 Skip to main content
Skip to main content
Outages are deadly for any service or application because customers usually don’t stick around waiting for you to fix the problem. So when building a new solution, you normally try to predict as many security and performance issues as possible and mitigate them at the development stage. The problem is that it’s quite difficult to address all potential failure scenarios during development.
This is where a new approach, failure testing, comes in. Failure testing allows you to address problems that occur after moving the application to the production stage. It’s aimed at deliberately causing your platform to fail in order to see if it can handle new problems effectively.
In this article, we explain how failure testing works and look closely at cloud services based on the Failure as a Service approach.
Contents:
Failure testing: looking for weak spots
Failure testing is an approach that allows you to discover weak spots that can possibly lead to outages of cloud services. The basic principle of failure testing is chaos engineering — a method of introducing controlled disruptions into a cloud platform in order to identify its weaknesses and make it more resilient and fault-tolerant.
Trying to make your SaaS platform fail on purpose is necessary because of the tremendous number of unknown real production scenarios where your disaster recovery plan might not work. When you inject real failures into the platform, you can see if it can handle these issues effectively, without any outages and downtime.
Here are some examples of possible controlled disruption experiments:
- Stopping or rebooting virtual machines (VMs)
- Crashing Docker containers
- Creating additional latency between services
- Simulating the failure of third-party APIs
- Removing particular network services or routers
So what is Failure as a Service (FaaS) then? Basically, it’s a cloud service that implements the failure testing approach in real deployments.
FaaS is one of the commonly used product names for failure testing solutions. But you can also see these solutions referred to as Resiliency as a Service or controlled disruption.
It’s noteworthy that failure testing is an emerging paradigm that hasn’t been standardized properly. Therefore, there’s no common architecture for FaaS, even though there are several opinions about what a basic FaaS architecture should look like. In the next section, we take a closer look at one such architecture.
A basic FaaS architecture
A group of researchers from the University of California at Berkeley has offered a basic FaaS model for introducing common failures into large-scale distributed cloud services. This architecture includes three main components:
- FaaS controller — A fault-tolerant service that sends failure commands to the agents that run in VMs
- FaaS agent — An agent that runs on the same VM as the tested service, receiving failure commands from the controller and initiating controlled disruptions
- Monitoring service — A tool that monitors the behavior of target services and gathers information needed for creating failure drill scenarios and specifications
You can see what the proposed service architecture looks like in Figure 1 below.
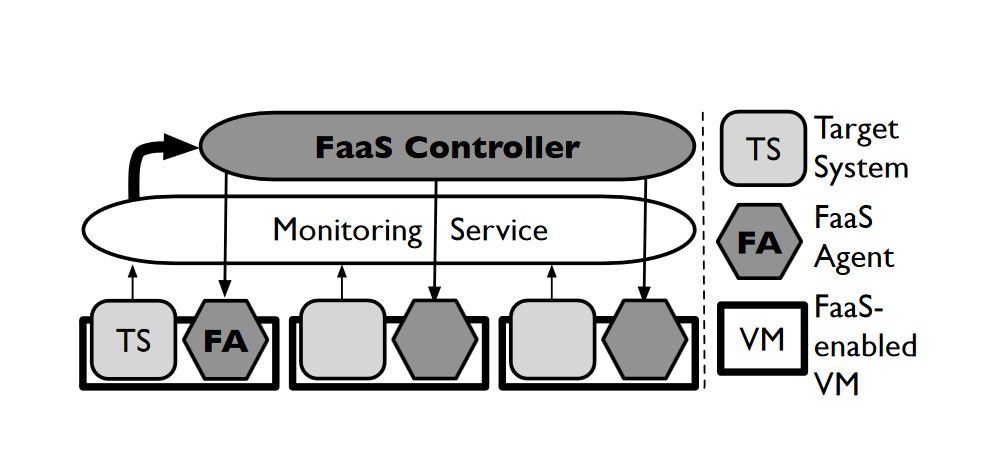
FaaS engineers control disruptions in the system via a set of carefully designed experiments. Each experiment recreates a potential failure, allowing you to analyze the system’s behavior and determine the most effective ways of handling this particular issue. In this way, you can constantly improve your disaster recovery program and significantly shorten the time needed for system recovery if one of these failures were to occur in real life.
Since failure testing is based on the principles of chaos engineering, the process of running such failure drills may consist of the following steps:
- Define the normal state or behavior of the target system.
- Introduce a disruption similar to real-world events such as a server crash or network connection failure.
- Watch the performance of the target system and see if it can stay stable while the failure drill is running.
Ideally, the performance of the target system should remain stable despite the disruption. If it fails to handle the issue, then you’ve found a weakness that needs to be taken care of in order to avoid future outages.
Failure as a Service tools
Chaos engineering techniques aren’t used widely yet. However, some large enterprises such as Netflix and Amazon have already deployed the failure testing approach to improve the performance of their services and make them more fault-tolerant. Here are the three most famous FaaS tools that can be used for injecting failures and testing the resilience of production systems.
