 Skip to main content
Skip to main content

AI chatbots have gained popularity among businesses, allowing them to interact with users in a human-like manner, fulfill requests, and handle even complex inquiries.
Yet, despite their undeniable utility, AI chatbots inherit limitations of the large language models (LLMs) that power them. LLMs often struggle with retaining context and providing accurate responses without adequate training and sufficiently detailed prompts. Failure to address these challenges can diminish a chatbot’s efficiency and lead to customer frustration — and, ultimately, a negative return on investment and damage to a business’s reputation.
In this article, you will learn how to build and customize truly smart, context-aware AI chatbots using Python and the LangChain library. We’ll explore the common challenges of LLM integration and show effective solutions through practical examples. This article will be useful for developers and leaders seeking to build user-friendly AI chatbots for their businesses.
Contents:
Challenges in building context-aware chatbots with LLMs
Smart AI chatbots are able to process natural human speech and respond with relevant information, often serving as virtual assistants and support agents. They rely on large language models to comprehend queries and engage with humans in a natural way.
You can think of an LLM as a chatbot’s brain. It’s an elaborate neural network that uses big data and complex algorithms to understand requests and generate answers. Most popular LLMs are based on the Generative Pre-trained Transformer (GPT) model — a transformer-based neural network that is trained on big data and designed for analyzing and generating text.
Although GPT-based LLMs are highly advanced, you may still encounter challenges (such as security issues) when using them for chatbot development. In this article, we focus on challenges connected to a chatbot’s answers, context memory, and user experience.
LLMs cannot remember conversation history
LLMs have a good understanding of data from their training databases, but they don’t update their knowledge with new information after they are trained. As a result, their knowledge is frozen at the point of deployment. This makes LLMs unable to understand the conversational context of requests, as they can’t add conversation history and user messages to their knowledge pool.
This influences the user experience; a user needs to repeatedly provide context during each conversation, leading to dissatisfaction. Moreover, without the ability to adapt and learn from new interactions, LLMs may struggle to provide accurate responses in dynamic or evolving scenarios. An example may be a customer support chatbot that continuously asks a user for details they already provided.
It’s challenging to add new data to a pre-trained LLM
Because of the size and complexity of an LLM, it can be extremely hard to add new knowledge to it after training. LLMs often contain millions or even billions of parameters, and re-training or fine-tuning such models with new data requires significant computational resources, powerful hardware, and lots of storage.
In addition, it’s a very time-consuming process, as you need to:
- Ensure the training data is consistent and of high quality
- Feed a new dataset to the model
- Adjust the model’s parameters
- Run multiple training iterations for optimal performance
The inability to easily update or fine-tune an LLM with new data means that a chatbot’s knowledge and capabilities may quickly become outdated. As a result, the chatbot may struggle to keep up with evolving user needs, industry trends, or changes in business processes. Therefore, your business may find itself constrained in terms of adding new functionality or expanding your chatbot’s capabilities.
Want to power your business with a smart chatbot?
Discover how we can adjust a custom solution to your business needs and requirements!
An LLM’s responses may not correspond to a business’s intended tone of voice and behavior
LLM-generated responses often lack nuance and emotion, looking rather raw and overly formal despite being grammatically correct. While your business likely has a specific tone or style in which you speak to your target audience, a chatbot’s communication may seem impersonal and generic, influencing your customer engagement and resulting in a poor user experience.
Another issue is the level of detail that LLM-generated responses provide. In some cases, answers may be too wordy and full of unnecessary information, while in others, they may be too concise.
Fixing these issues requires additional fine-tuning so your chatbot brings the maximum return on investment through a great user experience and efficiency.
LLMs may give inaccurate answers
Sometimes, LLMs provide inaccurate information. This stems from various factors, each contributing to the potential for errors in the generated text:
- Lack of true text comprehension. LLMs do not understand the meaning of the text they process and generate. Their comprehension is based on patterns and structures, but they have no real semantic understanding to verify the accuracy of information and discern context.
- Poor-quality datasets. If the dataset for LLM training contains contradictory information, errors, inconsistencies, or fictional content, the LLM may inadvertently learn and propagate inaccuracies.
- Complex or obscure prompts. When presented with ambiguous queries or tasks that demand extensive knowledge or analysis beyond the scope of its training data, an LLM may struggle to generate coherent or accurate responses. The phenomenon when LLMs generate text that is not based on reality but rather on statistical patterns observed in training data is called hallucination.
The solution is to build your chatbot with reliable LLMs trained on high-quality data.
Now, let’s look at solutions Apriorit experts offer to ensure your chatbot remembers context, has the ability to evolve and learn, and adds your business’s unique tone of voice to its answers.
Read also
Top LLM Use Cases for Business: Real-Life Examples and Adoption Considerations
Explore how a large language model can transform your business and help you stay ahead of the competition!

Preparing the project: LLM implementation and chain options
Before we move to practical examples of dealing with typical LLM issues, we need to create a chatbot. Most businesses use ready-made LLMs for their chatbot development, as creating custom LLMs from scratch requires an immense amount of resources and expertise. Choosing an existing LLM for your solution is the optimal course of action if you need a simple and effective chatbot.
One of the most popular language models is GPT from OpenAI. We’ll demonstrate how to build your own chatbot using the LangChain library in Python and GPT-3.5.
To access the OpenAI API securely, you’ll need to manage authentication credentials. This can be done with the dotenv library, which will allow you to secure the API key and other sensitive information as environment variables in a .env file. You can learn more about accessing the OpenAI API here.
Here’s a step-by-step demonstration of how to import an OpenAI language model for your chatbot:
- Install the LangСhain library in your Python environment.
- Use the dotenv library to load your authentication credentials from the .env file.
