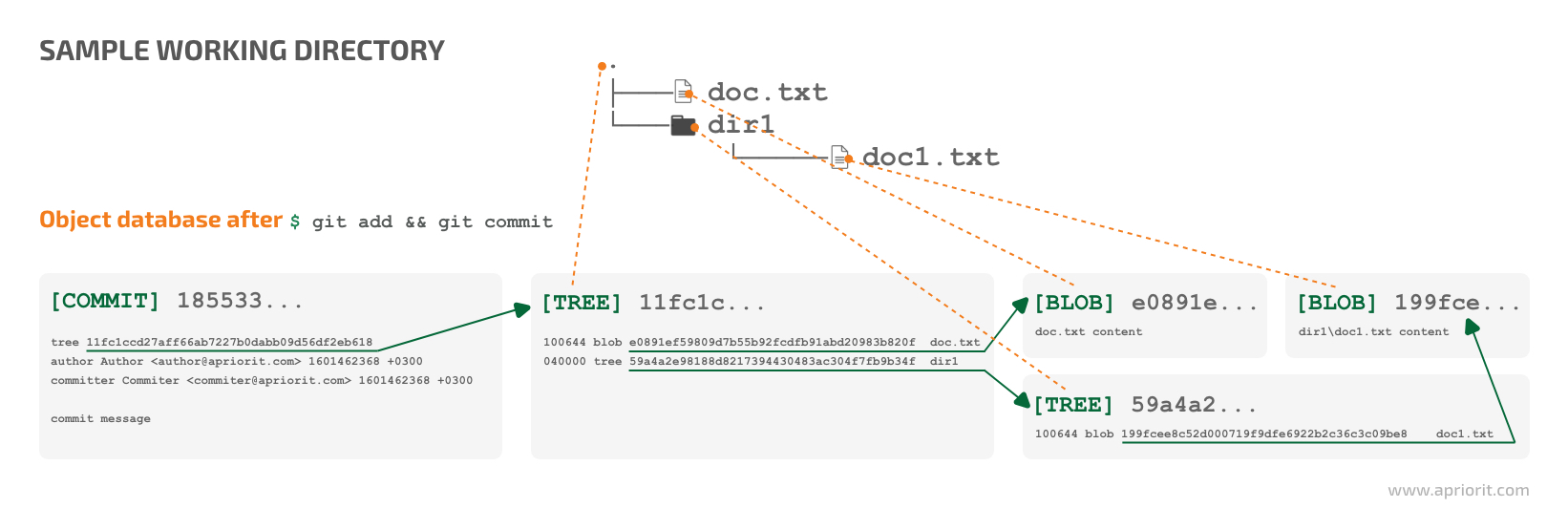
Figure 2. Object database state once the sample working directory is committed
When we execute the $ git add command in the sample working directory, Git will index the contents of the new commit and create a blob object to store the contents of added files.
Then, we execute $ git commit. It creates tree objects to represent the directory hierarchy. This hierarchy consists of tree objects linking the nested tree and blob objects recursively by their identifiers (SHA-1 hashes). After that, Git creates a commit object.
The new commit object points to a tree object that references a blob entry in the doc.txt file. A nested tree entry for the dir1 subdirectory also has a blob entry reference to the doc1.txt file.
Note that the Git object model works directly with file differences. Whenever we modify a file, Git creates a new blob object to store the file’s contents. Then Git recursively recreates parent tree objects to refer to the new contents of the changed file. Finally, when the change is committed, Git creates a new commit object that refers to the updated root tree and previous commit object.
