 Skip to main content
Skip to main content
Microsoft SQL database optimization is a constant struggle for any project, and this is something that Apriorit tackles often as an R&D outsourcing company. The thing is, when developing an application, initially engineers tend to point all their attention towards actually writing the code, while performance takes the back seat. Often, performance problems are caused by the speed at which the data from the application is received. Some problems can creep past the MVP stage and only became apparent when your solution is fully released to the general public.
This is why it is necessary to estimate what problems could occur and try to fix them early at the design stage, or at the very least when optimizing the database query.
In this article we will look at techniques for Microsoft SQL server database design and optimization. We will explore how to improve database performance and see what problems we can avoid by applying optimization best practices for SQL server database design. While this article is based on designing database solutions for Microsoft SQL server, the majority of techniques can be applied to other relational databases as well, including custom ones.
Contents:
Database optimization methods
1. Indexes
Indexes are an essential part of Microsoft SQL database design, as they are the first thing that can help with optimization. However, despite being one of the best performance optimization techniques, it is necessary to remember that index creation can have its drawbacks. We need to understand how indexes work. Let’s look at the following points that arise when using indexes:
- Indexes are speeding up the SELECT operation that allows to read data from the table, but they can also slow down operations that allow to edit data, such as INSERT, UPDATE and DELETE. Therefore, before creating an index you need to understand the purpose of the table, and decide on performance of which operations you need to focus.
- When data inside the table changes, indexes start to work worse – their performance decreases. This happens because the fill factor of the index goes down, while the fragmentation goes up. Figure 1 shows index pages after their creation. Figure 2 shows how much the structure changes after only one row has been added, while Figure 3 shows how it would change if rows where added and deleted multiple times. As a result, we get empty pages that where not deleted as well as pages that were unevenly filled. Such fragmentation can lead to more read operations being performed with each query. In order to optimize such indexes, they need to be reorganized and rebuild. How can we rebuild indexes? This Operation is fairly resource-intensive which is why it is necessary to run it when the server load is minimal (most often at night). This doesn’t mean though, that we should run this procedure every night. Everything depends on how often we make changes to our table. Moreover, automatic index rebuilding and reorganizing can be implemented based on its structure. In order to do this, we need to use the sys.dm_db_index_physical_stats function. You can see detailed description with examples here.
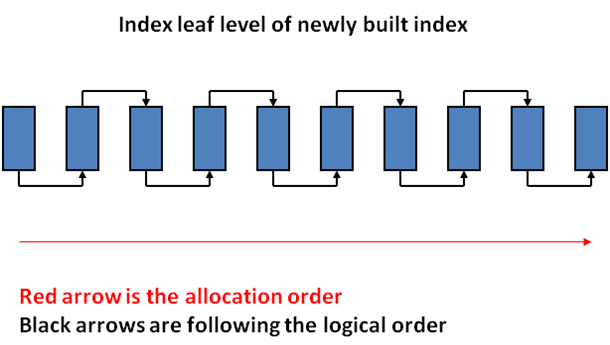
Figure 1. Recently created index pages
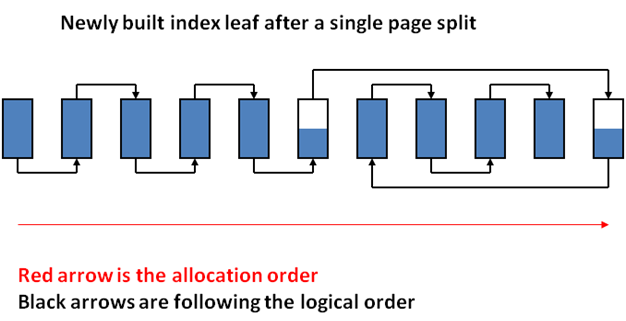
Figure 2. Index pages after adding data that caused a page to break in two parts
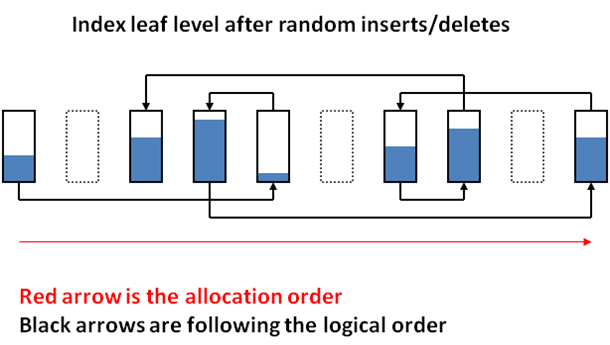
Figure 3. Index pages after adding and deleting multiple rows
- Use indexes correctly! Query optimizer will not use indexes if indexed columns are performing some kind of operations, such as calculations, functions, or type conversion.