- Paste the code snippet provided below into your Integrated Development Environment (IDE) to import and initialize the OpenAI LLM for your chatbot.
from os import environ
from langchain_openai import OpenAI
from dotenv import load_dotenv
if not load_dotenv():
raise RuntimeError('Failed to load .env file')
openai_api_key = environ['OPENAI_API_KEY']
llm = OpenAI(openai_api_key=openai_api_key)
response = llm.invoke('Hello! Explain shortly what is large language model in AI.')
print(response)Here’s the output we get after importing:
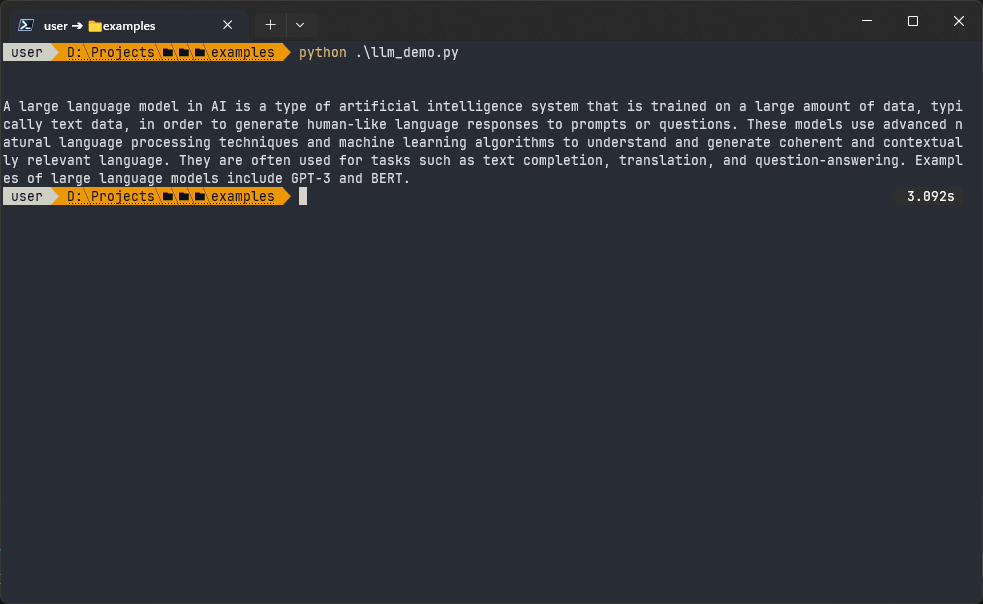
That’s it! Now we have a working LLM-based chatbot, and we can start improving it by addressing the issues discussed in the previous section.
To simplify and automate our work with an LLM, we’ll use chains — modules that connect different library components and create structured lists of actions or operations. For example, a chain can automatically extract and collect data to the prompt, which is then sent to the LLM. In our example, we’ll use these two chains:
- ConversationChain — automates loading context
- RetrievalQAWithSourcesChain — automates loading context and retrieving additional data from an external knowledge base
Now, let’s address each development challenge we’ve listed one by one. We’ll start with enhancing the LLM’s memory so it can remember conversations with users and better understand their context.
Read also
Rule-based Chatbot vs AI Chatbot: Which to Choose for Your Business
Discover the business value behind AI- and rule-based chatbots in our article! Gain valuable insights into how each approach can enhance customer interactions and drive engagement.

Improving conversation memory
Conversation memory is an important part of a chatbot’s functionality, as it directly influences the user experience — many users will find it irritating to repeat information.
An out-of-the-box chatbot, however, has issues with remembering conversations. As an example, have a look at this code:
msg1 = 'Hello! My name is Bob.'
resp1 = llm.invoke(msg1)
print(f'- {msg1}\n{resp1}')
msg2 = 'What is my name?'
resp2 = llm.invoke(msg2)
print(f'- {msg2}\n{resp2}')We’d expect the answer “Your name is Bob”, or something similar, but our chatbot provides this response:
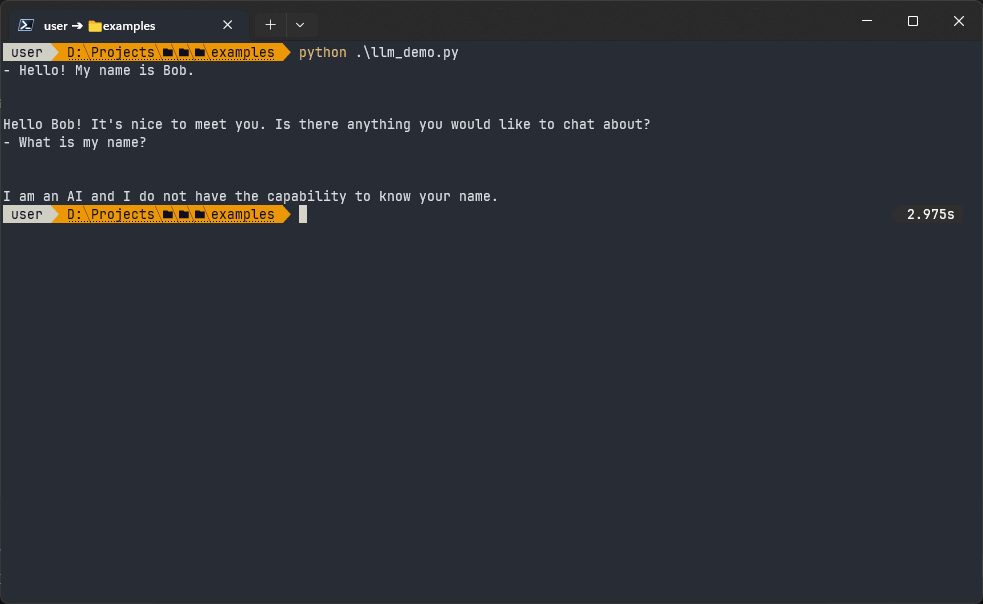
As you can see, the LLM doesn’t understand the context of the conversation.
One of the easiest ways to solve this problem is to use prompts — particularly, by putting the conversation straight into a prompt. There are several approaches to using prompts, also referred to as memory types.
| Memory type | Pros | Cons | Use cases |
|---|---|---|---|
| Buffer memory | Easy to use | Not suitable for long conversations; takes up many tokens | Customer supportLegal assistanceEducationPersonal therapy |
| Summary memory | Takes up fewer tokens compared to buffer memory | May omit some conversation details | Travel planningHealthcarePersonal assistance |
| Entity memory | Provides context-aware personalization | Accuracy highly depends on the entity extraction process | Personal financeTravel bookingJob search |
Let’s look at these memory types in detail.