For example, here’s what happens when we want to commit to the repository from the example above:
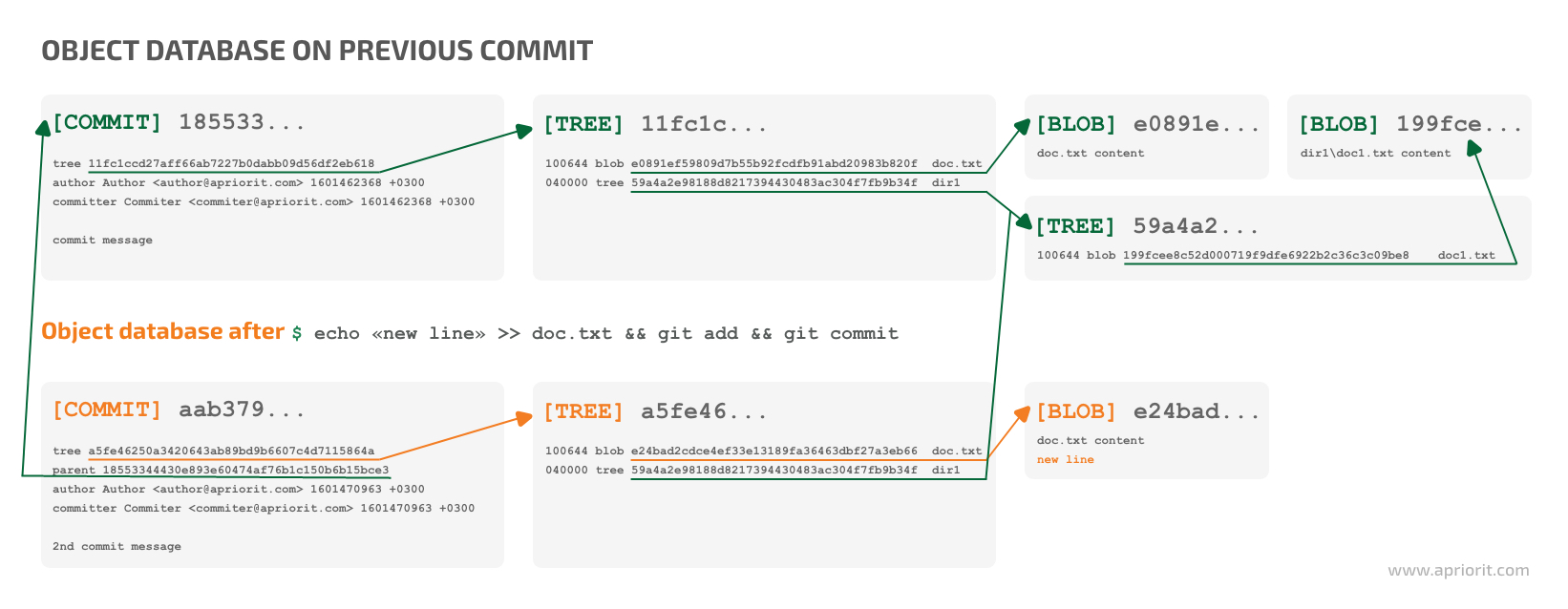
Figure 3. Object database state after the subsequent commit
As shown in Figure 3, Git creates a new blob to store the changed contents of the doc.txt file. Then, after executing $ git commit, Git creates a new tree object to represent the updated root directory content. This object still refers to the existing dir1 tree object and the new blob object. Finally, Git creates a new commit object which references the parent commit and points to the new tree object representing the root of the working directory.
Now we have the high-level vision of the Git object database model. Next, let’s see how Git represents these types of objects in the local object database.
