 Skip to main content
Skip to main content
Data is the new oil for modern businesses: using it correctly can fuel your company’s growth and help you get ahead of the competition. Much like oil, data is also useless when raw and undiscovered. At best, your business won’t be able to benefit from it; at worst, it can cause a security incident. That’s why organizations invest in sensitive data discovery and protection solutions.
Traditional data discovery tools are powered by data scanners and rule-based algorithms, which are often not enough to get on top of an ever-growing stream of new data. Therefore, many organizations enhance their data discovery and protection solutions with artificial intelligence (AI).
In this article, we discuss the key drawbacks of rule-based systems and the benefits of using AI to discover and protect sensitive data. We also explore how a typical data discovery and protection solution works and share development tips from Apriorit’s experience.
This article will be useful for CIOs and cybersecurity specialists who are looking for ways to enhance and automate the protection of their data and products.
Contents:
- How does sensitive data discovery influence an organization’s security?
- Why are traditional data discovery tools not enough?
- Why use AI for data discovery and protection?
- How do AI data discovery and protection tools work?
- How to address key challenges of AI-powered data discovery: Apriorit’s take
- Conclusion
How does sensitive data discovery influence an organization’s security?
Keeping sensitive data in one secured storage location seems like an easy task, but it is in fact nearly impossible for many organizations. Transitioning to remote or hybrid work during the COVID-19 pandemic, migrating on-premises environments to the cloud, or going through a merger and acquisition process can result in sensitive data being stored in the most unobvious places. Such data slips under the radar of cybersecurity solutions and increases the risk of a data leak or security incident.
Data stored outside of an organization’s control and security boundaries creates a risk of a security incident like data theft or a data leak. That’s why organizations invest in sensitive data discovery software — the tools for detecting, identifying, and organizing records across all organizational resources and environments.
Implementing such a solution can allow businesses to:
- Ensure compliance with cybersecurity laws
- Prevent data theft and leaks
- Make data-driven cybersecurity improvements
- Improve data management efficiency
The growing need to control sensitive data across diverse environments and infrastructure has led to the growing popularity of software for data discovery. In fact, the global sensitive data discovery market is expected to grow from $5.1 billion in 2020 to $12.4 billion by 2026.
Sensitive data protection discovery and tools are especially relevant for organizations that predominantly work with sensitive information in industries such as:
- FinTech
- Retail & e-commerce
- Healthcare
- Insurance
- Transportation & logistics
- Human resources & customer service
- Software development
However, traditional data discovery solutions can’t always keep up with the speed at which modern companies generate new records. Let’s examine the key weaknesses and limitations of such tools.
Need to get your sensitive data under control?
Get a custom solution suited to your IT environment and business needs. Collaborate with Apriorit experts in data management, cybersecurity, and AI development for the best results.
Why are traditional data discovery tools not enough?
While dedicated tools for data discovery and protection provide lots of business benefits, they can be challenging to manage and integrate into an existing corporate system.
Here are the key drawbacks of rule-based data discovery:
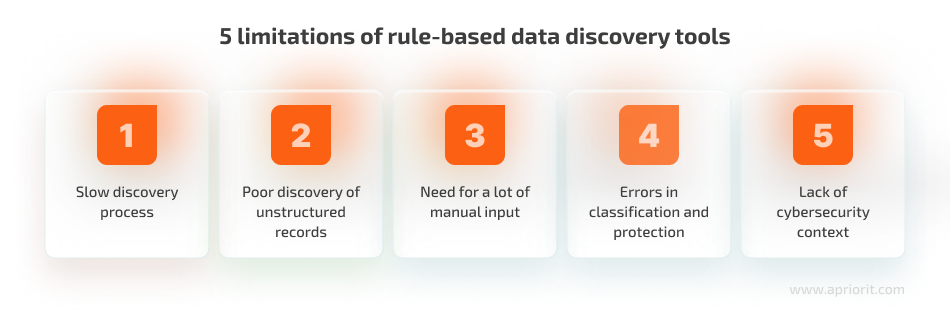
1. Slow discovery process. Rule-based systems typically rely on database and storage scanners to discover new records. They take a lot of time to analyze storage instances they are integrated into because they have to scan them one by one. If you add a new record during a scan, the tool won’t discover it until it finishes the current scan and starts a new one. Also, a scanner has to examine all records during each scan, including those that didn’t change since the previous scan.