Option 1. Buffer memory
The main idea of buffer memory is that the conversation history is put directly into the prompt without any changes. In the LangChain library, it is represented by the ConversationBufferMemory class. Let’s look at how this works in code:
from langchain import memory
from langchain.chains import ConversationChain
from langchain_openai import OpenAI
from dotenv import load_dotenv
if not load_dotenv():
raise RuntimeError('Failed to load .env file')
llm = OpenAI()
mem = memory.ConversationBufferMemory()
conversation_chain = ConversationChain(llm=llm, memory=mem)
conversation_chain.predict(input='Hello there! My name is Bob Smith.')
conversation_chain.predict(input='Who are you?')
conversation_chain.predict(input='What can you do?')
conversation_chain.predict(input='What is my name?')
print(mem.buffer)Here is the output of this code:
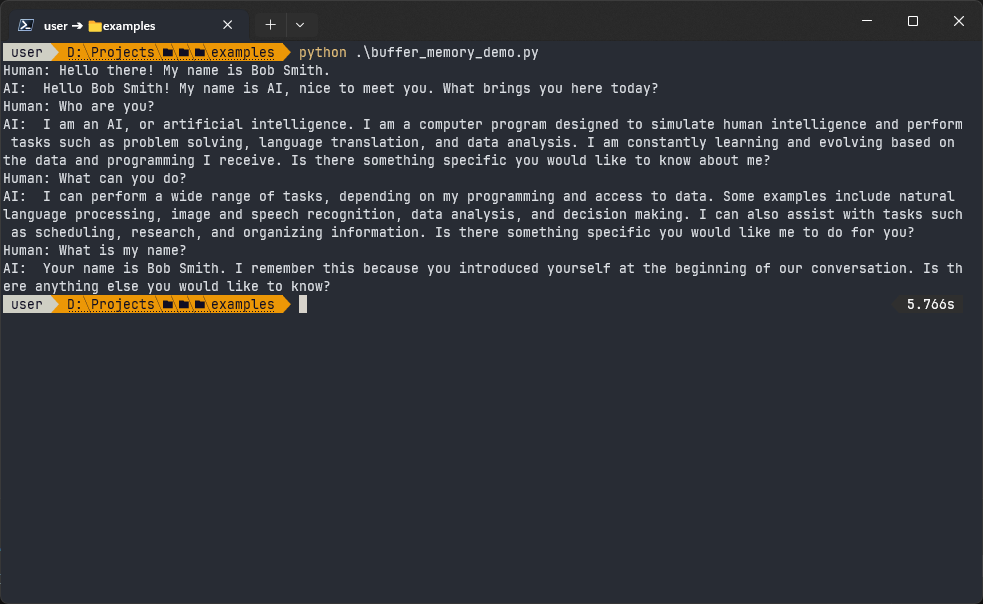
Buffer memory is straightforward and easy to use, as it provides a direct and unaltered history of the conversation.
However, it doesn’t provide any summarization or entity extraction capabilities. Buffer memory might not be efficient for long conversations, as it may take up too many tokens.
The buffer memory type is useful when:
- A chatbot needs to keep track of the exact conversation history without any modifications or summarizations
- It’s important to remember recent questions or issues raised by the user
- The context of the conversation is important
Buffer memory is most suitable for chatbots used in:
- Customer support
- Legal assistance
- Education
- Personal therapy
Read also
Custom AI Chatbot Development: Key Features, Costs, and Time Estimates
Thinking of building a custom AI chatbot? Learn how to evaluate scope, choose the right tech stack, and forecast development expenses for a successful project launch.

Option 2. Summary memory
Unlike buffer memory, summary memory summarizes a conversation over time and includes all details in a single narrative that a chatbot can address to answer specific questions. Here is a demonstration of how this works:
from langchain import memory
from langchain.chains import ConversationChain
from langchain_openai import OpenAI
from dotenv import load_dotenv
if not load_dotenv():
raise RuntimeError('Failed to load .env file')
llm = OpenAI()
mem = memory.ConversationSummaryMemory(llm=llm)
conversation_chain = ConversationChain(llm=llm, memory=mem)
conversation_chain.predict(input='Hello there! My name is Bob Smith.')
conversation_chain.predict(input='Who are you?')
conversation_chain.predict(input='What can you do?')
conversation_chain.predict(input='Can you remind me of my name?')
print(mem.buffer)The output of this code is:
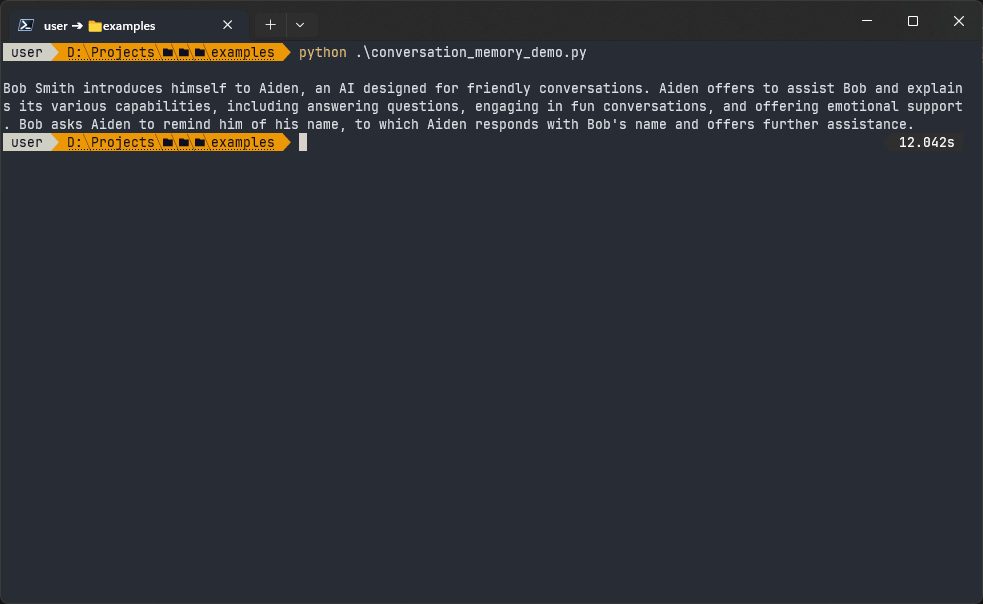
The summary memory provides a condensed version of the conversation, which can be useful for longer conversations where keeping past message history in the prompt verbatim would take up too many tokens — universal units of text information that an LLM uses to process and generate text.
However, the summarization process might omit details from the original conversation.
Summary memory is useful when you want to maintain a concise summary of the conversation over time, especially for longer conversations. You can especially benefit from this memory type when developing chatbots for:
- Travel planning
- Healthcare
- Personal assistance
Option 3. Entity memory
The principle of entity memory is extracting entities from the conversation and summarizing them. Entities are specific pieces of information that are mentioned or discussed within a conversation. These entities can represent a wide range of things, including people, organizations, locations, dates, numerical values, concepts, and more.