Storing objects in the .git directory
Let’s take a look at the .git directory in the repository root to get a better understanding of the way Git stores the repository state. Knowing this will help us organize storage of the repository state on the remote:
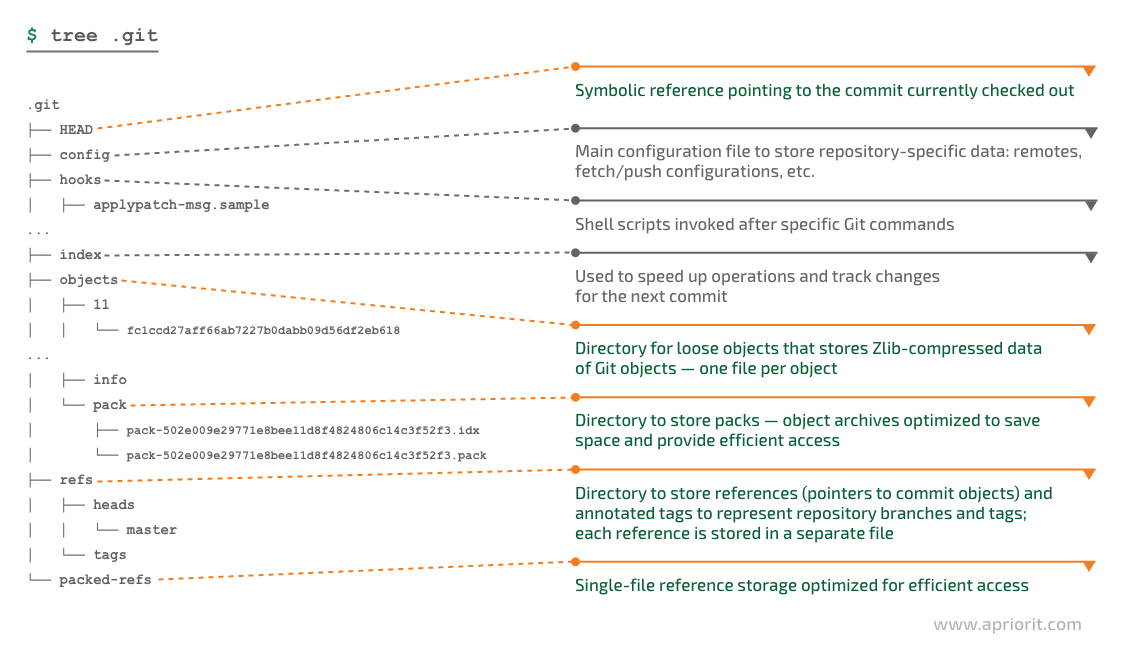
Figure 4. .git directory entries
The Git directory stores the following core entities:
- An object database is represented with loose objects and packfiles. Loose objects store zlib-compressed data of a particular object and are located in the .git/objects/ subdirectory. The name of a loose object corresponds to the first two characters of its SHA-1 hash, and the filename corresponds to the last 38 characters of the hash. Git usually creates loose objects when working on addition or commit operations with a local repository.
Packfiles are object archives optimized to save space and provide efficient access. They’re located in the .git/object/pack directory. Packfiles usually store large sets of objects fetched from a remote. Loose objects can be optimized into packfiles with the
git gccommand. Usually, some repository objects are stored in packfiles while others are stored as loose objects. - A reference is a pointer to a certain commit object or annotated tag identified by its hash. If you print the contents of the .git/refs/heads/master directory from a local repository, you can see that it contains a hash of the last commit the master branch points to. References are used to store Git branches and tag states. Tags are located in the refs/tags directory. Objects stored in the database are always immutable, but references can be altered.
Starting with version 2.30.0, Git provides us with a packed .git/packed-refs reference file, which is a single file containing information about a set of references. The
git-gccommand may perform reference packing to optimize access time, depending on the configuration. - A symbolic reference is a reference to an existing Git reference. Git sets a symbolic reference HEAD, located at .git/HEAD, to point to the checked branch. The symbolic reference file has the ref: prefix followed by the reference it points to. For example, if the master branch is currently checked out, the HEAD will contain the ref: refs/heads/master reference. However, when the HEAD is in a detached state (an arbitrary commit is currently checked out), the .git/HEAD file will be a regular reference pointing to a commit.
Manipulating the repository state
Now we can study how to read Git objects as well as reference and modify the Git repository state. Specifically, we need to access references, read objects from the database when fetching the changes from a remote, and add objects when pushing changes to the database.
You might consider accessing Git directory entities directly, but it’s an unreliable method. Git might change the storage model, causing the remote helper to corrupt the repository state.