For example:
SELECT * FROM [Products] WHERE [Quantity] + 15 >= 100In this case indexed field Quantity will not be taken into account when creating the query plan. Or rather, it will be taken into account, but optimizer will work with it via the Index Scan operation.
But if we tune the query in the following way:
SELECT * FROM [Products] WHERE [Quantity] >= 100 – 15Then, query plan will contain index passes with much quicker Index Seek operation.
- Right fields order in the composite index
When creating the composite index, order of fields is very important. Column that has the biggest impact on the query should be placed first. The best way is to use primary keys and unique fields. An index will be useful for all queries that involve either all columns of the index, or its first fields. For example, we want to search an account based on address (Zip and State):
SELECT ID FROM Accounts WHERE Zip = '76903' AND [State] = 'TX'Let’s create an index on Zip and State fields. Zip field allows for more precise selection.
CREATE NONCLUSTERED INDEX ix_Account_Address ON [dbo].[Accounts] ([Zip], [State])After that performance of the query will drastically increase and we will be able to see the index in use.
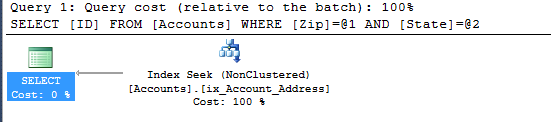
Let’s comment out the second part of the query, leaving only the Zip field. As a result, query plan will not change with regards to how it is performed and how our index is used.
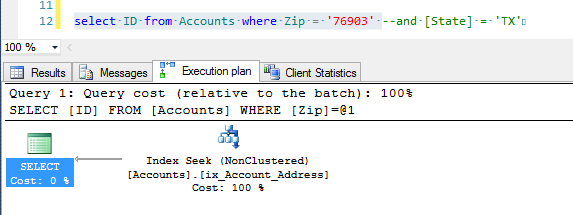
If, however, we leave only the second condition in our index, then the time to complete the query will grow because of the use of slower Index Scan operation to work with the index.

- Use indexes with included columns.
When using such indexes, performance increases because query optimizer can find all the necessary values in the index itself without the need to get data from the table, which leads to less read-write operations from the disk.
- Indexes are not always effective for small amounts of data. Sometimes, it is faster to read the table than search via index.
2. Changing the text of the query
- Using only the necessary fields
It is not always necessary to optimize the search procedure, performance of the query can also be achieved by reading the correct data. For example, we have a query:
SELECT * FROM Accounts WHERE Zip = '76903' AND [State] = 'TX'This query chooses all fields from the Accounts table. But if from all the data that we get via this query, we only need FirstName, LastName and Phone fields, we can rewrite the query in the following way:
SELECT FirstName, LastName, Phone FROM Accounts WHERE Zip = '76903' AND [State] = 'TX'And make query execution faster.
- Using the nested query
Nested queries are bad because often external query will use the data from the nested one, which does not allow query optimizer to parallelize the execution of different parts of the query.
- Using functions when it is not necessary
Often functions can be replaced with a much simpler and quicker query. For example, query:
SELECT * FROM Accounts WHERE LEFT(Phone, 5) = '11110'can be easily changed to
SELECT * FROM Accounts WHERE Phone LIKE '11110%'Moreover, such changes allow to use the index (if there is one for the Phone field).
- Do not use cursors if they are unnecessary.
Cursors allow to process rows one at a time. Each time we get access to the next row of the table we perform read operation. Because of the large number of operations, they often demonstrate poor performance.
- Query hints.
You can put certain instructions for the optimizer in the query text itself, stating what indexes to use and how to join tables (WITH and OPTION operators). But index chosen by you will not always be better than the one that the optimizer has chosen. When creating a plan, optimizer tries to find the best way to execute the query. By stating a certain index or join type you will save it time on searching for such a best way, but it does not necessarily mean that the way you have chosen is the best. This is why it is necessary to handle hints with care. Additionally, WITH(NOLOCK) hint needs to be mentioned. This hint will definitely decrease the time of the query, because it allows not to wait until resources are freed up, but you can get invalid data. If the table that you want to get data from is updated in any way, then with NOLOCK hint you will get the data, but it may differ from the one, that will be received after the table has been updated. This is something that you need to keep in mind before using this hint.
Read also:
Caching Techniques in ASP.NET
3. Changing the database structure
Database structure can either increase or decrease performance of the queries. Data reading speed depends on how we store it.
- Primary key
Primary key is a table object that is used to decidedly distinguish one data from the other in the table. This field has the best selectivity coefficient, because it is unique throughout the whole table. This is why MS SQL Server creates default clustered index for the primary key. As a result, getting the primary key data is almost instantaneous.