2. Poor discovery of unstructured records. It’s easy for a rule-based tool to discover sensitive records in structured data sources like databases, logs, and spreadsheets. When it comes to unstructured data sources (emails, text documents, social media), the accuracy of discovery drops significantly because unstructured records are scattered and inconsistent. Scanning such data sources with a non-AI solution often provides unreliable and incomplete findings, which is especially significant considering that around 90% of data generated by businesses is unstructured.
3. Need for a lot of manual input. To successfully use rule-based systems, your team has to perform lots of manual activities: set configurations, specify scanning and classification rules and regular expressions, review the results, and so on. Having a lot of manual input increases the chances of introducing human errors. Using a rule-based system also doesn’t eliminate the need for manual discovery of data that the system simply cannot recognize (such as unstructured records discussed above).
4. Errors in classification and protection. When data isn’t correctly and wholly discovered, it’s challenging for any tool to classify it: determine the type of sensitive records, calculate a risk score, and assign required cybersecurity measures. Incorrect classification of sensitive data can leave records unprotected, leading to data theft and compliance violations.
5. Lack of cybersecurity context. Rule-based systems collect a limited amount of data about data discovery. Usually, they are limited by the type of discovered data and its location. To examine a tool’s discovery and classification performance, a cybersecurity specialist has to manually assess new records and collect the missing context before making a final decision.
These limitations stem from the core algorithms of rule-based systems, which is why even seasoned developers and system administrators struggle to overcome them. Using such systems is beneficial for organizations that have relatively small amounts of storage space, don’t create tons of data each day, and have available IT resources to manage the discovery process.
If you have strict cybersecurity requirements and need more context for data discovery and protection, consider choosing AI-based tools. Adopting a robust AI-based system covers many business needs in terms of the protection of sensitive data and cybersecurity compliance. Let’s examine the benefits of using such a system compared to traditional rule-based data discovery.
Related project
Supporting and Improving Legacy Data Management Software
Explore how we helped our client improve and maintain their custom solution for sensitive data management. Migrating from a now deprecated operating system allowed them to prevent multiple cybersecurity risks and will permit smooth integration of new features in the future.

Why use AI for data discovery and protection?
Using artificial intelligence for data discovery and protection can significantly improve the accuracy and reliability of data discovery and protection solutions. Your team can use various AI models and technologies during data discovery to gain the following advantages:
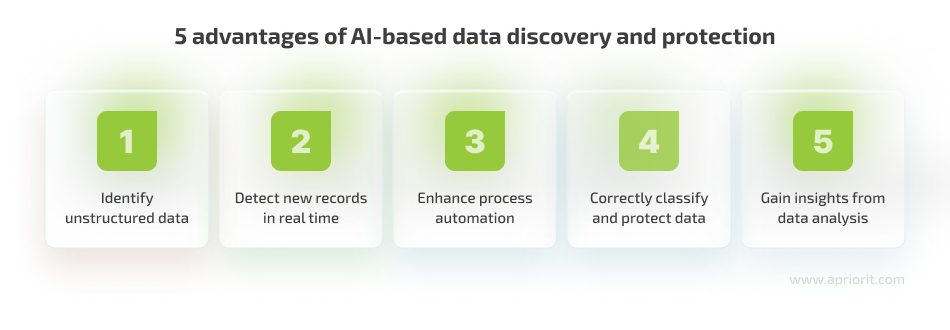
1. Identify unstructured data. Unlike a rule-based system, an AI-based solution can recognize sensitive records in both structured and unstructured data. With large language models (LLMs) and natural language processing (NLP), such a solution can detect sensitive information in correspondence, chat logs, text files, and other sources that can’t be fully defined by rules. Analysis of unstructured data makes an AI-powered sensitive data discovery tool reliable and contributes to your organization’s overall cybersecurity posture.
2. Detect new records in real time. AI algorithms don’t need to iteratively scan available environments to discover new data. Instead, they can analyze new and edited records, significantly speeding up detection and avoiding bottlenecks. Some sensitive data discovery tools use both rule-based scanning for routine data inspection and AI models for more accurate analysis of unstructured records.
3. Enhance process automation. AI-based tools can reliably automate most activities during data discovery, classification, and protection. After the initial configuration, they rarely need manual input and additional tuning. A high level of automation helps organizations speed up data discovery and frees cybersecurity specialists from routine tasks, allowing them to focus on challenges that require their expertise.