Luckily, Git provides a rich set of utilities for managing objects and references. Let’s cover the core set of utilities needed for implementing a remote helper.
Object database utilities:
- Get object type:
$ git cat-file -t {SHA1} — This command prints the object type to the standard output (stdout). The return value is a blob, tree, commit, or tag object. This command can also help you check an object’s existence: If the object you request exists, this command returns a 0 error result.
- Read object:
$ git cat-file {type} {SHA1} — This command makes Git print the object to stdout. You need to pass the object type as the first argument to receive the object’s contents and read the binary representation of this object. You’ll need this information later to write the object to the database. Also, you can use the -p option to read and parse commit/tree objects when implementing internal logic.
- Write object:
$ git hash-object -w --stdin -t {type} — This utility computes an object’s SHA-1 hash. It writes the object to the database with the -w option, and --stdin forces Git to read the object’s contents from stdin instead of from a file. Without this utility, a remote helper would probably write an object on the fly while receiving it from a remote repository. Finally, it’s necessary to add the object type to the git hash-object command. If you don’t, this command will write a new object as a blob by default.
- Make a packfile:
$ git pack-objects --stdout — Pack-objects creates a packfile from the set of objects read from stdin. A remote helper passes object hashes to the utility line by line and uploads the resulting packfile it reads from stdout. Considering the number of objects in real repositories, it’s recommended to perform batch handling of database objects. It’s best to make a packfile rather than calling git cat-file for each object you upload.
- Import a packfile from the object database:
$ git index-pack --stdin — This command imports the packfile read from stdin to the object database.
References utilities:
- Get reference hash — The rev-parse utility takes a regular and symbolic reference and returns the hash of an object (commit or tag) it points to.
$ git rev-parse master
> 8fa6b3625bc9541acb6f104ea06260c2a2c49ea0- Get symbolic reference value — This utility is used to figure which reference HEAD currently points to. It returns an error message with a non-zero error code when HEAD is currently in a detached state.
$ git symbolic-ref HEAD
> refs/heads/masterObject relationship utilities:
- List objects referenced in a commit:
$ git rev-list --objects {COMMIT} — This command lists objects referenced in a commit, returning the hashes of all referenced objects line by line. It’s useful when preparing a list of objects in the repository history up to a given commit.
- Find object differences between two commits:
$ git rev-list --objects {NEWER_COMMIT} ^{OLDER_COMMIT} — This command looks for the differences in the objects of two commits. It’s useful to find a set of objects from a newer commit if the remote already has a set of objects referenced from an older commit.
- Check whether a commit is an ancestor of another commit:
$ git merge-base --is-ancestor {maybe-ancestor-commit} {descendant-commit} — Checks whether a commit is an ancestor of another commit. This command exits with error code 0 if the first argument commit is an ancestor of the second. Example: git merge-base --is-ancestor HEAD~1 HEAD will exit with status 0, while git merge-base --is-ancestor HEAD HEAD~1 will exit with status 1. This check helps to ensure you can update the remote reference value with the newer commit by checking if the remote commit is its ancestor.
All of the utilities we’ve discussed above are hard to grasp and remember at first. To see how they work in practice, let’s create a simple manual dump of a test repository.
Using Git utilities to create a manual dump of a test repository
We will create a remote helper that dumps objects from the local database, restores them to the remote, and updates the remote references. When changes are fetched, the helper will copy objects from the remote to the local repository database, thus updating the references.