Chaos Monkey
Back in 2011, Netflix introduced Chaos Monkey, an open source tool that can be configured to randomly knock down AWS resources at a scheduled time so that all failures can be monitored closely. The main goal of this tool is to detect system weaknesses that can cause major outages and address them at an early stage.
While Chaos Monkey doesn’t run as a service, it can be deployed manually by other cloud service users. Chaos Monkey is now a part of the Simian Army — a set of testing tools that were created for simulating various system failures and testing AWS infrastructure.
The main problem with Netflix’s Chaos Monkey is the randomness of failure drills. It’s very difficult to properly measure something that launches randomly and to handle the outcome of these random failures. Chaos engineering, on the other hand, is all about controlling these designed disruptions and minimizing the blast radius so you don’t cause any more harm than necessary.
In 2014, Netflix tried to solve the control problem by creating a specific tool for automated failure testing — Failure Injection Testing (FIT). However, FIT is an internal tool created for Netflix developers, so it can’t be used by others.
Gremlin
Gremlin is a framework that can simulate real outages and test the resilience of production systems. The framework targets three attack vectors:
- Resource exhaustion (memory, CPU, disk space, I/O)
- Network issues (black holes, latency, etc.)
- Behavior-related issues (terminated processes, rebooted instances, time drifts, etc.)
Gremlin can be installed on physical and cloud hosts as well as in Docker containers.
Trouble Maker
Trouble Maker is an open source project for performing failure testing on Java-based web applications and microservice platforms. The tool injects four types of failures:
- Terminated services
- Increased API loads
- Memory overload
- Exception handling
Trouble Maker can run tests at scheduled periods or on demand.
Main pros and cons of failure testing
Just like any other analysis approach, failure testing has its benefits and disadvantages. Here are some of the most important benefits of using controlled disruption for hardening your platform against performance issues:
Analyze real system behavior — There’s no place for assumptions in failure testing. You can perform a particular failure drill and analyze the system’s reaction to it in real life.
Control the damage — Since all failure drills are introduced as part of a controlled experiment, you have the power to stop the experiment once an issue is discovered and thus minimize the blast radius.
Build an efficient disaster recovery plan — Knowing how your application performs under particular failure drills allows you to address the discovered problems before they cause any serious damage. Having a disaster recovery plan that covers as many issues as possible also helps you save time and money when dealing with a real system outage.
At the same time, there are several challenges that developers need to overcome when building a Failure as a Service solution.
Data safety — This is one of the main concerns related to running controlled disruptions. Is it really possible to simulate the loss of customer data while still ensuring its protection? Wouldn’t a temporary disruption of a particular service be considered an SLA violation? These questions put at risk the use of chaos engineering methods in real deployments.
Outage duration — By introducing certain failures into the platform, you deliberately try to break it and see if it can remain stable no matter what. At the same time, it’s important to make sure that the platform won’t face any long-time outages when a major problem is discovered, so a FaaS solution should be able to restore a stable version of your product shortly after halting the injected failure.
Costs — Failure as a Service development is associated with increased costs. Cloud computing for large-scale applications is expensive as it is, and targeting such resources as network bandwidth or raw disk storage will only increase the cost of the service.
Result analysis — To address a discovered issue, you need to understand why it appeared in the first place and what can be done to solve it. But uncovering the chain of system problems that started by a particular outage and resulted in a particular service failure, then developing an efficient algorithm for handling large-scale failures can be quite a challenging task. There are too many factors you need to take into account in order to ensure stable performance of your platform.
FaaS experiments vs penetration testing
While the idea behind FaaS experiments may sound similar to the idea behind penetration testing, there’s a significant difference between them.
The main goal of FaaS is to ensure stable performance of your platform and help you develop an effective recovery strategy for handling different performance issues. Therefore, failure testing experiments are aimed at recreating possible failures of the main production system components and resources. There are so many factors that can affect the performance of the production system: the number of users can increase significantly, one of the load balancers may fail, and so on. Chaos engineering allows you to find weak spots in your application and develop the most effective disaster recovery strategy for each of these problems.
The main goal of penetration testing, on the other hand, is to protect your product from being compromised by hackers. Penetration testing checks your solution for any exploitable vulnerabilities that can be used for cyber attacks. This approach tests how the system responds to the most common attacks and explores weak spots that hackers may use to compromise your application.
Therefore, engineering controlled disruptions into your system cannot and should not be used as a substitute for penetration testing. This approach is meant to only complement, not replace, penetration tests.
Conclusion
Failure testing is a promising approach that might help developers ensure high-level, stable performance of their cloud-based applications even when they’re already in production. It leverages the principles of chaos engineering and exercises large-scale online failures of cloud service resources.
FaaS solutions show a lot of promise for improving the performance of cloud services and applications, as they can help developers fix emerging problems before they cause any significant damage.
At the same time, FaaS solutions should not be seen as an alternative to other testing solutions, especially penetration testing. Since these two approaches pursue different goals, they can complement but not substitute each other.
Have a question?
Ask our expert!
VP of Engineering