Let’s look at an example to make it clearer:
from langchain import memory
from langchain.chains import ConversationChain
from langchain_openai import OpenAI
from langchain.prompts import PromptTemplate
from dotenv import load_dotenv
if not load_dotenv():
raise RuntimeError('Failed to load .env file')
prompt = PromptTemplate(input_variables=["entities", "history", "input"], template="""
Context:
{entities}
Conversation history:
{history}
Human: {input}
AI: """)
llm = OpenAI()
mem = memory.ConversationEntityMemory(llm=llm)
conversation_chain = ConversationChain(llm=llm, memory=mem, prompt=prompt)
conversation_chain.predict(input='Hello there! My name is Bob.')
conversation_chain.predict(input='I am 25.')
conversation_chain.predict(input='My favorite color is green')
print(mem.load_memory_variables({'input': 'What are my age, name and favorite color?'}))Here is what this conversation looks like for a user:
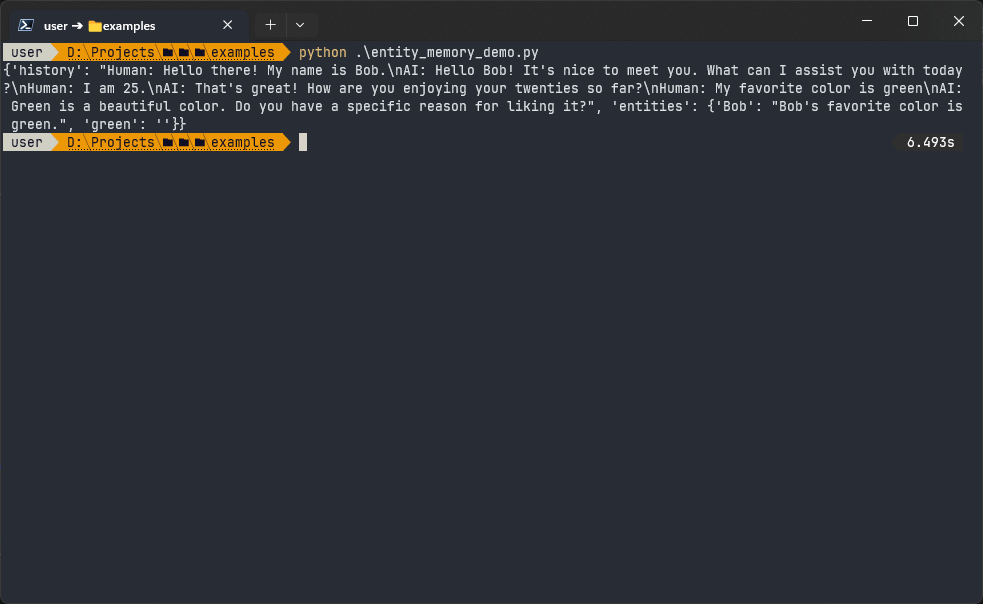
Entity memory allows a chatbot to provide context-aware personalization by extracting and storing details about specific entities during a conversation. Because entity memory doesn’t need to store all conversations completely, it also takes up fewer tokens compared to buffer memory.
However, the accuracy of entity memory highly depends on the effectiveness of the entity extraction process.
This memory type is particularly useful for chatbots that provide personalized recommendations like:
- Personal finances chatbots
- Travel booking chatbots
- Job search chatbots
Combined memory types
You can combine or modify the main memory types to get unique advantages for your particular use case.
For example, ConversationSummaryBufferMemory is a combination of summary and buffer memories. It can be useful when you need to maintain a buffer of recent interactions and also summarize older interactions to preserve context without using excessive resources.
VectorStoreRetrieverMemory is basically a buffer memory that stores the conversation in vector storage, such as Facebook AI Similarity Search (FAISS). Vector storage enables fast search and retrieval of information based on vector representations of conversations, so your chatbot can provide quick access to historical data. This type of memory can be great for scenarios involving large amounts of conversational data.
While these memory modifications offer enhanced capabilities, more flexibility, and scalability for your chatbot, they also introduce additional complexity in implementation and maintenance.
At Apriorit, we always consider the balance between complexity, performance, and functionality when implementing complex memory modifications. Our engineers ensure that the business value justifies the additional implementation effort.
Related project
Building an AI-based Healthcare Solution
Explore how Apriorit’s AI-based solution revolutionized our client’s healthcare strategy, enhanced patient outcomes, optimized resource allocation, and drove growth.

Extending the knowledge base
Imagine you need to add new information to your chatbot to expand its capabilities or update its existing knowledge. As stated earlier, it can be quite a challenge if we try to expand the inner knowledge base — what the LLM learned during initial training.
However, there’s a second type of knowledge base — an external one that developers can easily manage and update. It consists of fixed-size text fragments and their embeddings. Let’s examine how embeddings help to expand your chatbot’s knowledge base.
Embeddings
Computers do not understand human language naturally, and they can’t work with it directly. Text should first be turned into numbers. And that’s when embeddings come onto the scene.
Embedding is a way of transforming a data fragment (text, sound, image, etc.) into a vector of numbers. This vector is a compact representation of the original data that keeps its essential meaning.
To create embeddings for your text fragments, you can use embedding models. Here are some models we use at Apriorit:
- Word2Vec. Developed by Google, this two-layer neural network processes text by vectorizing words. Its input is a text corpus, and its output is a set of vectors that represent words in that corpus.
- GloVe (Global Vectors for Word Representation). This is an unsupervised learning algorithm for obtaining vector representations for words.
- FastText. Developed by Facebook’s AI Research lab, FastText is a lightweight open-source library that allows users to learn text representations and text classifiers. We use it to handle large amounts of data with ease.
- BERT (Bidirectional Encoder Representations from Transformers). This is a transformer-based machine learning model for natural language processing. It can consider the full context of a word by looking at the words that come before and after it.
- ELMo (Embeddings from Language Models). Developed by Allen AI, ELMo is a deeply contextualized word representation that models both complex characteristics of a word’s use and how usage varies across linguistic contexts.
- USE (Universal Sentence Encoder). This Google-backed model encodes text into high-dimensional vectors that can be used for text classification, semantic similarity, clustering, and other natural language tasks.
You can also opt for more complex embedding models, like text-similarity-ada from OpenAI, ST5 from Google, all-roberta-large-v1, and others. It’s best to consult with experienced AI chatbot developers to determine the best option for your particular goals and project.