Let’s use the set of commands we’ve already covered to make a manual dump of a test repository:
# Clone full history of the repository (objects for all remote branches are cloned)
git clone https://github.com/symfony/symfony.git original
cd original
# Create a directory for the dump
mkdir ../repo_dump
# Get hash of the commit HEAD references
HEAD_COMMIT=$(git rev-parse HEAD)
# Get hashes of all objects referenced from HEAD_COMMIT (objects referenced from other branches are skipped)
# `cut` is used to extract the first word from rev-list output, which is the object hash
git rev-list --objects $HEAD_COMMIT | cut -d' ' -f1 > objects_to_dump
# Create packfile to store objects to dump
cat objects_to_dump | git pack-objects --stdout > ../repo_dump/objects.pack
# Save the HEAD reference
echo $HEAD_COMMIT > ../repo_dump/head_refThen, we need to restore the custom repository dump:
# Create a directory for the new repository
mkdir restored
cd restored
# Initiate a new Git repository
git init
# Import the packfile from dump
cat ../repo_dump/objects.pack | git index-pack --stdin
# Reset the HEAD value to the dumped value
git update-ref HEAD $(cat ../repo_dump/head_ref)
# Check out the actual files to the working directory
git checkoutWith that, our custom repository dump is completed. With this knowledge of Git object types and utilities, we can move to the next important aspect of implementing a remote helper — communication protocols.
Standard Git communication protocol
Since version 2.1.4, Git has used the smart protocol to communicate with a remote. This protocol creates a packfile upon request and indexes it on the client side when fetching changes, or it sends a packfile with new objects and integrates it into the remote when pushing changes.
The protocol is implemented with the fetch-pack and send-pack utilities on the client side, which communicate with the send-pack and receive-pack utilities on the remote side. Git communicates with the utilities on the remote side through the SSH, HTTPS, or Git transport layers. You can check out the official Git documentation to learn more about transport and transfer protocols.
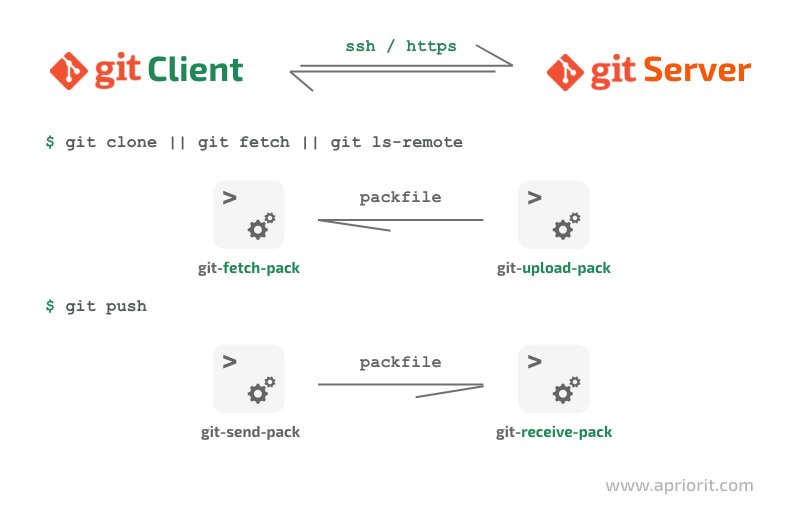
Figure 5. Standard remote interaction scheme
To communicate with a remote helper, Git uses a remote helper communication protocol. Let’s see how it works.
Remote helper communication protocol
Whenever Git needs to interact with a remote that has a non-standard protocol, it runs the git-remote-{protocol_name} application, where {protocol_name} is the transport prefix of the remote URL (e.g. protocol_name://path).
To communicate with the remote, Git passes the remote name and URL as arguments to the helper. Say you add a new remote with the $ git remote add newremote custom://address command and then push a branch to the new remote with $ git push newremote master. In this case, Git will try to find the git-remote-custom binary (which should be accessible with PATH) and run it by passing newremote custom://address as an argument. Also, Git sets the GIT_DIR environment variable so that a helper can use Git utilities.
Git communicates with the subprocess through stdin and stdout. It doesn’t use standard error (stderr) for communication because the output is passed by the remote helper directly to stdout. This characteristic of Git is also useful for logging.
Git sends commands to a remote helper line by line. The remote helper reads and interprets each command and then sends the response to stdout.
Let’s consider a set of commands to use in a remote helper to implement the push/fetch logic.
Capabilities is a command a remote helper must implement. A remote helper sends the set of capabilities it implements line by line with a blank line at the end.