- Working with big data
As we already said, reading data can affect performance. Another reason for this is a query for large amounts of data. For example, html code of static website pages, or images of the goods on the site. In order to reduce the need to unnecessarily spend resources on reading such data, we can move those fields to the separate table. And a result we will get the following structure:
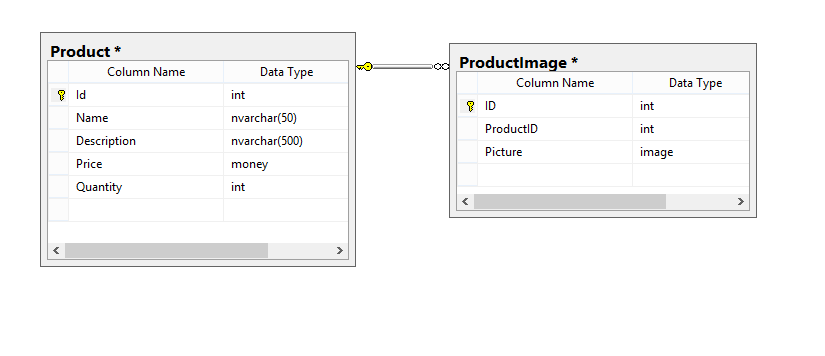
As a result, we get this data from the ProductImage only when they are actually needed (when we actually want to use them).
- Storing calculated fields
There are times when it is necessary to get processed data, or to do some calculations on it. For example, in order to display the price of the item with taxes included. If there are a lot of data, then spending resources on calculations can be prohibitive. In this case such calculations can be stored in a table and recalculated only in case the values of each individual element have changed.
- Database denormalization
Working with normalized database is not always effective. When you need to merge 5-6 tables in order to get the necessary data, it is time to think about denormalization. It supposes merging some tables to allow faster access to data. But before doing this, you need to carefully assess all pros and cons.
4. Caching and reuse of query plans
Queries are always executed in 2 stages:
- Creating a query plan
- Executing a query using said plan
Query plan is stored in cache and if the same query has been run second time, cached version of the plan will be used in order to considerably speed-up execution time.
Cache can store both plans for queries that are executed on a regular basis, as well as those that had been run only once. It is all depends on the buffer pool size. The pool can be cleared if necessary. Cache can be cleaned manually, or automatically by Database Engine. When Database Engine needs to add new plan, it looks for old plans that require less resources to execute and replaces them.
Moreover, you can control the size of the buffer. It can be done by changing the max server memory parameter in the sp_config procedure (https://technet.microsoft.com/en-us/library/ms188787(v=sql.105).aspx).
By knowing how cache works and how queries stored in cache work, you can easily improve queries performance by saving time on creating new query plans each time.
Tools for checking query optimization effectiveness
In the end I wanted to cover tools that can be used to check whether query optimization was successful (whether the query execution has been faster or not).
Time Statistic. In order to always track query execution time, you can turn on Time statistics and receive execution time in milliseconds. In order to turn it on, you need to execute the following command:
SET STATISTICS TIME ONYou can read more information about it here:
Client Statistics. SLQ Server Management Studio also has built-in statistics. Client Statistics can show not only how much time particular query took, but also the number and type of operations that have been performed in a query, as well as the size of data that has been processed.
You can read here how to turn on and use Client statistics in SQL Server Management Studio:
While statistics is turned on, it accumulates data from query to query and in the end we can see how effective particular optimization method was for a particular query. But keep in mind, that queries are stored in cache, thus, it is best to run a single query several times and look at the median results. For example, you should run unoptimized query three times in a row, and run it for three times after the optimization, and only after that you can compare your results.
SQL Server Profiler. This powerful SQL Server tool helps to detect queries that execute very slowly and use large amounts of memory. Moreover, it allows to filter queries that you want to analyze. The tool connects to database and gathers all the necessary information about each query. All the data is saved in a trace file that can be analyzed later.
You can read more about SQL Server profiler and how to use it in Microsoft documentation.
Summary
Microsoft SQL server database design and optimization requires a clear understanding of how the main database objects work, how optimizer affects Microsoft SQL database optimization, why we need indexes and what goes behind standard procedures and commands of an SQL Server. All of this data can help to not only fix vulnerabilities associated with optimization, but also to prevent them early at the database development and script writing stages.
Useful links
Reorganize and Rebuild Indexes – https://msdn.microsoft.com/en-us/library/ms189858.aspx
Query Hints – https://technet.microsoft.com/en-us/library/ms181714(v=sql.105).aspx
Plan Caching – https://technet.microsoft.com/ru-ru/library/ee343986(v=sql.100).aspx
Have a question?
Ask our expert!
Program Manager