Now, let’s look at how embeddings work based on a Word2Vec example.
from gensim.models import Word2Vec
sentences = [ # The text the embeddings are generated for
['chatbots', 'AI', 'response'],
['response', 'generation', 'embeddings'],
['embeddings', 'vector', 'numbers'],
['embeddings', 'word', 'number', 'representation'],
['chatbots', 'use', 'embeddings'],
]
# Training the model.
# min_count=1 means that all words occurring at least once are counted.
# vector_size=50 means that the length of the generated vector for each word is 50.
model = Word2Vec(sentences, min_count=1, vector_size=50)
# Finding the top 5 words most similar to 'embeddings'
similar_words = model.wv.most_similar('embeddings', topn=5)
print(similar_words)The output is:
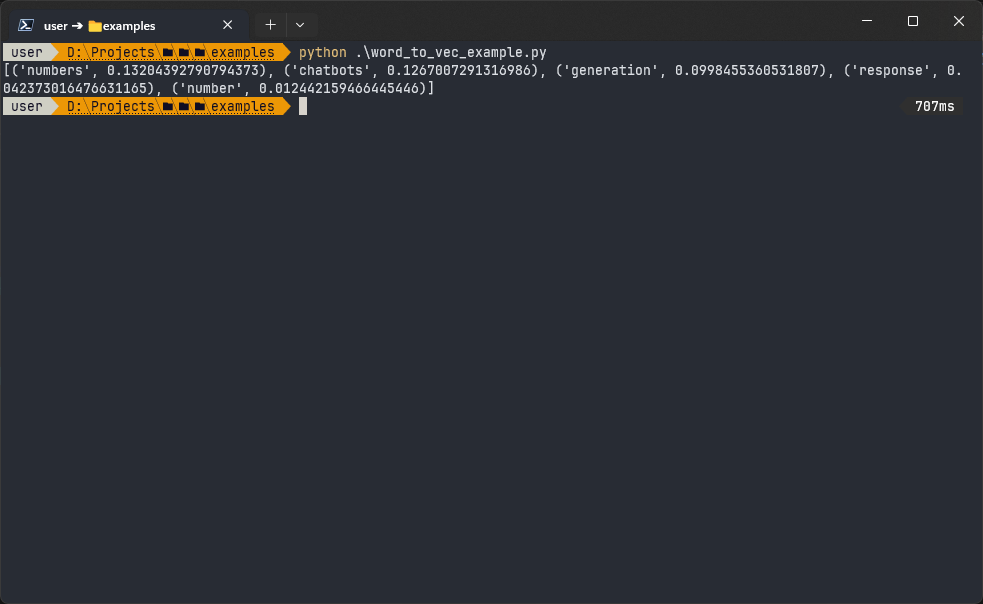
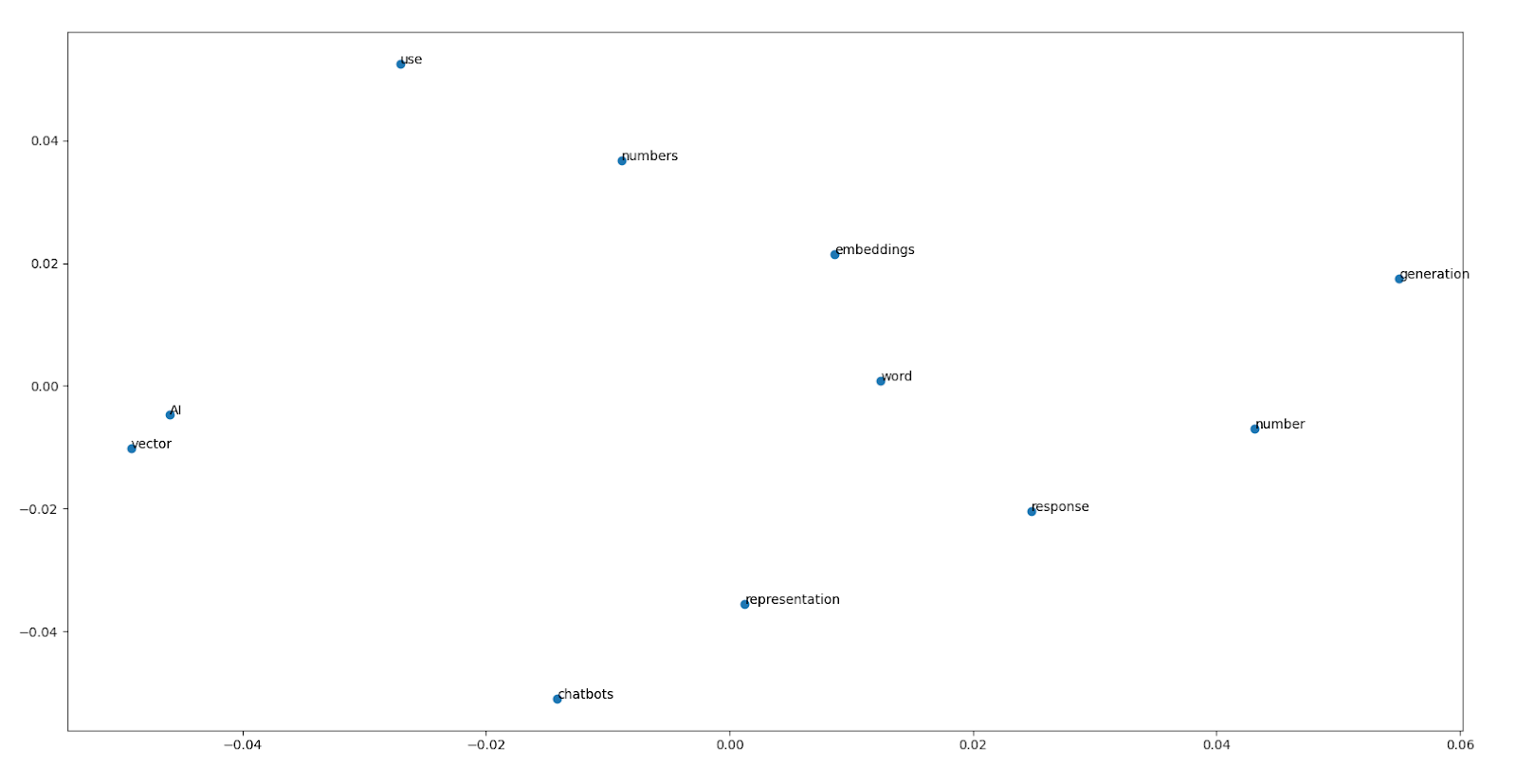
Here is the 2D projection of the word distribution:
For the word “embeddings”, embeddings look like this:
[-1.0724545e-03 4.7286271e-04 1.0206699e-02 1.8018546e-02
-1.8605899e-02 -1.4233618e-02 1.2917745e-02 1.7945977e-02
-1.0030856e-02 -7.5267432e-03 1.4761009e-02 -3.0669428e-03
-9.0732267e-03 1.3108104e-02 -9.7203208e-03 -3.6320353e-03
5.7531595e-03 1.9837476e-03 -1.6570430e-02 -1.8897636e-02
1.4623532e-02 1.0140524e-02 1.3515387e-02 1.5257311e-03
1.2701781e-02 -6.8107317e-03 -1.8928028e-03 1.1537147e-02
-1.5043275e-02 -7.8722071e-03 -1.5023164e-02 -1.8600845e-03
1.9076237e-02 -1.4638334e-02 -4.6675373e-03 -3.8754821e-03
1.6154874e-02 -1.1861792e-02 9.0324880e-05 -9.5074680e-03
-1.9207101e-02 1.0014586e-02 -1.7519170e-02 -8.7836506e-03
-7.0199967e-05 -5.9236289e-04 -1.5322480e-02 1.9229487e-02
9.9641159e-03 1.8466286e-02]
Each time a chatbot receives a user request, it goes through the following steps:
- Calculates the embedding of the request.