Let’s take a look at an example of capabilities command execution:
> capabilities
< list
< push
< fetch
<The list command makes a remote helper fetch the references available on the remote and write the result to stdout line by line. Regular references are formatted like {ref_sha1_value} {ref_name} [optional_attributes]. Symbolic references have the format @{sym_ref_value} {sym_ref_name}. Enumeration ends with a blank line.
Here’s a communication example for list command:
> list
< 8fa6b3625bc9541acb6f104ea06260c2a2c49ea0 refs/heads/master
< 40bc14ab7874c57a59ca54abb444c66c0e083ce8 refs/heads/branch
< @refs/heads/master HEAD
<The list command can also be called with the list for-push option to notify the helper that Git is fetching references to prepare the push command. list for-push is handled in the same way as list but can be used to optimize the internal helper logic. For example, there’s no need to list the remote HEAD value when pushing changes to the remote. The remote HEAD value determines which branch is considered the default during branch cloning.
The fetch <sha1> <name> command requests the remote helper fetch the given object and all necessary objects to the database. Git can only request objects returned with the preceding list command. fetch commands are sent in batches terminated with a blank line, and the remote helper outputs a blank line once the command is handled.
Communication example of the fetch command:
> fetch 8fa6b3625bc9541acb6f104ea06260c2a2c49ea0 refs/heads/master
> fetch 8fa6b3625bc9541acb6f104ea06260c2a2c49ea0 refs/heads/master
>
<Note that you should fetch all necessary objects related to the requested object with a fetch command. As you can see in the communication example, Git requests a single fetch for the entire branch. It relies on the helper logic to fetch the set of objects we’ve covered earlier corresponding to git rev-list --objects {ref. Remote helpers must implement logic to figure out which objects already exist in the local database and which we need to transfer from the remote.
The push <src>:<dst> command pushes the given source marked with the commit / reference / symbolic reference to a remote branch. With each push command, the helper transfers a set of objects related to src which are missing on the remote, then updates the <dst> reference on the remote, ensuring an accurate transition.
Similarly to fetch, push commands are sent in batches: The batch ends with a blank line, and the remote handler outputs a blank line once the push sequence is finished. When executing force push is required, the + character may precede <src>. Upon executing such a command, the remote reference will be overwritten even if its value is set to an object that is missing locally or the remote reference isn’t the reference you’re pushing. If an object is missing, it means that someone has already pushed their own changes to the same branch.
Communication example with this command:
> push refs/heads/master:refs/heads/master
> push +HEAD:refs/heads/branch
>
<The connect <service> command establishes communication between the remote and the git-upload-pack or git-receive-pack service using the remote helper. The helper outputs a new line when the connection is established, forwarding stdin and stdout to the started service. Both git-upload-pack and git-receive-pack accept a repository path as an argument.
If the connection with the service can’t be established, the remote helper displays an error message to standard outputs and exits. If the connection with the service can’t be established but the remote helper supports custom interaction logic via push or fetch, the remote helper outputs fallback followed by a blank line.
Here’s an example of connect command:
> connect
< {binary communication according to the pack-protocol}Now, we have all the pieces we need to implement our own remote helper. In the next section, we create two helpers — one with a custom transport layer and another with custom transfer and storage logic.
Implementing a custom remote helper
There are several strategies to implement remote helpers — your choice of strategy will depend on the helper’s purpose. In this article, we’ll develop a remote helper with custom transport/authentication logic and a remote helper with a custom transfer and storage model.
Remote helper with a custom transport layer
When a remote helper uses the standard transfer protocol, it needs to implement only the connect capability. Remote helpers establish a connection with the remote using custom authentication, then call the git-upload-pack or git-receive-pack utility passing the repository path to the remote. Git interacts with the remote utility through the remote helper using the standard transfer protocol we mentioned above.
Let’s develop a simple remote helper with connect capabilities. The helper will use a bare repository located on the filesystem of the local machine as a remote repository.