4. Correctly classify and protect data. Thanks to the ability to understand the meaning and context of data, AI can accurately classify discovered records in any format in which they’re stored: a table, plain text, communication logs, etc. Correct classification and sensitivity scores allow AI to choose relevant security measures for discovered data, improving an organization’s security posture and complying with relevant security requirements.
5. Gain insights from data analysis. An AI-powered data discovery solution generates and collects a lot of data regarding its work, including the nature and location of new sensitive records, classification results, and common violations of data security policies. Such software can use this data to create dashboards that help security specialists quickly assess and improve discovery and protection processes. The solution can also create automated reports on recent events and the state of data protection posture. These reports are useful for in-depth assessment of an organization’s security and for passing compliance audits.
Using AI for data discovery can take a data discovery solution to a new level and boost your organization’s cybersecurity. However, implementing it in a productive and cost-efficient way requires experience working with AI in the cybersecurity field.
Before we focus on implementing such systems, let’s examine how they work and which AI technologies they usually employ.
Read also
Implementing Artificial Intelligence and Machine Learning in Cybersecurity Solutions
Explore how AI and machine learning algorithms can enhance the automation capabilities and accuracy of cybersecurity products.

How do AI data discovery and protection tools work?
Advanced solutions for data discovery and protection can perform a variety of activities from file scanning to data analytics and risk reporting. Such tools may be fully based on AI algorithms or on rule-based systems with additional AI-powered features.
While each solution has its own killer features and workflow, we can outline the following key stages of data discovery process most AI-based tools go through:
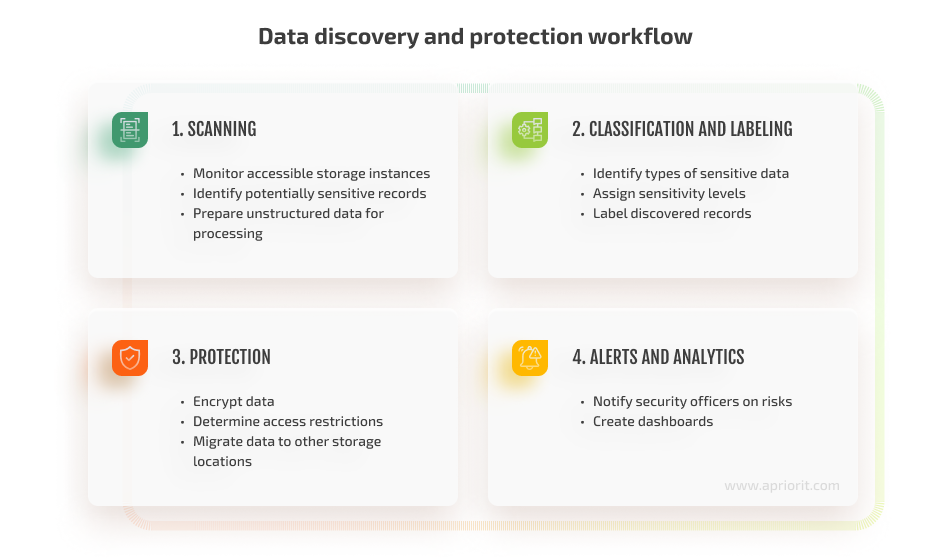
1. Data scanning. An AI solution continuously monitors environments it can access for new data: cloud and on-premises servers, databases, device drives, etc. Administrators of a data discovery and protection solution can configure the types of data it should look for and provide access to instances it should monitor.
Scanning typically consists of these key steps:
- Monitoring accessible storage instances for changes and new records
- Identifying potentially sensitive records
- Preparing unstructured data for processing
When the solution discovers a file with potentially sensitive data, it attempts to classify it.
2. Data classification and labeling. Based on its configuration, software can classify discovered records by:
- Type of sensitive data. The solution can identify personal, financial, or manufacturing data, and intellectual property. Using AI technologies like LLMs and NLP at this stage helps to classify unstructured data with a high level of precision.
- Sensitivity score. The solution can calculate how sensitive discovered records are depending on the nature of data, its location, applied protection measures, and other factors. This score helps the solution decide what to do with the data at later processing stages and when it needs to notify system administrators.
When classification is finished, the solution assigns labels to discovered records. Labels usually include the type of data, the access level required to interact with it, and the level of restriction. Solution administrators can also create custom labels.