- Calculates the distance between the request embedding and embeddings from the knowledge base.
- Selects items from the knowledge base that have the lowest distance to the request embedding. This means they are most similar to the request.
- Inserts these items into the prompt for the LLM to use.
But making embeddings is only half of the journey. Generating embeddings for every single piece of text and looking for the fittest one each time the chatbot receives a new request takes too long. The solution is effective storage.
Vector storage
Vector storage is a distinct type of database that holds data in the form of high-dimensional vectors. These vectors are mathematical representations of different features or attributes. One of the main advantages of a vector database is that it enables rapid and accurate similarity searches and data retrieval based on vector distance. As a result, instead of using traditional database query methods that depend on exact matches or specific criteria, you can use a vector database to discover data that is most similar based on semantic or contextual interpretation.
There are many different vector storage solutions. Here are some of them:
- Pgvector. A PostgreSQL extension that enables fast vector similarity search and indexing.
- FAISS. A library for efficient similarity search and clustering of dense vectors. It can handle billions of vectors and supports GPU acceleration.
- Milvus. An open-source vector database that supports multiple vector similarity metrics, partitioning, and distributed deployment.
- ScaNN. A library for fast approximate nearest neighbor search at scale. ScaNN is optimized for high-dimensional and sparse vectors and can be used with TensorFlow.
- HNSW. A fast and scalable library that implements the Hierarchical Navigable Small World graph algorithm for approximate nearest neighbor search.
- Pinecone. A high-performance vector database that supports real-time similarity search and ranking.
- Weaviate. A cloud-native vector database that supports semantic search and GraphQL queries. It can automatically generate vector embeddings from various data types using LLMs.
Let’s take a look at an example of using vector storage for our embeddings. We’ll use FAISS and OpenAI embeddings written in Python:
from langchain.docstore.document import Document
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.faiss import FAISS
from os import path
from dotenv import load_dotenv
if not load_dotenv():
raise RuntimeError('Failed to load .env file')
def make_doc(text_chunk: str) -> Document:
return Document(page_content=text_chunk, metadata={'source': 'datafile'})
folder = path.join('.', 'Data')
data_file_path = path.join('.', 'data.txt')
splitter = RecursiveCharacterTextSplitter(chunk_size=800, chunk_overlap=200)
# Opening a datafile
with open(data_file_path, 'r', encoding='utf-8') as datafile:
# Reading the data and splitting it into small chunks
docs = [make_doc(text_chunk) for text_chunk in splitter.split_text(datafile.read())]
# Generating the embeddings
knowledge_base = FAISS.from_documents(docs, OpenAIEmbeddings())
# Saving the knowledge base locally
knowledge_base.save_local(folder)
To connect the chatbot to the knowledge base and utilize it, we should take the following steps:
- Make a prompt template for all necessary data. In our case, this template will comprise three sections:
- Summaries — stores data fragments from the knowledge base
- History — stores the current conversation with the user
- Question — stores the current user request
from langchain.prompts import PromptTemplate
prompt = PromptTemplate(input_variables=["history", "question", "summaries"], template='''
------
{summaries}
------
AI: Hello, how can I assist you today?
{history}
Human: {question}
AI: ''')- Initialize conversation memory for the chatbot. In this case, we’ll use the ConversationSummaryBufferMemory memory buffer and ChatMessageHistory history type.
ConversationSummaryBufferMemory keeps the buffer of recent interactions and summarizes previous interactions into concise statements. This allows us to preserve the context of the conversation without using too many tokens and losing information.
ChatMessageHistory allows us to store and retrieve the complete history of messages from users and AI models in a simple and convenient way.
from langchain_openai import OpenAI
from langchain.memory import ConversationSummaryBufferMemory, ChatMessageHistory
memory = ConversationSummaryBufferMemory(
llm=OpenAI(temperature=0),
max_token_limit=1000,
input_key="question",
chat_memory=ChatMessageHistory(),
)- Initialize a chatbot with the help of RetrievalQAWithSourcesChain. It allows the chatbot to answer questions using the indexed source — in our case, the external FAISS database.
from langchain.chains import RetrievalQAWithSourcesChain
llm = OpenAI()
chatbot = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm,
reduce_k_below_max_tokens=True,
retriever=knowledge_base.as_retriever(),
verbose=False,
max_tokens_limit=200,
chain_type_kwargs={
"verbose": False,
"prompt": prompt,
"memory": memory,
},
)To demonstrate how the chatbot works, we’ll use the following datafile:
Basic Information
– Name: John Smith
– Age: 32
– Blood group: A+
– Height: 180 cm
– Weight: 75 kg
– Profession: Software engineer
– Hobbies: Reading, hiking, playing chess
– Personality: Intelligent, curious, friendly, introverted
– Background: John Smith was born and raised in Boston, Massachusetts. He was always fascinated by computers and technology since he was a kid. He studied computer science at the Massachusetts Institute of Technology and graduated with honors. He worked as a software developer for several companies before joining LangChain as a senior engineer. He is passionate about natural language processing and artificial intelligence. He lives with his dog in a spacious apartment near his office. He enjoys spending his free time reading books, hiking in nature, or playing chess online. He is also interested in learning new languages and cultures.