The remote helper receives the remote URL with the second command line argument. The URL has the format custom_remote:///path/to/repository/. We will use this argument to extract the path of the bare repository in the local filesystem. We’ll use this repository as the remote. Then, we need to develop the communication loop according to the described protocol: The helper reads the command line from stdin and manages it.
When the helper receives the capabilities command, it returns a line with the connect capability followed by a blank line to indicate the end of the enumeration.
Upon execution of the connect command, the helper extracts the second word from the command line, which is the name of the utility to be run on the remote. Then, the handler outputs a blank line to indicate that a connection has been established and runs the utility Git requested on the remote (git-upload-pack or git-receive-pack), passing the path to the bare repository to work with it as the second argument.
The entire helper logic is implemented in the following bash script:
#!/bin/bash
>&2 echo Remote helper started with command line \'$@\'
>&2 echo Remote url is passed in second argument: $2
repo_path=$( echo $2 | sed 's/.*:\/\///' )
>&2 echo Using remote repository path $repo_path. Running the communication loop
while :
do
read line
if [ -z "$line" ]
then
>&2 echo Input command line is empty. Communication done
exit 0
fi
command=$(echo $line | cut -d" " -f1)
arg=$(echo $line | cut -d" " -f2)
>&2 echo Handling input command $command with argument $arg
case "$command" in
("capabilities")
echo connect
echo
;;
("connect")
echo
>&2 echo Running helper utility $arg on repository $repo_path
$arg $repo_path
;;
esac
doneTo execute this bash script, you need to add it to PATH and execute the chmod command. The remote helper script should be named git-remote-{protocol_name} where protocol_name is a transport prefix we will use in the remote URL.
Now, let’s check if our remote helper works. First of all, we need to create a bare repository to use it as the remote:
mkdir /tmp/remote_repo && cd /tmp/remote_repo && git init --bareThen, let’s push a test repository to the remote using the helper:
git remote add testremote connectstub:///tmp/remote_repo
git push testremote masterThe implementation of this remote helper seems quite easy, but keep in mind that it has a major restriction. We can provide our own authentication and transport mechanisms but we’re still using the Git transfer protocol provided with the mentioned utilities and the standard Git repository storage model. To customize the logic, we need to manually manipulate the object database. We can either manipulate separate objects or use packfiles to manipulate batches of objects.
These manipulations will take much more effort than implementing a simple remote helper. Let’s see how to add custom transfer and storage logic to the helper in the next section.
Remote helper with custom transfer and storage logic
Implementing custom storage and transfer logic requires providing the list, fetch, and push capabilities. Here’s how it works with these commands:
When Git requests the list, the helper reads the references available on the remote. If the list command is called without the list for-push option, the helper also returns the remote HEAD reference, as it’s used by Git to determine the default branch when cloning. You’re free to store references and repository objects in any way you want as well as to establish any connections with the remote.
For the push command, the helper reads pairs of local_reference:remote_reference. When the local reference is empty, Git requests to delete the reference from the remote. Otherwise, the remote helper has to push changes to the remote.
First of all, we have to figure out whether to allow the helper to execute push if the local reference isn’t preceded with the + sign that means force upload. The helper checks whether the object remote_reference points to exists in the local database.
If this object doesn’t exist in the database, somebody has already pushed newer changes and the end user has to pull these changes first. In this case, the remote helper notifies the end user about this via stderr and exits with an error code. Also, we must check that the commit the remote reference points to is an ancestor of the newer local commit to make sure that it’s a fast-forward transition.
Once the helper ensures that push is legit, it has to detect the set of local objects with the newer changes which are missing on the remote. This can easily be done with the git rev-list --objects command. We pass the local reference we push as the first argument to rev-list. Then we pass all the references available on remote with the ^- exclude sign so we can find the exact set of objects to upload. The helper reads the type and contents of an object by executing the git cat-file -t [SHA1] and git cat-file [TYPE] [SHA1] commands for each object from the list. After that, the helper uploads missing objects to the remote.