3. Protection. The steps data discovery software takes to protect the data it uncovers wholly depend on your organization’s cybersecurity standards and environments, applicable regulations, and so on. Typically, AI-powered software can enforce the following data protection measures:
- Encryption
- Access policies
- Transfer of data to more secure storage
- De-identification and anonymization
- Data masking
4. Alerts and analytics. Apart from continuous discovery and protection processes, such solutions can also use AI algorithms to process data they collect and compile useful dashboards with:
- Current security threats that need to be addressed by administrators
- Risk scores for various data records and storage instances
- Common data protection violations, which may indicate harmful user practices and gaps in security policies
- Inconsistencies between applied protection and compliance requirements
Such data analysis and visualization allows you to detect weak spots in your organization’s protection and improve security policies.
Although data discovery and protection software can work almost completely automatically, cybersecurity specialists have to overview its decisions to ensure sufficient data protection. When such software discovers new records with a high sensitivity score or many security risks, it can notify an administrator. The administrator can then review protection measures assigned by the solution and change them if needed.
Now, let’s take a look at key challenges you can encounter when building a custom AI-based tool for data discovery and protection. We’ll also provide advice on how to tackle these challenges.
Related project
Building AI Text Processing Modules for a Content Management Platform
Explore how we helped an international provider of content management services enhance their platform with AI text processing features. Our cooperation helped the client gain a competitive advantage, improve the user experience, and attract new customers.

How to address key challenges of AI-powered data discovery: Apriorit’s take
Building a custom data discovery and protection tool always comes with challenges that are unique to a client’s organization, needs, and compliance requirements. Apriorit’s business analysts and developers define such challenges during the project’s discovery stage. We then address them during development to make sure that our clients get fitting and secure software.
Relevant data storage integrations. To be able to discover all sensitive data, a tool needs to access and read records across all of an organization’s environments. But adding APIs for all possible cloud and on-premises storage instances takes lots of a developer’s time and can introduce security vulnerabilities. Before starting development, we interview a client’s stakeholders to understand their environment, add only those integrations they need, and secure implemented APIs.
Reliable development components. Using third-party components can significantly speed up the development process, but it also enhances the risk of adding backdoors to your solution. To find the balance between development time and security, we test third-party software and check it using known vulnerability databases before adding it to your solution. If the solution uses commercial language models like GPT or Claude, we can create a private database to train it or deploy the model locally to avoid sharing your data with other companies.
Balanced resource use. As with any AI-based solution, continuous data discovery can be quite resource-hungry, especially if your organization constantly generates a lot of data. This can result in high cloud usage costs or the need to maintain powerful on-premises machines. To avoid spiking development and maintenance costs, we use Agile and DevOps practices, optimize AI performance to eliminate unnecessary operations, and implement flexible scaling mechanisms.
Security configurations. An AI data discovery and protection tool needs to access and manage any records in the environment it manages. These records can be abused by hackers or insiders looking for a way to access your sensitive data and stay unnoticed. Limiting the tool’s security privileges will hinder its efficiency, so instead, we look for a balance between performance and security: configure just-in-time access to records, anonymize data upon discovery, add notifications on data manipulations for administrators, etc.
AI bias. Any AI-based solution inherits bias from its developers and training datasets. For a data discovery and protection solution, such bias can result in incorrect data classification or enforcement of insufficient security measures. The most reliable way to detect AI bias before product release is through extensive testing. At Apriorit, we test how a solution works in different environments with various types of sensitive data and how it alerts users and reports its discoveries. If the solution returns inaccurate results, we conduct additional training to fix the AI’s behavior.
At Apriorit, we nurture expertise in complex software development areas like AI, cybersecurity, and data management. With experience building custom solutions for clients from highly regulated industries, we can outline key development challenges early and offer ways to overcome them.
Conclusion
Data discovery and protection tools are an essential part of cybersecurity for any organization, as they create a foundation for reliable data security and management. Such tools uncover sensitive data across any cloud, on-premises, and hybrid infrastructure and enforce cybersecurity measures according to an organization’s policies and compliance requirements.
Enhancing data discovery and protection with AI takes such solutions to a new level. Compared to rule-based systems, AI can discover and classify unstructured data, makes fewer mistakes, doesn’t require a lot of manual input, and gathers data for future security improvements.
To build an AI-powered data discovery solution and securely deploy it, you’ll need to engage experts in cybersecurity, AI development, and data management. Apriorit experts will gladly assist you with defining requirements and building a custom data discovery solution that fits your organization’s needs.
Looking for a reliable development partner?
Enhance the security of your sensitive data by leveraging Apriorit’s cybersecurity expertise and development skills.
Have a question?
Ask our expert!
R&D Delivery Manager