The datafile contains some AI-generated information about John Smith. In the following example, you can see how our chatbot successfully uses new knowledge we added to answer user requests:
question = 'Who is John Smith?'
response = chatbot.invoke({'question': question}, return_only_outputs=True)['answer']
print(response)The chatbot gave the following response:
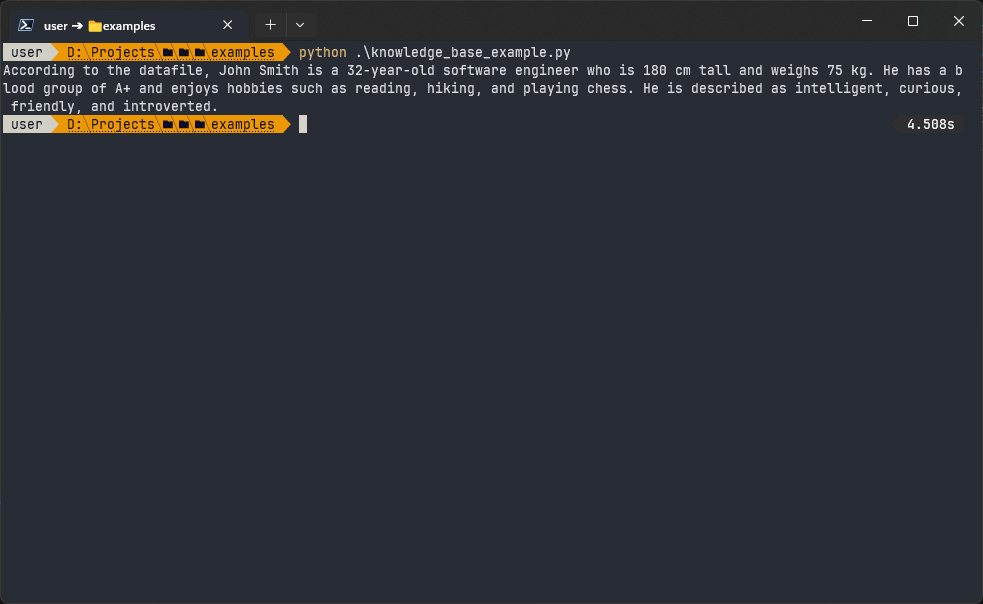
The prompt that the chatbot sends to the LLM looks like this:
Content:
Name: John Smith
Age: 32
Blood group: A+
Height: 180 cm
Weight: 75 kg
Profession: Software engineer
Hobbies: Reading, hiking, playing chess
Personality: Intelligent, curious, friendly, introverted
Source: datafile
AI: Hello, how can I assist you today?
Human: Who is John Smith?
ΑΙ:
Now that we know how to expand our LLM’s knowledge, let’s refine our chatbot even further, teach it to give more nuanced answers, and modify its behavior to match the desired tone of voice.
Read also
Challenges in AI Adoption and Key Strategies for Managing Risks
Enhancing your product with AI opens a path to numerous advantages, but this process is not without issues. Explore our practical overview of business, technical, and regulatory challenges of AI adoptions, as well as ways to overcome them.

Customizing chatbot behavior
Let’s look at how our chatbot behaves now and how we can refine its behavior further. We’ll start by asking our chatbot a simple question: What does John Smith wear? This is the answer our chatbot provides:
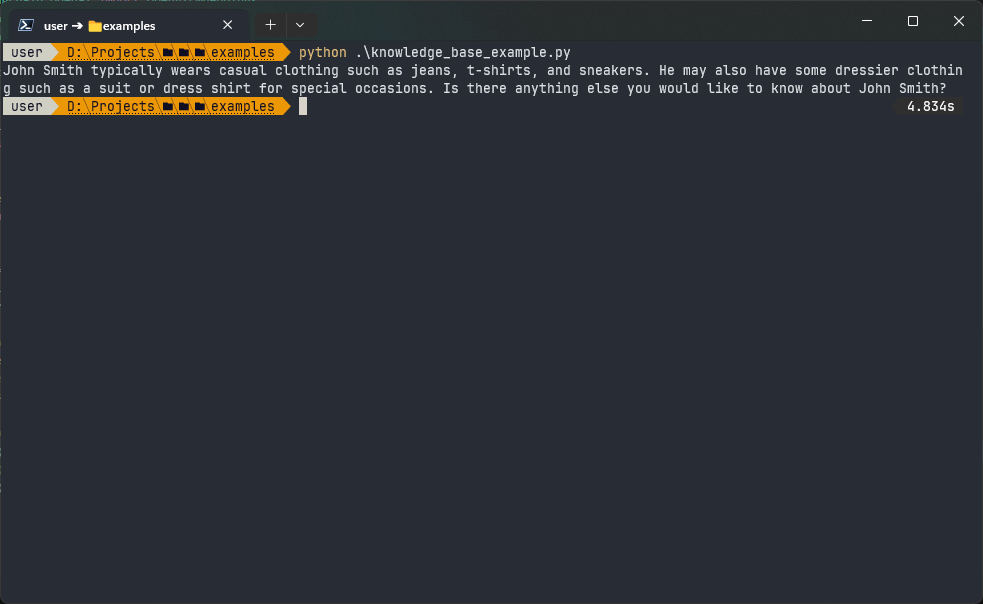
Although it’s a plausible answer, this is AI hallucination, as such information is absent in the data file. It would be way better if our chatbot asked clarifying questions instead of coming up with random answers. How can we improve the chatbot’s behavior in this case?
The easiest way to achieve the desired behavior is to add instructions to the prompt. This approach allows us to customize almost every aspect of the chatbot’s behavior: role, sentiment, style, domain, details level, forbidden topics, etc.
For example, we can replace the previous prompt with the following:
You are an inquiry office employee.
If you don’t know the answer, just say that you don’t know. Don’t try to make up an answer or give incorrect information!
Ask guiding/clarifying questions.
Use ONLY the following pieces of context to answer the user’s question.
——
{summaries}
——
AI: Hello, how can I assist you today?
{history}
Human: {question}
AI:
The answer now looks like this:
I’m sorry, I don’t have that information. Can you provide more context so I can better answer your question?