Finally, the helper must update the remote reference value. It’s important to guarantee repository consistency when updating references. This can be done with transactions if you store references in a database, semaphore or lock files if you store references in files, etc. The goal is to avoid two conflicting pushes to the same branch.
PUSH cases
1) Local reference is empty
> push :refs/branch_to_remove
Action: remove the given reference on remote
2) Force push
> push + refs/heads/master:refs/head/master
Action: upload objects referenced from the branch but missing on remote,
update remote reference without additional checks
3) Regular push
> push refs/heads/master:refs/head/master
Action: perform fast-forward check: ensure that current remote reference
is an ancestor of the local reference, fail otherwise;
upload objects referenced from the branch but missing on remote,
update remote referencThe fetch command requests the helper to download the requested object from the remote. Alongside that, it downloads all the objects it depends on that aren’t duplicated in the local database. Then, the helper writes them to the local object database.
To write the requested objects, you can implement recursive fetch logic: The helper downloads the requested object and writes it to the database with git hash-object. Then, the helper determines the object type with cat-file. Depending on the object type, the helper finds the objects it depends on and performs a recursive fetch for them:
- commit object for tag
- tree object for commit blobs
- nested trees for tree
A remote helper that can manipulate the object database manually allows you to add custom encryption and compression logic. It’s useful for storing encrypted objects on the remote, managing object access, etc.
You can check out the implementation of this logic in git-remote-dropbox. This helper downloads and writes dependent objects unavailable in the local database and recursively finds the objects they depend on.
Working with large repositories
We’ve described a straightforward approach to implementing remote helpers that you can consider as the starting point in forming your own solution. It works perfectly with relatively small repositories but may have major performance issues when working with repositories that contain a large object database.
For example, the gRPC repository object database contains more than 500,000 objects. Calling a Git helper utility for each object and downloading and uploading the objects one by one is major overhead. Depending on the storage model, you can overcome this overhead issue in two ways:
- By creating packfiles
- By implementing the libgit2 library
Read also:
How to Accelerate Microservices Development: A Practical Guide to Applying Code Generation
- Instead of reading objects and uploading them to the remote one by one, you can make packfiles of the object set when pushing changes and import packfiles to the local database when fetching changes. This approach greatly improves remote helper performance but has several downsides:
- You must consider Git compatibility with various versions of packfiles (currently there are two versions of the packfile format)
- The helper’s performance decreases with each push
- You might need to implement additional logic to repack small packfiles into large ones
- fetch involves downloading and indexing objects for the entire repository history (users won’t be able to fetch objects from a single branch)
- You can also use the open-source libgit2 library to manipulate the state of the Git repository. It provides an efficient way to read and write objects to the database, eliminating the need to run
git-receive-packutilities. It suits complex projects implementing custom transfer or storage logic.
Reference projects
Before you start working on your own remote helper, consider analyzing existing projects. Here are some notable implementations for you to pay attention to:
- git-remote-dropbox — This project implemented in Python stores loose objects on the remote side similarly to Git. The remote helper manipulates individual objects by running helper utilities.
- git-remote-gcrypt — This is a remote helper completely implemented in bash. It provides encryption on push/pull using GnuPG. It stores a packfile with new objects, then encrypts and uploads it to the remote when pushing the changes. Occasionally it may repack the entire repository to optimize storage access. This helper also fetches the entire repository history when cloning, as it doesn’t work with separate objects.
- git-remote-ipfs — This helper, written in Go, provides functionality to work with ipfs. It manipulates loose objects when pushing and fetching changes and can download a missing packfile if the remote filesystem contains a bare repository with packfiles.
Conclusion
A remote helper is a great extension mechanism allowing you to communicate with the remote and organize Git repository storage however you need. Depending on your task, there are many strategies to implement a remote helper using different capabilities, utilities, and third-party libraries.
If you have a challenging project in mind, feel free to discuss it with Apriorit experts in remote access and management solutions!