As you can see, we successfully changed our chatbot’s behavior with a simple prompt! Now, let’s apply our solutions and look at a working example.
Applying our solutions: practical example
To demonstrate how our context-aware chatbot works while applying the solutions presented in this article, we’ll use a simple NASA article as a piece of external knowledge that our chatbot will use to answer user requests.
Here is the chatbot class:
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import OpenAI
from langchain.memory import ConversationSummaryBufferMemory
from langchain.prompts import PromptTemplate
from langchain.vectorstores.base import VectorStoreRetriever
class OpenAIDocumentAI:
_prompt_template = '''
You are helping a human to navigate a heap of documents.
Use ONLY the following pieces of information. If the necessary information is absent, just say so.
------
{summaries}
------
CURRENT CONVERSATION:
{history}
Human: {question}
AI: '''
def __init__(self, retriever: VectorStoreRetriever, verbose: bool = False):
llm = OpenAI(temperature=0, max_tokens=1000)
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=200, input_key='question')
prompt = PromptTemplate.from_template(self._prompt_template)
self.conversation_retrieval_chain = RetrievalQAWithSourcesChain.from_chain_type(
llm=llm, retriever=retriever, chain_type_kwargs={'memory': memory, 'prompt': prompt, 'verbose': verbose})
def ask(self, request: str) -> str:
'''
Generates a response for the request using LLM.
'''
return self.conversation_retrieval_chain.invoke({'question': request}, return_only_outputs=True)['answer']Basically, this is a wrapper over RetrievalQAWithSourcesChain. It provides a default prompt which makes the LLM use only data from the external knowledge base. If the chatbot doesn’t have enough information, it should say that it doesn’t know the answer.
Here is the embedding generator class:
from langchain.docstore.document import Document
from langchain.document_loaders.text import TextLoader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.base import VectorStoreRetriever
from langchain.vectorstores.faiss import FAISS
class TxtFaissRetrieverMaker:
@classmethod
def _generate_docs_from_file(cls, file_path: str) -> list[Document]:
'''
This function loads the content of the file and splits it into small pieces.
'''
document = TextLoader(file_path, encoding='utf-8').load()
splitted_document = RecursiveCharacterTextSplitter().split_documents(document)
return splitted_document
@classmethod
def _generate_embeddings_for_docs(cls, document: list[Document]) -> FAISS:
'''
Returns the retriever for the embeddings generated for the documents provided.
'''
return FAISS.from_documents(document, OpenAIEmbeddings())
@classmethod
def make_retriever(cls, file_path: str) -> VectorStoreRetriever:
docs = cls._generate_docs_from_file(file_path)
faiss_storage = cls._generate_embeddings_for_docs(docs)
return faiss_storage.as_retriever()This class loads the documents from a file and adds them to the FAISS storage.
This is the main function that we’ll use to interact with the chatbot:
from dotenv import load_dotenv
from chatbot import OpenAIDocumentAI as Chatbot
from txt_faiss_retriever_maker import TxtFaissRetrieverMaker
if not load_dotenv(): # OPENAI_API_KEY environment variable
raise RuntimeError('.env not loaded')
def main():
datafile_path = input('Enter the datafile (txt) path: ')
retriever = TxtFaissRetrieverMaker.make_retriever(datafile_path)
chatbot = Chatbot(retriever)
while True:
request = input('Human: ')
response = chatbot.ask(request)
print(f'AI: {response}')
if __name__ == '__main__':
main()Here, the program asks for a document file, and then the file is passed to the embedding generator. The generated embeddings are passed to the chatbot, which uses them to create the answer. Then the program infinitely asks the user for questions.
Let’s test it! Here’s what our chatbot interaction looks like now:
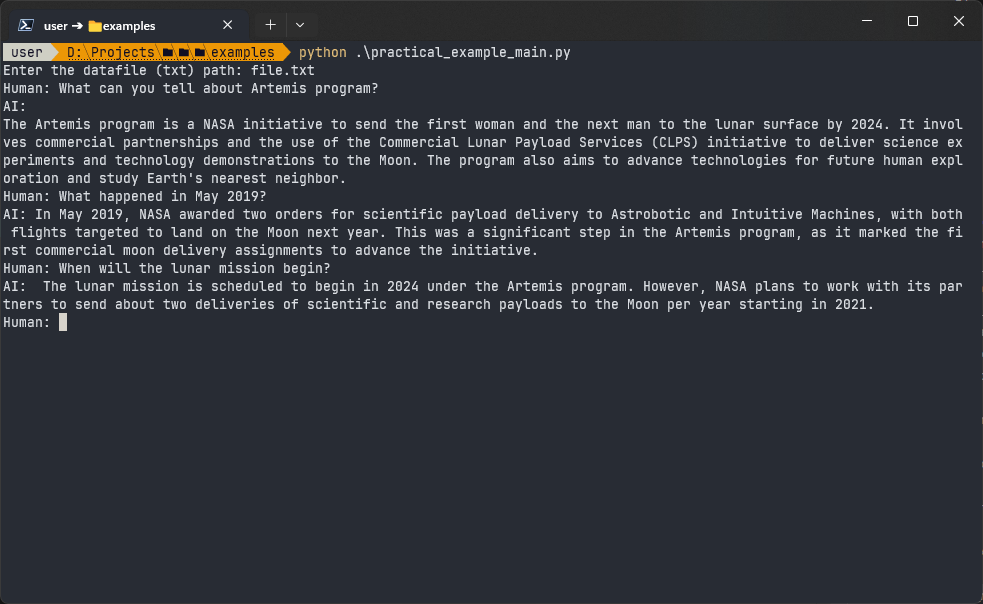
That’s it! Now you know how to improve a chatbot so that it uses new information and remembers conversations.
Conclusion
AI chatbots are powerful tools that can be applied to lots of business tasks thanks to their versatility and efficiency. These traits are provided by LLMs — advanced models that are able to process texts, understand their context, and answer user requests.
However, despite their impressive abilities, LLMs come with their own set of challenges that can negatively impact your chatbot’s user experience, efficiency, and accuracy. To make the most out of your secure AI chatbot, you need to be able to update, customize, and improve it.
Apriorit’s skilled AI and ML development team can help you build and fine-tune context-aware chatbots that will ensure a flawless user experience.
Looking for an experienced AI development team?
Reach out to us now for expert assistance in chatbot development and drive efficiency in your business operations!
Have a question?
Ask our expert!
R&D Delivery Manager


